


Donanım Sürücülerin Analizi:
Bugüne kadar yaşadığım problemlerin büyük bölümü ya Windows Update eksikliğinden ya da kullanılan donanım sürücüsünün bir bugına denk gelmektendir. Bu nedenle düzenli donanım güncellemeleri takip edilmelidir.
Fakat burada donanım bileşenlerini güncellerken ilişkili servis ve bileşenlerin matris tablosundan karşılıklı doğrulama yapılması gerekmektedir. Örnek vermek gerekirse; HBA firmware ve driver seviyeleri Storage üreticisine göre değişiklik arz etmektedir. Bu nedenle HBA kartınız ve işletim sisteminize göre Storageinizin desteklediği sürüm matristen kontrol edilerek yapılmalı.
Sunucu üretici firmaları bazen güncel donanım bileşenlerini kendi bünyesinde devam etmeyebilir. Bu durumda donanım üretici firmasında çift taraflı kontrol yapılması gerekmektedir.
Perfmon Analizi:
Yaşayan sistemlerin en büyük sıkıntısı bir süre sonra kabına sığmamaya başlaması ve performans sorunlarından dolayı kullanıcı şikâyetlerinin artmasıdır. Bu nedenle şirketinizin yapısına göre yoğun zamanlarda alınacak performans değerlerinin analizi ile müşteri şikâyetleri gelmeden darboğazları görmenizi sağlayacaktır. Clusterın olmazsa olmaz 3 temel bileşeni vardır. Bunlar; shared Disk, Network ve Quorum.
Al******** Unit Size:
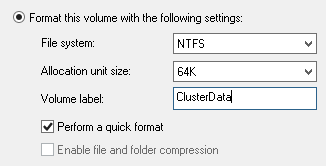
Mekanik disklerin en büyük problemi kafa hareketinden dolayı verinin okuma ve yazma performans kaybıdır. Eğer disk üzerinde tuttuğunuz verileriniz SQL database dosyaları ve Hyper-V sanal sunucu diskleri gibi büyük blok alan kaplıyorsa kullanılan disklerin Al******** unit size değeri 64K olmalı. Bu size bir veri yazılırken veya okunurken disk kafasının çok fazla hareket etmesini engeller.
Eğer SQL ve Hyper-V için kullanılan diskleriniz varsa bunların Al******** unit size değerini kontrol için aşağıdaki PowerShell komutunu çalıştırılıp 65536 değerinin çıktığı gözlenmeli.
$ComputerName = '.'
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='NTFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='NTFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
$ComputerName = '.'
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='CSVFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='CSVFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
Eğer 65536 değerinden küçük bir değer dönerse SQL veya sanal sunucunun stop edilip disk içindeki verilerin taşınıp diskin yeniden 64K olarak yeniden formatlandıktan sonra veriler geri taşınır.
Disk Performans Değerleri:
SQL, File Server ve Hyper-V sistemleri en fazla 20 mili saniye diskte gecikmeye tahammülü vardır. Bu nedenle AVG disk sec/Read ve AVG disk sec/Write perfmon değerleri hem TOTAL hem de disk bazlı oluşturulup incelenir. Detaylı bilgi için aşağıda linki verilen Serhat Akıncı hocamın makalesinden faydalanabilirsiniz.
http://www.cozumpark.com/blogs/virtualization/archive/2014/01/12/hyper-v-altyapisinda-olusan-darbogazlari-yakalayin.aspx
Disk işlemlerinde bottleneck olup olmadığın tespiti için her bir disk için perfmon üzerinde Avg Disk Queue Lenght değeri toplanmalı. Ortalama değer volümü oluşturan disk sayısına bölünerek çıkan sonuç 2den büyük olmamalıdır. Mesela 10 disk ile yapılmış Raid Arrayınız varsa ortalama değer 10 ise Avg Disk Queue Lenght değeri 1dir.
http://www.sqlshack.com/sql-server-disk-performance-metrics-part-2-important-disk-performance-measures/
Disk Gecikme Problemlerinin Çözümü:
Genel olarak bu problemin 2 temel çözümü vardır. Ya Sunucu ve storage donanım sürücüleri ve işletim sistemi güncel değildir. Ya da storagede bottleneck vardır. Eğer storagede bottleneck varsa disk poolunu arttırarak veya araya SSD diskler koyarak sorunu çözebilirsiniz.
Bazen raid tipinin üzerinde çalışan servise göre düzgün oluşturulmadığından da bu sorun yaşanabilir. Mesela SQL ve Hyper-V için önerilen RAID10 kullanmaktadır. Eğer siz Raid1 veya Raid5 olarak yapılandırmışsanız bu alt taraftaki disklerin düzgün kullanılmamasına neden olacağından performans problemine neden olabilir.
Network Performans Değerleri:
Clusterın olmazsa olmaz parçalarından olan Networkteki en ufak bir problem veya performans kaybı büyük sorunlara neden olabilir. Network probleminin tespiti için aktif Cluster nodeu üzerinden hem TOTAL hem de her network kartı için alınan Packets Received Discarded ve Packet Outbound Error perfmon verilerinde 0 veya sıfıra yakın değer olmalı. Eğer 10un üzerinde ise Network portunda veya Switchde problem olduğunu göstermektedir.
Network Gecikme Problemlerinin Çözümü:
Eğer Packets Received Discarded ve Packet Outbound Error değerinde çok büyük rakamlar görüyorsanız bantwith değerlerinin de incelenmesinde fayda var. Eğer bantwith değerleri yüksek ise NICTeaming ile bantwith kullanımı arttırınız.
Bantwith artmış olmasına rağmen Packets Received Discarded ve Packet Outbound Error sıfıra yakın değer almadı ise driverda güncel ise switch tarafına bakılması gerekiyor.
İşletim Sisteminin Analizi:
Cluster Nodelarımızın işletim sistemi seviyesinde gerekli kontrollerin yapılması gerekmektedir. Bilerek veya bilmeyerek veya test amaçlı yapılan değişikliklerin geri alınmamasından dolayı en başta performans problemlerine neden olabilir. Bazen de hizmet kesintilerine neden olabilir. Bunun için bazı genel kontrollerin düzenli olarak gözle kontrol edilmesinde fayda bulunmaktadır.
Event Viewer Kontrol:
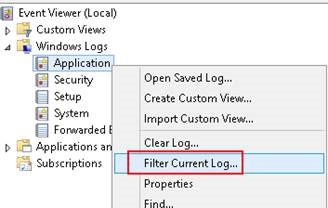
Aslında düzenli olarak Application ve System event loglarının incelenmesi gerekiyor. Bunu yaparken öncelikli olarak kritik değerlere bakılmasında fayda bulunmaktadır. Eğer bir sorun tespit ederseniz ilgili zamandaki diğer eventlar ile birleştirerek genel inceleme yapılabilir.
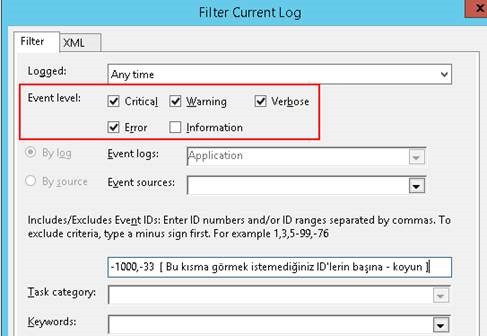
Event Viewer üzerinde filtreleme yapmak için sağ tıklanıp Filter Current Log tıklanıp açılan ekranda Warning, Critical, Error ve Verbose seçilir.
Eğer bildiğiniz ve listelenmesini istemediğiniz eventlar var ise Includes/Excludes Event ID kısmına başına koyarak yazınız. Özellikle listelenmesini istediğiniz event varsa araya virgül koyarak yazınız.
MultiPath I/O:
Bu servis verinin birden fazla kanaldan giderken tekil yönetimini gerçekleştirmesini sağlamaktadır. Bu nedenle eğer NIC Teaming veya birden fazla HBA portu kullanıyorsanız Multipath Featureı kurulur.
Bare ****l Recovery:
Aşağıdaki linkte detaylarını bulacağınız makalede belirtildiği gibi işletim sistemi ve Cluster tarafta yaşanacak olası problemlerde bazen yedekten dönülmeye gerek duyula biliyor. Bu nedenle belli zaman aralıklarında sisteminizin Bare ****l Recovery yedeğinin alınıyor olması gerekmektedir.
http://www.cozumpark.com/blogs/windows_server/archive/2014/06/15/microsoft-cluster-server-disaster-recovery-options-microsoft-failover-cluster-servis-kurtarma-yontemleri.aspx
Anti Virüs Ayarları:
Cluster sisteminde baş ağrıtacak servislerin/uygulamaların başında anti virüs yazılımları gelmektedir. Bu nedenle anti virüs yazılımınız yönetilebilir ve Windows Server için üretilmiş olmalıdır. Bununla birlikte Anti virüs için Microsoftun önerdiği exculution ayarlarının yapıldığı kontrol edilmeli. Bu kontrol için aşağıdaki referans adresler kontrol edilebilir.
Windows: http://support.microsoft.com/kb/822158
Cluster: http://support.microsoft.com/kb/250355
Network Tunning:
Print Server, RDS, File Server, SQL, IIS, Exchange ve Hyper-V sunucularında yoğun network işlemleri olduğundan paket kayıtlarına veya gecikmelerine neden olabilir. Çözüm için dinamik port sayısının ve Delay süresinin arttırılması gerekmektedir. Dinamik maksimum port sayısının tespiti için aşağıdaki komut çalıştırılır.
Netsh int ipv4 show dynamicport udp
Netsh int ipv4 show dynamicport tcp
Eğer sonuç 64000den küçük ise aşağıdaki komut çalıştırılır.
netsh int ipv4 set dynamicport tcp start=1025 num=64510
netsh int ipv4 set dynamicport udp start=1025 num=64510
Administrator ile çalıştırılmış regedit ile Registera aşağıdaki değerleri ekleyin.
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters]
"TcpTimedWaitDelay"=dword:00000030
"MaxUserPort"=dword:0000fffe
CPU Tunning:
Eğer sunucularınız 24 core CPUdan fazla ise uygulamalarınızın CPU çekirdeklerini tam olarak kullanabilmesi için BCDEDITde usephysicaldestination aktif edilmeli. Bunun kontrolü için komut satırında bcdedit yazıp enterlayın. Çıkan sonuçta usephysicaldestination görmüyorsanız aşağıdaki komutu çalıştırın.
bcdedit /set usephysicaldestination yes
DISK Tunning:
SQL ve Hyper-V sunucularında Task Scheduler da Defrag işleminin kapalı olması gerekiyor.

Redirectionın Kapatılması:
Cluster sistemlerinde en çok baş ağrıtan noktalardan birisi Redirection işlemleridir. Bu aşamada sunucularda olası problemlerin önlenmesi için uzak bağlantı ile gelen port ve printer yönlendirmelerinin kapatılması gerekmektedir. Aşağıda linkini verdiğim makalede detayları anlatılmıştır.
http://www.cozumpark.com/blogs/windows_server/archive/2014/12/28/windows-server-2012-r2-cluster-ortamlarinin-hazirlanmasi.aspx
NMI Crash Dump:
İşletim sistemi cevap veremeyip siyah ekranda kaldığında sunucu donanıma ait uzak bağlantı konsolundan memory dump alınarak restart edilmesi için OSe gelen NMI isteklerinin kabul edilmesi gerekmektedir. Bu işlem için registerda aşağıdaki parametreler kontrol edilir. Eğer değer 1 değil ise yapılır.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\CrashControl altına NMICrashDump isimli yeni bir DWORD oluşturulup değeri 1 yapılır
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\WHEA\Policy altına NMICrashDump isimli yeni bir DWORD oluşturulup değeri 1 yapılır
Page Fileın Ayarlanması:
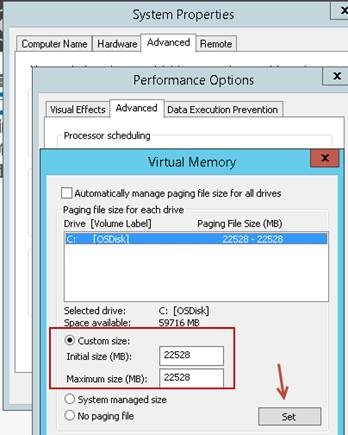
Pagefile otomatikte bırakılmamalı ve olası bir problem anında düzgün memory dump alabilmesi için RAMiniz kadar veya 20 GBdan fazla RAMiniz varsa işletim sisteminin kurulu olduğu disk üzerinde değeri en az 22528 yapılmalı.
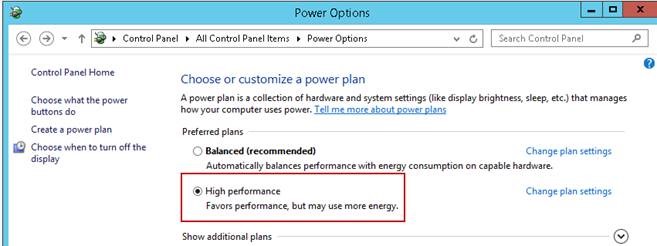
Power Option Ayarı:
Aşağıdaki linkte detaylı bilgiye ulşabileceğiniz gibi tüm kritik servis çalıştıran Sunucularda performansı için Contol Panelden PowerOptiona girip High Performance a getirin.
http://www.masterofmalt.com/software-development/blog/?p=18
Cluster Analizi
Bu kısımda kurulu cluster sistemimizin genel ayarlarına bakacağız.
Active Directory Kontrolü:
Cluster kurarken oluşan sanal isimlerin yönetimi Nodelar olduğundan AD güncellemelerini Nodelar yapmaktadır. Bu nedenle Active Directorydeki Clustera ait Virtual Network Name (CNO) ve Virtual Cluster Object (VCO) bilgisayar objelerinde tüm cluster node ve admin hesaplarına full yetki verilmiş olmalı ki AD üzerinde düzgün işlem yapılabilsin. Bu sürecin detaylı anlatımı ve kontrol için aşağıdaki makaleden faydalanabilirsiniz.
http://www.cozumpark.com/blogs/windows_server/archive/2014/12/28/windows-server-2012-r2-cluster-ortamlarinin-hazirlanmasi.aspx
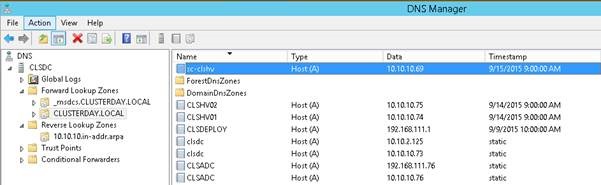
DNS Kontrolü:
ADde olduğu gibi DNS üzerindeki işlemlerin düzgün yapılabilmesi için Cluster Nodelarının DNS üzerindeki CNO ve VCO isimlerine ait kayıtlarda full yetkiye sahip olmalı.
Ayrıca DNS Management üzerinden bakıldığında Clusterın CNO ve VCO kayıtlarının TimeStamp alanında tarih olmalı yani dinamik olmalıdır. Eğer static ise Clusterı stop edip DNS objelerini sildikten sonra Clusterı yeniden start edin.
Witnessın Önemi:
Eğer Clusterınızın işletim sistemi Server 2012R2 ise Dynamic Witness özelliğinin kullanılabilmesi için Witness tanımlanmalı. Konu hakkında detaylı bilgi için aşağıdaki linki inceleyebilirsiniz.
http://www.cozumpark.com/blogs/windows_server/archive/2015/07/26/server-2012-r2-failover-cluster-servisinin-yeniliklerinin-detayli-incelemesi.aspx
Network Ayarlarının Kontrolü:
1) Tüm nodelarda network port isimleri aynı isimde olmalı

2) CNO ve VCOlara ait ip adresleri olası problemlerin önlenmesi için muhakkak static olmalıdır.

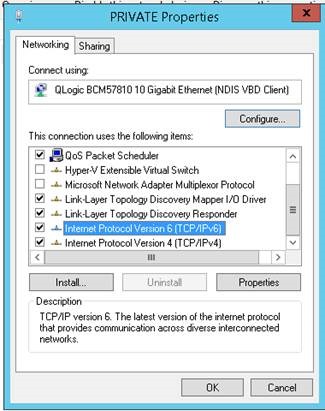
3) Public ve Private interfaceinde IPv6 işaretli olmalı
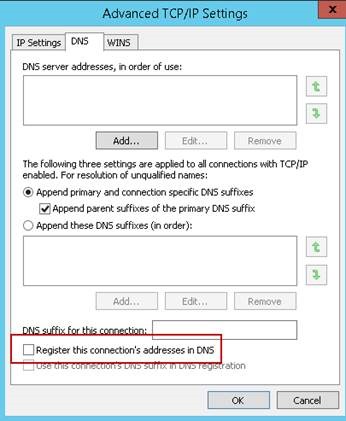
4) Eğer harici backup yazılımı kullanıyorsanız veya File Server Clusterınız varsa Public interfacee WINS adresi girilmeli.
5) Private interfacein subneti Public interfaceden farklı olmalı.
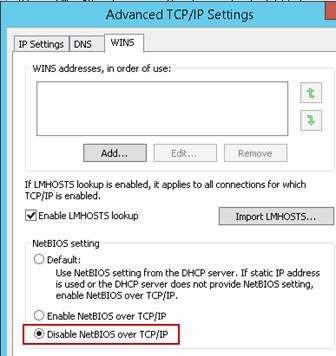
6) Private interfacein de Gateway, DNS ve WINS girilmemeli
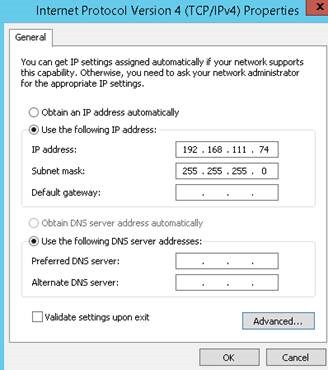
7) Private interfacein DNS ve WINS register işlemi yaptırılmamalı
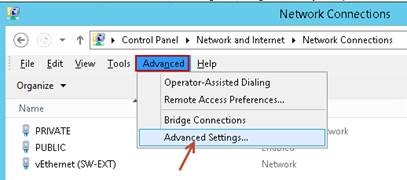
8) Sunucu network erişimindeki önceliği Public interfacede olmalı. Kontrol için Control Panel > Network and Internet > Network Connectionsa geldiğinizde klavyedeki ALT tuşuna basarak menü tabını çıkartıp Advanced alanı içerisindeki Advanced Settings e girin. Eğer public yukarıda değil ise yukarı taşıyın.
Cluster Logun Ayarlanması:
Eğer Hyper-V, FileServer ve SQL Cluster kullanıyorsanız ClusterLOG çok hızlı revize olmaktadır. Olası bir problem anında logların ezilmemesi için ClusterLogSize Default değeri 300 MB olan değerinin 1024 olmalıdır. Bu değerin kontrolü için aşağıdaki komutu PowerShell üzerinde çalıştırınız.
Get-Cluster | fl *
Eğer çıkan sonuç için de ClusterLogSize 1024den küçük ise aşağıdaki komutu çalıştırınız.
Set-ClusterLog -Size 1024
Hyper-V Cluster için Kontroller:
Virtual Switch ve Virtual SAN isimleriniz aynı olmalı
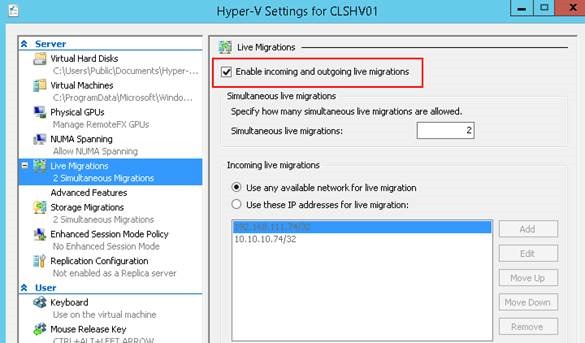
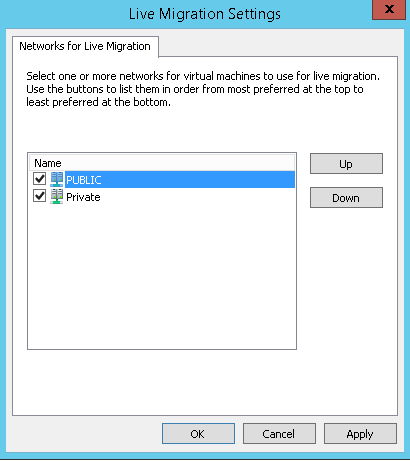
Eğer Clusterınız Hyper-V ise Live Migration ayarlarının kontrol edilmesi gerekiyor. Bunun için hem her nodeun Hyper-V Manager içindeki Hyper-V Settingde hem de Failover Cluster Manager üzerinde Live Migration aktif olmalı. Detaylı bilgiyi aşağıdaki linki verilen makalede bulabilirsiniz.
http://www.cozumpark.com/blogs/windows_server/archive/2014/12/28/windows-server-2012-r2-hyper-v-cluster-yapilmasi-bolum-2.aspx

Cluster Validate Raporu:
Tüm sisteminizin anlaşılır düzeyde ve görsel olarak inceleyebileceğiniz en başarılı analiz aracı Microsoft Failover Cluster Manager Tools içinde yer alan Validate Raporu. İlk defa cluster kurarken zorunlu olan bu analiz işlemini daha sonradan istediğiniz zaman tekrarlayabilirsiniz.
Validation testinde dikkat edilecek en önemli nokta disklerinde teste dahil edilmesinden dolayı failover testinin yapılması. Eğer siz sisteminizde kesinti olmasını istemiyorsanız storage testini seçmemelisiniz.
Validation testinde dikkat edilecek en önemli nokta disklerinde teste dahil edilmesinden dolayı failover testinin yapılması. Eğer siz sisteminizde kesinti olmasını istemiyorsanız storage testini seçmemelisiniz.
Eğer PowerShell üzerinden kesinti olmaksızın Validation analizini yapmak istiyorsanız aşağıdaki komut çalıştırılır.
Test-Cluster -Cluster cls-hyperv -Ignore storage -ReportName c:\cls-hyperv
Bu komutta -Ignore storage parametresi diski dahil etmeden test yapılmasını sağlamaktadır. ReportName parametresi ise oluşturulan raporun nereye kaydedileceğini gösteriyor.
Yaşadığım problemlerin büyük bir bölümü disk veya storage kaynaklı olduğundan ilk kesintiye tamammül edilebilir zamanınız da disklerinde içinde olduğu Validate Raporu oluşturulmalıdır. Bunun içinde aşağıdaki PowerShell komutu çalıştırılıp incelenir.
Test-Cluster -Cluster cls-hyperv -ReportName c:\cls-hyperv
Failover Cluster Diagnostic:
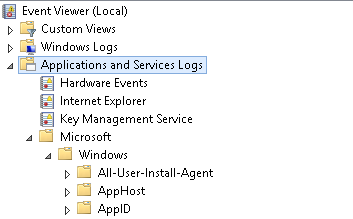
Bazen Validate raporu ve diğer kontrol noktalarında göremediğiniz Clustera özel durumlar gerçekleşebilir. Bu tip durumların önceden görülebilmesi için Event Viewer altında Applications and Services Logs altındaki Microsoft altındaki Windows altında FailoverClustering ve FailoverClustering-Manager altındaki Diagnostic Enable edilerek oluşan loglar incelenir.
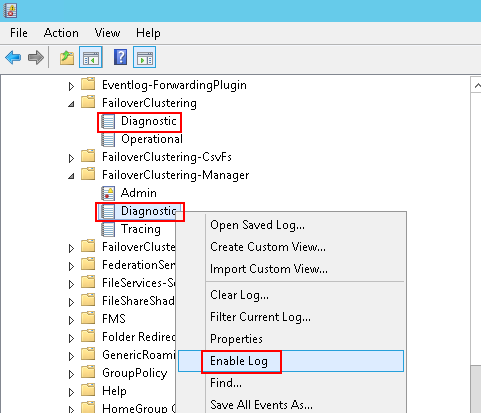
Cluster Log Analizi:
Eğer her şey yolunda gidiyorsa belli aralıklarla aşağıdaki komut çalıştırılarak C:\Windows\Cluster\Reports klasörü altında oluşan Cluster.log isimli LOG dosyası oluşturulup her node için ayrı ayrı incelenir ki ön görülemeyen veya arka planda ters giden bir şeyler varsa anlaşılmasını sağlarsınız.
Get-ClusterLog -UseLocalTime
