



Bu çalışma, IMDB film incelemeleri veri setini kullanarak basit bir sinir ağı modeli oluşturmayı ve eğitmeyi hedeflemektedir. Keras ve TensorFlow kütüphanelerini kullanarak, film incelemelerinin pozitif veya negatif olarak sınıflandırılmasını sağlayan bir model geliştirilmiştir. Çalışmanın amacı, temel makine öğrenimi tekniklerini uygulamak ve derin öğrenme kavramlarını anlamaktır.
Makine öğrenimi ve derin öğrenme, günümüzde birçok alanda önemli bir yere sahiptir. Özellikle doğal dil işleme (NLP) uygulamaları, metin verilerinin analizi ve sınıflandırılması için yaygın bir şekilde kullanılmaktadır. Bu çalışmada, Keras kütüphanesi kullanılarak film incelemeleri üzerinde bir sinir ağı modeli oluşturulmuştur. IMDB veri seti, geniş bir metin koleksiyonu sunmakta olup, bu veri seti üzerinde yapılan çalışmalar literatürde geniş bir yer kaplamaktadır.
Sinir Ağları, birden fazla katman içeren ve daha karmaşık yapıdadır. Her katman, belirli bir sayıda nörondan oluşur ve her nöron, bir önceki katmandan gelen verilere ağırlıklar uygular. Sinir ağları, derin öğrenme uygulamalarında yaygın olarak kullanılır ve karmaşık ilişkileri modelleme yeteneğine sahiptir. Farklı katmanlar ve nöron sayıları ile daha derin ve güçlü ağlar oluşturulabilir.
Multi-Hot Kodlama ise birden fazla sınıfın aynı anda temsil edilebildiği bir durumdur. Bu yöntemde, birden fazla 1 değerine sahip vektörler oluşturulabilir. Örneğin, bir film incelemesinde hem korku hem de dram kategorisinde olabilir. Bu durumda multi-hot kodlama şu şekilde olacaktır: [1, 0, 1]. Multi-hot kodlama, çok etiketli sınıflandırma problemleri için uygundur ve genellikle doğal dil işleme uygulamalarında kullanılır.
Yöntem
Makine öğrenimi ve derin öğrenme, günümüzde birçok alanda önemli bir yere sahiptir. Özellikle doğal dil işleme (NLP) uygulamaları, metin verilerinin analizi ve sınıflandırılması için yaygın bir şekilde kullanılmaktadır. Bu çalışmada, Keras kütüphanesi kullanılarak film incelemeleri üzerinde bir sinir ağı modeli oluşturulmuştur. IMDB veri seti, geniş bir metin koleksiyonu sunmakta olup, bu veri seti üzerinde yapılan çalışmalar literatürde geniş bir yer kaplamaktadır.
Perceptron ve Sinir Ağları
Perceptron, en basit yapay sinir ağı modelidir. Tek bir katmanlı bir ağdır ve giriş katmanında birkaç nöron bulundurur. Perceptron, sınıflandırma problemlerini çözmek için kullanılır. Eğitim sürecinde, giriş verilerine uygulanan ağırlıklar güncellenerek modelin doğru sınıflandırma yapması sağlanır.Sinir Ağları, birden fazla katman içeren ve daha karmaşık yapıdadır. Her katman, belirli bir sayıda nörondan oluşur ve her nöron, bir önceki katmandan gelen verilere ağırlıklar uygular. Sinir ağları, derin öğrenme uygulamalarında yaygın olarak kullanılır ve karmaşık ilişkileri modelleme yeteneğine sahiptir. Farklı katmanlar ve nöron sayıları ile daha derin ve güçlü ağlar oluşturulabilir.
One-Hot ve Multi-Hot Kodlama
One-Hot Kodlama, bir veriyi belirli bir sınıf için 1 ve diğerleri için 0 olan bir vektörle temsil etme yöntemidir. Örneğin, üç sınıfın olduğu bir durumda, ikinci sınıf için one-hot kodlama şu şekilde olacaktır: [0, 1, 0]. Bu kodlama türü genellikle sınıflandırma problemlerinde kullanılır, çünkü modelin her sınıfı ayrı ayrı tanımasını sağlar.Multi-Hot Kodlama ise birden fazla sınıfın aynı anda temsil edilebildiği bir durumdur. Bu yöntemde, birden fazla 1 değerine sahip vektörler oluşturulabilir. Örneğin, bir film incelemesinde hem korku hem de dram kategorisinde olabilir. Bu durumda multi-hot kodlama şu şekilde olacaktır: [1, 0, 1]. Multi-hot kodlama, çok etiketli sınıflandırma problemleri için uygundur ve genellikle doğal dil işleme uygulamalarında kullanılır.
Yöntem
Kod:
# Gerekli kütüphaneleri yükleyin
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import imdb
import re # Regex için
from tensorflow.keras import models, layers
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
# TensorFlow sürümünü
print(f'TensorFlow Sürümü: {tf.__version__}')
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print("İlk 15 incelemenin uzunlukları:")
for i in range(15):
print(f'İnceleme {i+1}: {len(train_data[i])} kelime')
word_index = imdb.get_word_index()
reverse_word_index = {value: key for (key, value) in word_index.items()}
print("İlk 5 kelime ve indeksleri:", list(reverse_word_index.items())[:5])
def decode_review(word_indices):
# Özel karakterler
codes = ["<PAD>", "<START>", "<OOV>"]
decoded_words = []
for i in word_indices:
if i == 0:
decoded_words.append(codes[0])
elif i == 1:
decoded_words.append(codes[1])
elif i == 2:
decoded_words.append(codes[2])
else:
decoded_word = reverse_word_index.get(i - 3, "?")
decoded_words.append(decoded_word)
return ' '.join(decoded_words)
decoded_review = decode_review(train_data[0])
print(f'İlk eğitim incelemesi (metin): {decoded_review}')
def clean_review(review):
# Noktalama işaretlerini kaldır
review = re.sub(r'[^\w\s]', '', review)
review = re.sub(r'\s+', ' ', review).strip()
return review
cleaned_review = clean_review(decoded_review)
print(f'İlk eğitim incelemesi (temizlenmiş metin): {cleaned_review}')
def vectorize(data, dimensions):
"""
Args:
data (list of lists): İncelemeleri temsil eden kelime indeksleri listesi.
dimensions (int): Vektörün boyutu (sözlük boyutu).
Returns:
numpy.ndarray: Çoklu-sıcak kodlanmış vektörler matrisi.
"""
multihot = np.zeros((len(data), dimensions))
for row, review in enumerate(data):
for index in review:
if index < dimensions:
multihot[row, index] = 1
return multihot
def vectorize_fast(data, dimensions):
"""
Çoklu incelemeyi çoklu-sıcak kodlanmış bir numpy dizisine dönüştürür (hızlı versiyon).
Args:
data (list of lists): İncelemeleri temsil eden kelime indeksleri listesi.
dimensions (int): Vektörün boyutu (sözlük boyutu).
Returns:
numpy.ndarray: Çoklu-sıcak kodlanmış vektörler matrisi.
"""
multihot = np.zeros((len(data), dimensions))
rows = []
cols = []
for row, review in enumerate(data):
valid_indices = [index for index in review if index < dimensions]
rows.extend([row] * len(valid_indices))
cols.extend(valid_indices)
multihot[rows, cols] = 1
return multihot
print("Çoklu-sıcak kodlama yapılıyor...")
x_train = vectorize_fast(train_data, 10000)
x_test = vectorize_fast(test_data, 10000)
print("Çoklu-sıcak kodlama tamamlandı.")
print(f'Train: {x_train.shape} Test: {x_test.shape}')
print("İlk 5 çoklu-sıcak kodlanmış vektör:")
print(x_train[:5])
def label_to_sentiment(label):
"""
0 veya 1 değerini "Negatif" veya "Pozitif" kelimelerine dönüştürür.
Args:
label (int): Etiket değeri (0 veya 1).
Returns:
str: "Negatif" veya "Pozitif".
"""
if label == 1:
return "Pozitif"
elif label == 0:
return "Negatif"
else:
return "Bilinmeyen"
print(f'İlk eğitim etiketi (okunabilir): {label_to_sentiment(train_labels[0])}')
y_train = np.array(train_labels).astype(np.float32)
y_test = np.array(test_labels).astype(np.float32)
print((y_train, y_test))
print(f'İlk 10 eğitim etiketi: {[label_to_sentiment(label) for label in y_train[:10]]}')
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Modeli eğitme
history = model.fit(x_train,
y_train,
epochs=10,
batch_size=512,
validation_split=0.2)
results = model.evaluate(x_test, y_test)
print(f'Test Loss: {results[0]}, Test Accuracy: {results[1]}')
history_dict = history.history
accuracy = history_dict['accuracy']
val_accuracy = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(accuracy) + 1)
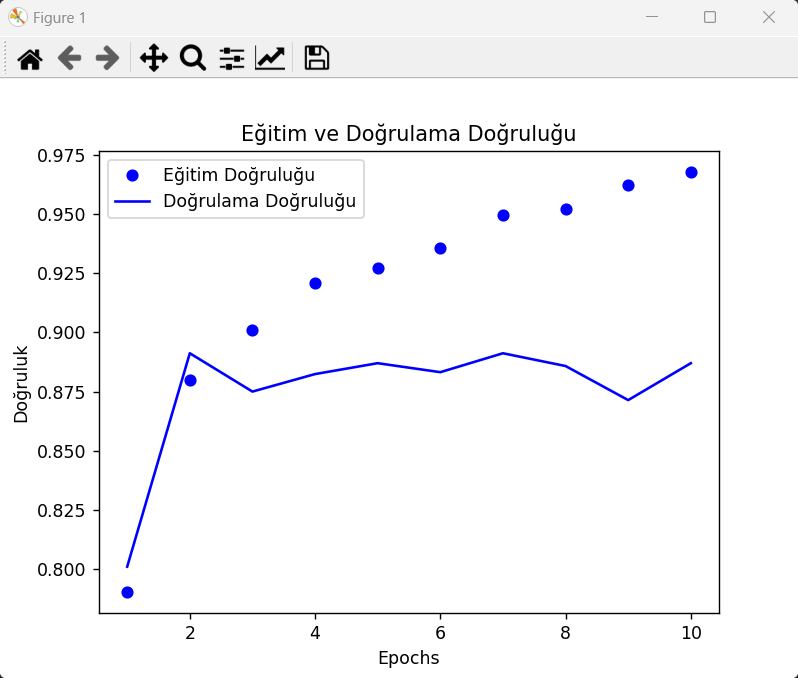
plt.plot(epochs, accuracy, 'bo', label='Eğitim Doğruluğu')
plt.plot(epochs, val_accuracy, 'b', label='Doğrulama Doğruluğu')
plt.title('Eğitim ve Doğrulama Doğruluğu')
plt.xlabel('Epochs')
plt.ylabel('Doğruluk')
plt.legend()
plt.show()
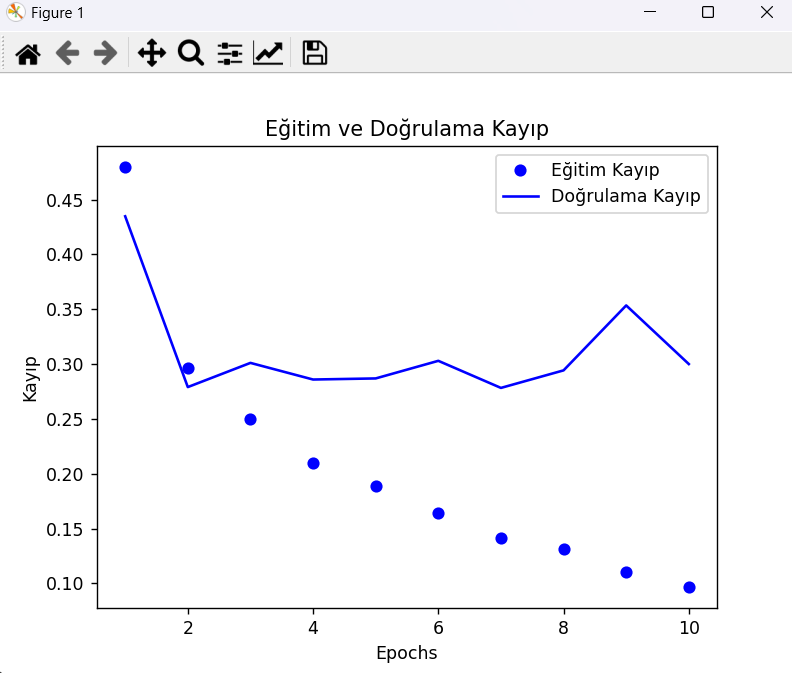
plt.plot(epochs, loss, 'bo', label='Eğitim Kayıp')
plt.plot(epochs, val_loss, 'b', label='Doğrulama Kayıp')
plt.title('Eğitim ve Doğrulama Kayıp')
plt.xlabel('Epochs')
plt.ylabel('Kayıp')
plt.legend()
plt.show()Çıktılar
- Eğitim ve Test Sonuçları:
- Modelin eğitimi sırasında elde edilen doğruluk (accuracy) ve kayıp (loss) değerleri:
- Eğitim doğruluğu: %97.08
- Eğitim kaybı: 0.0910
- Test doğruluğu: %88.14
- Test kaybı: 0.3159
- Modelin eğitimi sırasında elde edilen doğruluk (accuracy) ve kayıp (loss) değerleri:
- Eğitim Süreci:
- 10 dönem boyunca modelin performansı izlenmiş. İlk dönemden son döneme kadar doğruluk değerinde belirgin bir artış gözlemlenmiştir.
- Validation set (doğrulama seti) kullanılması, modelin genel performansını değerlendirmek için önemlidir.
Değerlendirme
- Sonuçların Analizi: Model, eğitim verisinde oldukça iyi bir performans göstermiş, ancak test verisinde doğruluğun biraz daha düşük olduğu görülüyor. Bu, modelin aşırı öğrenme (overfitting) yapmadığını gösteriyor; yine de modelin test verisi üzerindeki performansını iyileştirmek için çeşitli yollar araştırılabilir.
- Modelin Yapısı:
- Kullanılan iki katmanlı sinir ağı (512 nöronlu yoğun katman ve 1 nöronlu çıkış katmanı) bu problem için yeterli gibi görünüyor. Ancak, daha karmaşık bir model veya farklı hiperparametre ayarları ile performansı artırmak mümkündür.
 Eline emeğine sağlık.
Eline emeğine sağlık.
