

As the decade of 2010 comes to a close, it is important to reflect on the enormous advancements made in deep learning during this time. Deep Learning has successfully addressed many formerly intractable issues, particularly in Computer Vision and Natural Language Processing, thanks to the development of ever-more powerful computing and the increased accessibility of big data. Everywhere we look, deep learning is starting to be used in practical ways, from the serious to the silly, from autonomous vehicles and medical imaging to virtual helpers and deepfakes.
This post is an diagram of a few the foremost compelling Profound Learning papers of the final decade. My trust is to supply a jumping-off point into numerous different ranges of Profound Learning by giving concise and thick rundowns that go somewhat more profound than a surface level piece, with numerous references to the significant assets.
Given the nature of investigate, allotting credit is exceptionally difficult—the same ideas are sought after by numerous at the same time, and the foremost persuasive paper is frequently not one or the other the primary nor the leading. I attempt my best to tiptoe the line between influence and first/best works by posting the foremost persuasive papers as primary entries and the other pertinent papers that go before or move forward upon the most section as honorable mentions.[2] Of course, as such a list will continuously be subjective, usually not implied to be last, thorough, or definitive. On the off chance that you are feeling that the requesting, exclusion, or portrayal of any paper is inaccurate, it would be ideal if you let me know—I would be more than happy to progress this list by making it more total and exact.
2010
Understanding the difficulty of training deep feedforward neural networks
")
This paper explored some problems with deep networks, especially surrounding random initialization of weights. This paper also noticed issues with sigmoid and hyperbolic tangent activations, and proposed an alternative, SoftSign, which is a sigmoidal activation function with smoother asymptopes. The most lasting contribution of this paper, however, is in initialization. When initialized with normally-distributed weights, it is easy for values in the network to explode or vanish, preventing training. Assuming the values from the previous layer are i.i.d Gaussians, adding them adds their variances, and thus the variance should be scaled down proportionally to the number of inputs to keep the output zero mean and unit variance.
2011
Deep Sparse Rectifier Neural Networks
")
Most neural networks used sigmoids for intermediate activations, starting with the earliest MLPs and continuing through many networks toward the middle of the decade. The logistic and hyperbolic tangent functions, which make up the majority of sigmoids, have the advantages of being differentiable everywhere and having a bounded output. They also offer a satisfying analogy to the all-or-none law of biological neurons. However, as more layers are added, the gradient is frequently quickly reduced because the derivative of sigmoid functions decays quickly away from zero. The vanishing gradient problem, which is one of the reasons why scaling networks in depth was challenging, is caused by this. This study discovered that applying ReLUs to the vanishing gradient problem made deeper networks possible.
")
Sigmoid and its derivative
In spite of this, in any case, ReLUs still have a few blemishes:
they are non-differentiable at zero[5], they can develop unbounded, and neurons seem “die” and gotten to be dormant due to the immersed half of the enactment. Since 2011, numerous made strides enactments have been proposed to illuminate the issue, but vanilla ReLUs are still competitive, as the adequacy of numerous unused actuations has been beneath address.
The paper Computerized determination and simple enhancement coexist in a cortex-inspired silicon circuit (2000) is by and large credited to be the primary paper to set up the biological plausibility of the ReLU, and What is the Most excellent Multi-Stage Engineering for Protest Acknowledgment? (2009) was the most punctual paper that I was able to discover that investigated utilizing the ReLU (alluded to as the positive portion in this paper) for neural systems.
2012
ImageNet Classification with Deep Convolutional Neural Networks
")
AlexNet architecture
AlexNet is an 8 layer Convolutional Neural Arrange utilizing the ReLU enactment work and 60 million parameters. The significant commitment of AlexNet was illustrating the control of more profound systems, as its design was, in pith, a more profound adaptation of past systems (i.e LeNet).
The AlexNet paper is by and large recognized as the paper that started the field of Profound Learning. AlexNet was moreover one of the primary systems to use the greatly parallel preparing control of GPUs to prepare much more profound convolutional systems than some time recently. The result was bewildering, bringing down the blunder rate on ImageNet from 26.2% to 15.3%, and beating each other contender in ILSVRC 2012 by a wide edge. This gigantic enhancement in blunder pulled in a part of consideration to the field of Profound Learning, and made the AlexNet paper the foremost cited papers in Profound Learning.
")
An example of images from the ImageNet hierarchy
ImageNet:
A Large-Scale Various leveled Picture Database:
The ImageNet dataset itself is additionally in expansive portion dependable for the boom in Profound Learning. With 15050 citations, it is additionally one of the foremost cited papers in all of Profound Learning (because it was distributed in 2009, I have chosen to list it as an honorable specify). The dataset was built utilizing Amazon Mechanical Turk to outsource the classification errand to laborers, which made this astronomically-sized dataset conceivable. The ImageNet Huge Scale Visual Acknowledgment Challenge (ILSVRC), the challenge for picture classification calculations brought forth by the ImageNet database, was moreover dependable for driving the improvement of numerous other advancements in Computer Vision.
Adaptable, Tall Execution Convolutional Neural Systems for Picture Classification:
This paper originates before AlexNet and has much in common with it:
both papers utilized GPU increasing speed for preparing more profound systems, and both utilize the ReLU actuation that fathomed the vanishing angle issue of profound systems. A few contend that this paper has been unjustifiably reprimanded of its put, getting distant less citations than AlexNet.
")
- LeNet architecture
- Gradient-Based Learning Applied to Document Recognition: This paper from 1998, with a whopping 23110 citations, is the oft-cited pioneer of CNNs for image recognition. Indeed, modern CNNs are almost exactly scaled up versions of this early work! Even earlier is LeCun’s less cited (though, with 5697 citations, it’s nothing to scoff at) 1989 paper Backpropagation Applied to Handwritten Zip Codes, arguably the first gradient descent CNN.
2013
Distributed Representations of Words and Phrases and their Compositionality
This paper (and the slightly earlier Efficient Estimation of Word Representations in Vector Space by the same authors) introduced word2vec, which became the dominant way to encode text for Deep Learning NLP models. It is based on the idea that words which appear in similar contexts likely have similar meanings, and thus can be used to embed words into vectors (hence the name) to be used downstream in other models. Word2vec, in particular, trains a network to predict the context around a word given the word itself, and then extracting the latent vector from the network.
The results of DeepMind’s Atari DQN kickstarted the field of Deep Reinforcement Learning. Reinforcement Learning was previously used mostly on low-dimensional environments such as gridworlds, and was difficult to apply to more complex environments. Atari was the first successful application of reinforcement learning to a high-dimensional environment, which brought Reinforcement Learning from obscurity to an important subfield of AI.
The results of DeepMind’s Atari DQN kickstarted the field of Deep Reinforcement Learning. Reinforcement Learning was previously used mostly on low-dimensional environments such as gridworlds, and was difficult to apply to more complex environments. Atari was the first successful application of reinforcement learning to a high-dimensional environment, which brought Reinforcement Learning from obscurity to an important subfield of AI.
2014
Generative Adversarial Networks
")
Generative Adversarial Networks have been successful in no small part due to the stunning visuals they produce. Relying on a minimax game between a Generator and a Discriminator, GANs are able to model complex, high dimensional distributions
The cost used for the generator in the minimax game is useful for theoretical analysis, but does not perform especially well in practice.Goodfellow, 2016
2015
")
Residual Block Architecture Initially designed to deal with the problem of vanishing/exploding gradients in deep CNNs, the residual block has become the elementary building block for almost all CNNs today. The idea is very simple—add the input from before each block of convolutional layers to the output. The inspiration behind residual networks is that neural networks should theoretically never degrade with more layers, as additional layers could, in the worst case, be set simply as identity mappings. However, in practice, deeper networks often experience difficulties training. Residual networks made it easier for layers to learn an identity mapping, and also reduced the issue of gradient vanishing. Despite the simplicity, however, residual networks vastly outperform regular CNNs, especially for deeper networks.
2016
")
Supervised Learning and Reinforcement Learning pipeline; Policy/Value Network Architectures
After the defeat of Kasparov by Deep Blue, Go became the next goal for the AI community, thanks to its properties: a much larger state space than chess and a greater reliance on intuition among human players. Up until AlphaGo, the most successful Go systems such as Crazy Stone and Zen were a combination of a Monte-Carlo tree search with many handcrafted heuristics to guide the tree search. Judging from the progress of these systems, defeating human grandmasters was considered at the time to be many years away. Although previous attempts at applying neural networks to Go do exist, none have reached the level of success of AlphaGo, which combines many of these previous techniques with big compute. Specifically, AlphaGo consists of a policy network and a value network that narrow the search tree and allow for truncation of the search tree, respectively. These networks were first trained with standard Supervised Learning and then further tuned with Reinforcement Learning.
AlphaGo has made, of all the advancements listed here, possibly the biggest impact on the public mind, with an estimated 100 million people globally (especially from China, Japan, and Korea, where Go is very popular) tuning in to the AlphaGo vs. Lee Sedol match. The games from this match and the other later AlphaGo Zero matches have influenced human strategy in Go. One example of a very influential move by AlphaGo is the 37th move in the second game; AlphaGo played very unconventionally, baffling many analysts. This move later turned out to be crucial in securing the win for AlphaGo later.
2017
")
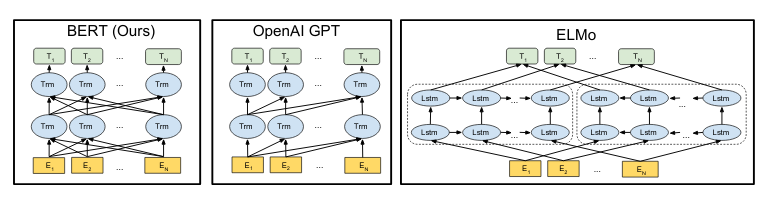
Transformer Architecture The Transformer architecture, making use of the aforementioned attention mechanism at scale, has become the backbone of nearly all state-of-the-art NLP models today. Transformer models beat RNNs in large part due to the computational benefits in very large networks; in RNNs, gradients need to be propagated through the entire “unrolled” graph, which makes memory access a large bottleneck. This also exacerbates the exploding/vanishing gradients problem, necessitating more complex (and more computationally expensive!) LSTM and GRU models. Instead, Transformer models are optimized for highly parallel processing. The most computationally expensive components are the feed forward networks after the attention layers, which can be applied in parallel, and the attention itself, which is a large matrix multiplication and is also easily optimized.
The architecture of NASNet, a network designed using NAS techniques
Neural Architecture Search has become common practice in the field for squeezing every drop of performance out of networks. Instead of designing architectures painstakingly by hand, NAS allows this process to be automated. In this paper, a controller network is trained using RL to produce performant network architectures, which has created many SOTA networks. Other approaches, such as Regularized Evolution for Image Classifier Architecture Search (AmoebaNet), use evolutionary algorithms instead.
2018
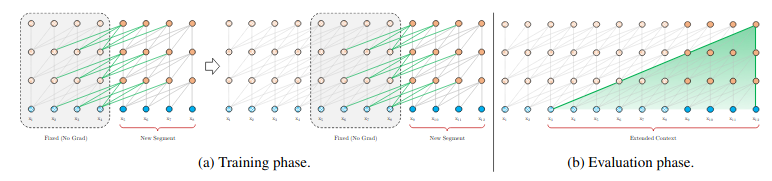
2019
The phenomenon of (Deep) Double Descent explored in this paper runs contrary to popular wisdom in both classical machine learning and modern Deep Learning. In classical machine learning, model complexity follows the bias-variance tradeoff. Too weak a model is unable to fully capture the structure of the data, while too powerful a model can overfit and capture spurious patterns that don’t generalize. Because of this, in classical machine learning it is expected that test error will decrease as models get larger, but then start to increase again once the models begin to overfit. In practice, however, in Deep Learning, models are very often massively overparameterized and yet still seem to improve on test performance with larger models. This conflict is the motivation behind (deep) double descent. Deep Double Descent expanded on the original Double Descent paper by Belkin et al. by showing empirically the effects of Double Descent on a much wider variety of Deep Learning models, and its applicability to not only the model size but also training time and dataset size.
Residual Block Architecture Initially designed to deal with the problem of vanishing/exploding gradients in deep CNNs, the residual block has become the elementary building block for almost all CNNs today. The idea is very simple—add the input from before each block of convolutional layers to the output. The inspiration behind residual networks is that neural networks should theoretically never degrade with more layers, as additional layers could, in the worst case, be set simply as identity mappings. However, in practice, deeper networks often experience difficulties training. Residual networks made it easier for layers to learn an identity mapping, and also reduced the issue of gradient vanishing. Despite the simplicity, however, residual networks vastly outperform regular CNNs, especially for deeper networks.
2016
Supervised Learning and Reinforcement Learning pipeline; Policy/Value Network Architectures
After the defeat of Kasparov by Deep Blue, Go became the next goal for the AI community, thanks to its properties: a much larger state space than chess and a greater reliance on intuition among human players. Up until AlphaGo, the most successful Go systems such as Crazy Stone and Zen were a combination of a Monte-Carlo tree search with many handcrafted heuristics to guide the tree search. Judging from the progress of these systems, defeating human grandmasters was considered at the time to be many years away. Although previous attempts at applying neural networks to Go do exist, none have reached the level of success of AlphaGo, which combines many of these previous techniques with big compute. Specifically, AlphaGo consists of a policy network and a value network that narrow the search tree and allow for truncation of the search tree, respectively. These networks were first trained with standard Supervised Learning and then further tuned with Reinforcement Learning.
AlphaGo has made, of all the advancements listed here, possibly the biggest impact on the public mind, with an estimated 100 million people globally (especially from China, Japan, and Korea, where Go is very popular) tuning in to the AlphaGo vs. Lee Sedol match. The games from this match and the other later AlphaGo Zero matches have influenced human strategy in Go. One example of a very influential move by AlphaGo is the 37th move in the second game; AlphaGo played very unconventionally, baffling many analysts. This move later turned out to be crucial in securing the win for AlphaGo later.
2017
Transformer Architecture The Transformer architecture, making use of the aforementioned attention mechanism at scale, has become the backbone of nearly all state-of-the-art NLP models today. Transformer models beat RNNs in large part due to the computational benefits in very large networks; in RNNs, gradients need to be propagated through the entire “unrolled” graph, which makes memory access a large bottleneck. This also exacerbates the exploding/vanishing gradients problem, necessitating more complex (and more computationally expensive!) LSTM and GRU models. Instead, Transformer models are optimized for highly parallel processing. The most computationally expensive components are the feed forward networks after the attention layers, which can be applied in parallel, and the attention itself, which is a large matrix multiplication and is also easily optimized.
The architecture of NASNet, a network designed using NAS techniques
Neural Architecture Search has become common practice in the field for squeezing every drop of performance out of networks. Instead of designing architectures painstakingly by hand, NAS allows this process to be automated. In this paper, a controller network is trained using RL to produce performant network architectures, which has created many SOTA networks. Other approaches, such as Regularized Evolution for Image Classifier Architecture Search (AmoebaNet), use evolutionary algorithms instead.
2018
2019
The phenomenon of (Deep) Double Descent explored in this paper runs contrary to popular wisdom in both classical machine learning and modern Deep Learning. In classical machine learning, model complexity follows the bias-variance tradeoff. Too weak a model is unable to fully capture the structure of the data, while too powerful a model can overfit and capture spurious patterns that don’t generalize. Because of this, in classical machine learning it is expected that test error will decrease as models get larger, but then start to increase again once the models begin to overfit. In practice, however, in Deep Learning, models are very often massively overparameterized and yet still seem to improve on test performance with larger models. This conflict is the motivation behind (deep) double descent. Deep Double Descent expanded on the original Double Descent paper by Belkin et al. by showing empirically the effects of Double Descent on a much wider variety of Deep Learning models, and its applicability to not only the model size but also training time and dataset size.
By considering larger function classes, which contain more candidate predictors compatible with the data, we are able to find interpolating functions that have smaller norm and are thus “simpler”. Thus increasing function class capacity improves performance of classifiers.Belkin et al. 2018
As the capacity of the models approaches the “interpolation threshold,” the demarcation between the classical ML and Deep Learning regimes, it becomes possible for gradient descent to find models that achieve near-zero error, which are likely to be overfit. However, as the model capacity is increased even further, the number of different models that can achieve zero training error increases, and the likelihood that some of them fit the data smoothly (i.e without overfitting) increases. Double Descent posits that gradient descent is more likely to find these smoother zero-training-error networks, which generalize well despite being overparameterized
Conclusion and Future Prospects
The past decade has checked an fantastically fast-paced and inventive period within the history of AI, driven by the begin of the Profound Learning Revolution—the Renaissance of gradient-based systems. Impelled in expansive portion by the ever expanding computing control accessible, neural systems have gotten much bigger and hence more effective, uprooting conventional AI methods over the board, from Computer Vision to Characteristic Dialect Handling. Neural systems do have their shortcomings in spite of the fact that:
they require a huge sum of information to prepare, have mystifying disappointment modes, and cannot generalize past person errands. As the limits of Profound Learning with regard to progressing AI have started to ended up clear much appreciated to the gigantic advancements within the field, consideration has moved towards a more profound understanding of Profound Learning. The following decade is likely to be checked by an expanded understanding of numerous of the experimental characteristics of neural systems watched nowadays. Actually, I am hopeful almost the prospects of AI; Profound Learning is an priceless device within the toolkit of AI, that brings us however another step closer to understanding insights.

