



Web Scraping Nedir? Mantığı Nedir Nasıl Çalışır?
Web scraping bir web sitesindeki verileri alıp analiz etmeye denir. Bu işlem genellikle HTML içeriğini çekerek içindeki belirli bilgileri ayıklamak için yapılır.
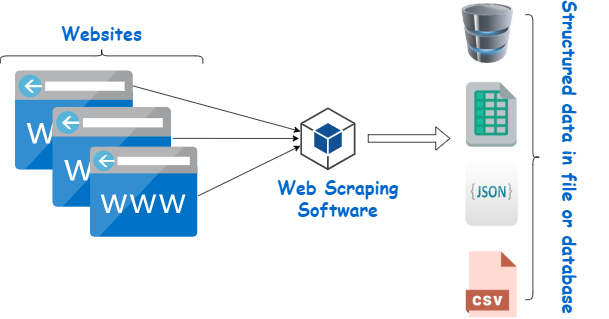
Static Web Scraping İçin Genel Kullanılan Kütüphaneler
requests = Web sayfalarına HTTP isteği göndermek için kullanılır.
BeautifulSoup = HTML içeriğini parse (ayrıştırma) ederek kolayca veri çekmeyi sağlar.
lxml = HTML ve XML parse işlemi yapar BeautifulSoup ile beraber kullanılabilir.
Selenium = Dinamik siteleri (JavaScript ile çalışan siteleri) kontrol etmek için kullanılır.
Scrapy = Büyük ölçekli veri çekme işlemleri için kullanılan güçlü bir framework'tür.
Static Web Scraping İçin Sitenin GET mi POST mu Kullandığını Tespit Etmek
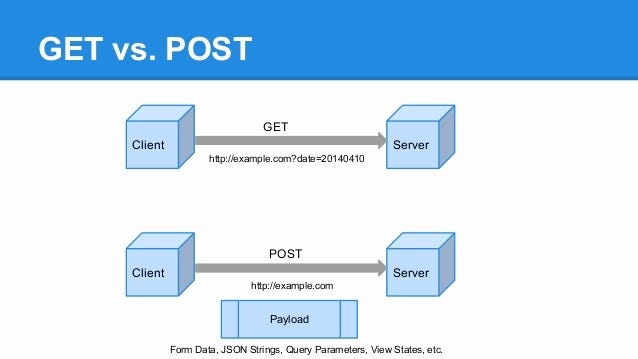
Siteye girip herhangi bir yerde f12 basın veya sağ tık incele yapın, ardından çıkan menüde network kısmını göreceksiniz. Sayfaya refresh atın ve network kısmına bilgiler gelecektir. Buradan herhangi birine tıklayın sağda açılan HEADERS bölümünde Status Code: xxxxxx veya Request Method: xxxxxx burada yazana bakmanız lazım. GET veya POST yazacaktır. Network kısmında yüklenen diğer elemanlara da bakabilirsiniz GET/POST öğrenmek için. GET/POST'un ne olduğunu anlatmadan geçersek detaylı bir rehber olacağını düşünmüyorum. Bu yüzden GET ve POST nedir?
GET Method: GET belirli bir kaynaktan veri istemek için kullanılır.
POST: POST metodu URL'de görüntülenmesi istemediğimiz istekler için kullanılır.
Static Web Scraping İçin Örnek Python Kodu Yazalım!
Öncelikle ==> pip install requests beautifulsoup4
import requests #burada siteye istek atıp isteği html türünde almak için kullanacağımız kütüphaneyi ekliyoruz.
from bs4 import BeautifulSoup #bs4 kütüphanesinden BeautifulSoup modülünü içeri aktardık.
url = "Quotes to Scrape" #sitenin url'sini string bir değişkene atadık.
response = requests.get(url) #response yani türkçesi yanıt olan bir değişken oluşturup url'sini verdiğimiz siteye GET yöntemiyle istek yolladık.
print(response.text) #sayfanın html içeriğini yazdırdık.
filter = BeautifulSoup(response.text, "html.parser") #filter adlı değişkende BeautifulSoup modülüyle html.parser olarak html formatında filtreledik. (lxml de kullanılabilir.)
site1_tag = filter.find_all("div", class_="quote") # sitede div etiketindeki ve quote adında sınıf içeren tüm div başlıkları site1_tag'a atadık.
for headers in site1_tag: #headers yani başlıklar diye loop oluşturduk ve site1_tag içindeyken dedik. döngü açtık çünkü birden fazla veri çekiyoruz.
title = headers.find("span", class_="text") #title değişkenine div etiketinde quote classındaki tüm span ve text olanları bulmasını sağladık.
print(f"{title}" + "\n") #bulduğu herşeyi ekrana yazdırdık.
Dynamic Web Scraping Bir Sonraki Konu")
Aklınıza takılan herhangi bir şey varsa sorabilirsiniz elimden geldiğince yanıtlarım)
Web scraping bir web sitesindeki verileri alıp analiz etmeye denir. Bu işlem genellikle HTML içeriğini çekerek içindeki belirli bilgileri ayıklamak için yapılır.
Static Web Scraping İçin Genel Kullanılan Kütüphaneler
requests = Web sayfalarına HTTP isteği göndermek için kullanılır.
BeautifulSoup = HTML içeriğini parse (ayrıştırma) ederek kolayca veri çekmeyi sağlar.
lxml = HTML ve XML parse işlemi yapar BeautifulSoup ile beraber kullanılabilir.
Selenium = Dinamik siteleri (JavaScript ile çalışan siteleri) kontrol etmek için kullanılır.
Scrapy = Büyük ölçekli veri çekme işlemleri için kullanılan güçlü bir framework'tür.
Static Web Scraping İçin Sitenin GET mi POST mu Kullandığını Tespit Etmek
Siteye girip herhangi bir yerde f12 basın veya sağ tık incele yapın, ardından çıkan menüde network kısmını göreceksiniz. Sayfaya refresh atın ve network kısmına bilgiler gelecektir. Buradan herhangi birine tıklayın sağda açılan HEADERS bölümünde Status Code: xxxxxx veya Request Method: xxxxxx burada yazana bakmanız lazım. GET veya POST yazacaktır. Network kısmında yüklenen diğer elemanlara da bakabilirsiniz GET/POST öğrenmek için. GET/POST'un ne olduğunu anlatmadan geçersek detaylı bir rehber olacağını düşünmüyorum. Bu yüzden GET ve POST nedir?
GET Method: GET belirli bir kaynaktan veri istemek için kullanılır.
POST: POST metodu URL'de görüntülenmesi istemediğimiz istekler için kullanılır.
Static Web Scraping İçin Örnek Python Kodu Yazalım!
Öncelikle ==> pip install requests beautifulsoup4
import requests #burada siteye istek atıp isteği html türünde almak için kullanacağımız kütüphaneyi ekliyoruz.
from bs4 import BeautifulSoup #bs4 kütüphanesinden BeautifulSoup modülünü içeri aktardık.
url = "Quotes to Scrape" #sitenin url'sini string bir değişkene atadık.
response = requests.get(url) #response yani türkçesi yanıt olan bir değişken oluşturup url'sini verdiğimiz siteye GET yöntemiyle istek yolladık.
print(response.text) #sayfanın html içeriğini yazdırdık.
filter = BeautifulSoup(response.text, "html.parser") #filter adlı değişkende BeautifulSoup modülüyle html.parser olarak html formatında filtreledik. (lxml de kullanılabilir.)
site1_tag = filter.find_all("div", class_="quote") # sitede div etiketindeki ve quote adında sınıf içeren tüm div başlıkları site1_tag'a atadık.
for headers in site1_tag: #headers yani başlıklar diye loop oluşturduk ve site1_tag içindeyken dedik. döngü açtık çünkü birden fazla veri çekiyoruz.
title = headers.find("span", class_="text") #title değişkenine div etiketinde quote classındaki tüm span ve text olanları bulmasını sağladık.
print(f"{title}" + "\n") #bulduğu herşeyi ekrana yazdırdık.
Dynamic Web Scraping Bir Sonraki Konu
Aklınıza takılan herhangi bir şey varsa sorabilirsiniz elimden geldiğince yanıtlarım
)")

