



Herkese merhaba, uzun zamandır bir blog yazısı yazmıyordum. Bugün yapay zekada bir devrim niteliği taşıyan attention yapılarından ve sıklıkla beraber anılan transformer mekanizmalarından bahsedeceğiz. İlk olarak NLP (Natural Language Processing) ile birlikte ortaya çıkan attention mekanizmaları, cümle içerisindeki kelimelerin birbirleriyle ilişkisini hesaplayan bir matematiksel işleç olup, kullanılan cümlenin ne anlama geldiğini kavramada öncesindeki RNN modellerine göre çok çok daha başarılı sonuçlar üretmiştir. Ardından bu başarısını Vision Transformer gibi farklı şekiller alarak görüntü işleme, ses işleme gibi farklı alanlarda da sürdürmüştür. Günümüzde kullanılan birçok yapay zeka modeli, "Transformer" adı verilen yapılara sahiptir. Biz blogumuzda bu konudaki en temel makale olan "Attention Is All You Need" (Vaswani et. al., 2023) makalesine değineceğiz.
Önemli not: Bu blog'daki transformer'ımızda bir decoder bloğu yer almayacak. Classifier amaçlı kullanılacak bir encoder yazacağız.
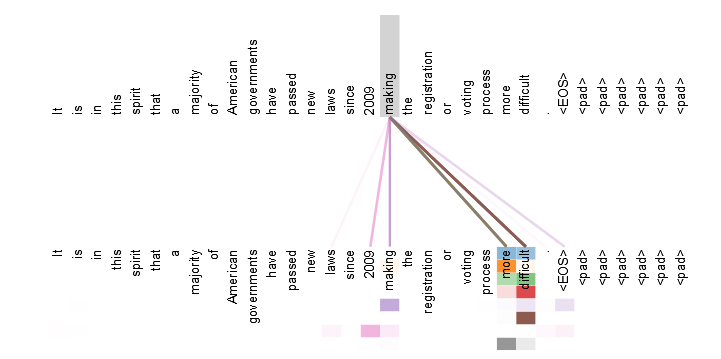
Vaswani makalesinde, "It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult" cümlesini örnek gösteriyor. Elbette bu kelime cümle alelade seçilmiş bir cümle değil. Hem uzun, hem de arada başka kelimeler bulunan kalıpları içeriyor. Örnek olarak ,,making ... the more difficult'' [daha da zorlaştırıyor] cümlesinin yapay zekalar tarafından anlaşılması oldukça zor, çünkü making eyleminin tanımladığı yapı kendisinden hayli uzakta. Bu noktada her bir kelimeyi, belirli bir ağırlık değeriyle çarpıp birbiri arasındaki çapraz korelasyonu inceleyerek yeni kelime vektörleri üretiriz, bu işlemi yapan yapıya "multi-head attention block" denir ve encoder'ların içinde kullanılır. Çok karışmaması adına matematiğine girmeyeceğim, şimdilik sadece kelimelerin birbirleriyle olasılıksal ilişkisini hesapladığımızı bilmemiz yeterli.
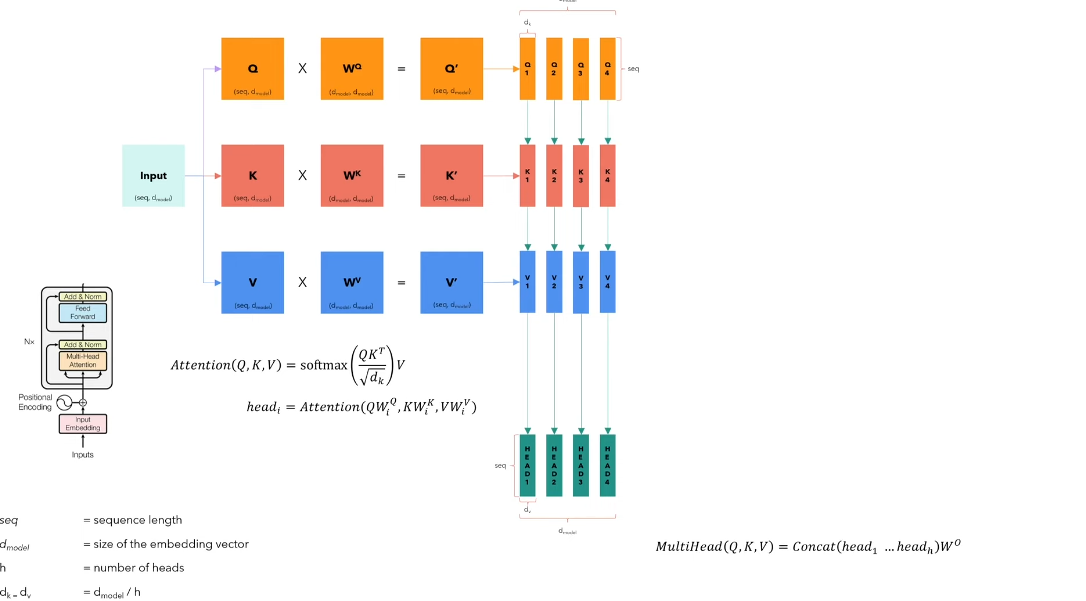
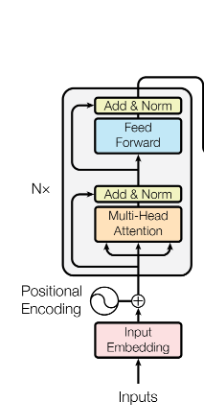
Sadece encoder bloğunu kodlayacağımız (ve, olabildiğince basit bir şekilde. Tamamen apayrı bir yazı olabilecek positional encoding gibi karmaşık yapılara bu yazıda yer vermeyeceğim) için yapının görselini verelim. Tabii ki biz çıkışı bir decoder'a bağlamayacak, classifier layer yazacağız.
Vaswani makalesinde d_k, d_v ve d_model/h isimlendirmelerini farklı yapmış. Biz d_k ve d_v için aynı değişkeni kullanacağız (sonuçta çıktı vektörlerinin boyutları birebir aynı). Bir MultiHeadAttentionBlock sınıfı oluşturalım ve parametrelerimizi tanımlayalım
Makalede attention modülü Query (Q) ve Key (K^T) matrislerini çarpıyor ve vektör boyutunun kareköküne böldükten sonra softmax fonksiyonu ile olasılık vektörünü elde ediyor. Ardından bu sonucu Value değerleriyle çarpıyor. Birebir aynı matematiksel işlemi sınıfımıza ekleyelim
Ardından elde ettiğimiz vektörleri concate işlemi ile birleştirip çıkış ağırlık matrisi (W_o) ile çarpmamız lazım. Tüm fonksiyonlarımız hazır olduğuna göre işlemi gerçekleyen bir forward modülü yazabiliriz.
Görseli hatırlayacak olursak attention bloğunun çıktılarını bir adet normalizasyon layer'ına bağlıyor, ardından input olarak verilen raw data ile de bu layerı besliyorduk. Çıktıyı normalize edip saf verimizle topladığımız basit bir residual connection block yazalım.
Şimdi eksiğimiz olan tek yapı feed forward bloğu oldu. Vaswani bu bloğu makalesinde görseldeki gibi tanımlıyor:

Kabaca söylemek istediği, Feed Forward Network'lerin (FFN) iki adet linear çarpım (mx+b) modüllerinin araya bir ReLu (max(0, x)) fonksiyonu yerleştirilmiş hali olduğu. Biz iki linear çarpım için torch'un nn.Linear modülünü kullanacağız ve Vaswani'nin belirttiği şekilde parametreleri d_ff (FFN networkünün iç boyutu) ve d_model (model vektörü boyutu) olarak set edeceğiz.
İhtiyacımız olan bütün yapılar tamam (açıkça, positional encoding haricinde ve ona halihazırda sahip olduğumuzu varsayalım). Şimdi bunları bağlayıp bir adet "Encoder Block" oluşturabiliriz. Makalemiz N adet encoder ve decoder bloğunun birbirine seri bağlanabileceğini söylüyor. Bu noktada dikkat etmemiz gereken öldürücü nokta Multi-Head Attention bloğuna verdiğimiz Query, Key, Value vektörlerinin birebir aynı olduğu ve 2 defa elimizdeki verinin Residual Connection ile önceki veriyle birleştirilerek beslendiği. Bu Residual Connectionlardan birisi input verisiyle multi-head attention verisi arasındayken diğeri multi-head attention verisi ile FFN verisi arasında yer alıyor. Şimdiye kadar yazdığımız sınıfları birleştirelim ve encoder bloğunu oluşturalım. Ayrıca, bu encoder blocklarını bir liste halinde alıp birbirine bağlayacak bir encoder sınıfı da yazalım.
Encoder'ımız tamam! Normalde bu işin yarısı olurdu ama biz bir decoder'a sahip olmadığımız için yalnızca sınıflandırma amaçlı bir linear layer yazacak, ardından transformer yapımızı oluşturacağız.
Artık her şey hazır, oluşturduğumuz tüm yapıları birbirine bağlayarak transformer'ı kullanabiliriz.
Ben test etmek için basit bir yapı oluşturdum ve ardından modelimin özetini yazdırdım.
Önemli not: Bu blog'daki transformer'ımızda bir decoder bloğu yer almayacak. Classifier amaçlı kullanılacak bir encoder yazacağız.
Vaswani makalesinde, "It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult" cümlesini örnek gösteriyor. Elbette bu kelime cümle alelade seçilmiş bir cümle değil. Hem uzun, hem de arada başka kelimeler bulunan kalıpları içeriyor. Örnek olarak ,,making ... the more difficult'' [daha da zorlaştırıyor] cümlesinin yapay zekalar tarafından anlaşılması oldukça zor, çünkü making eyleminin tanımladığı yapı kendisinden hayli uzakta. Bu noktada her bir kelimeyi, belirli bir ağırlık değeriyle çarpıp birbiri arasındaki çapraz korelasyonu inceleyerek yeni kelime vektörleri üretiriz, bu işlemi yapan yapıya "multi-head attention block" denir ve encoder'ların içinde kullanılır. Çok karışmaması adına matematiğine girmeyeceğim, şimdilik sadece kelimelerin birbirleriyle olasılıksal ilişkisini hesapladığımızı bilmemiz yeterli.
Sadece encoder bloğunu kodlayacağımız (ve, olabildiğince basit bir şekilde. Tamamen apayrı bir yazı olabilecek positional encoding gibi karmaşık yapılara bu yazıda yer vermeyeceğim) için yapının görselini verelim. Tabii ki biz çıkışı bir decoder'a bağlamayacak, classifier layer yazacağız.
Vaswani makalesinde d_k, d_v ve d_model/h isimlendirmelerini farklı yapmış. Biz d_k ve d_v için aynı değişkeni kullanacağız (sonuçta çıktı vektörlerinin boyutları birebir aynı). Bir MultiHeadAttentionBlock sınıfı oluşturalım ve parametrelerimizi tanımlayalım
Python:
class MultiHeadAttentionBlock(nn.Module):
# time_steps = time length
# d_model = size of the embedding vector
# h = number of heads
# d_k = d_v = d_model // h
def __init__(self, d_model : int, h: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.h = h
assert d_model % h == 0, "d_model is not divisible by h"
self.d_k = d_model // h
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)Makalede attention modülü Query (Q) ve Key (K^T) matrislerini çarpıyor ve vektör boyutunun kareköküne böldükten sonra softmax fonksiyonu ile olasılık vektörünü elde ediyor. Ardından bu sonucu Value değerleriyle çarpıyor. Birebir aynı matematiksel işlemi sınıfımıza ekleyelim
Python:
@staticmethod
def attention(query, key, value, mask = None, dropout: nn.Dropout = None):
d_k = query.shape[-1]
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
attention_scores = attention_scores.softmax(dim = -1)
return (attention_scores @ value), attention_scoresArdından elde ettiğimiz vektörleri concate işlemi ile birleştirip çıkış ağırlık matrisi (W_o) ile çarpmamız lazım. Tüm fonksiyonlarımız hazır olduğuna göre işlemi gerçekleyen bir forward modülü yazabiliriz.
Python:
def forward(self, q, k, v, mask):
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1, 2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1, 2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1, 2)
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
return self.w_o(x)Görseli hatırlayacak olursak attention bloğunun çıktılarını bir adet normalizasyon layer'ına bağlıyor, ardından input olarak verilen raw data ile de bu layerı besliyorduk. Çıktıyı normalize edip saf verimizle topladığımız basit bir residual connection block yazalım.
Python:
class ResidualConnection(nn.Module):
#skip connection while feeding the encoder.
def __init__(self, dropout : float) -> None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))Şimdi eksiğimiz olan tek yapı feed forward bloğu oldu. Vaswani bu bloğu makalesinde görseldeki gibi tanımlıyor:
Kabaca söylemek istediği, Feed Forward Network'lerin (FFN) iki adet linear çarpım (mx+b) modüllerinin araya bir ReLu (max(0, x)) fonksiyonu yerleştirilmiş hali olduğu. Biz iki linear çarpım için torch'un nn.Linear modülünü kullanacağız ve Vaswani'nin belirttiği şekilde parametreleri d_ff (FFN networkünün iç boyutu) ve d_model (model vektörü boyutu) olarak set edeceğiz.
Python:
class FeedForwardBlock(nn.Module):
# FFN(x) = max(0, xW1 + b1)W2 + b
def __init__(self, d_model : int, d_ff : int, dropout : float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff) #W1 and B1
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model) #W2 and B2
def forward(self, x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))İhtiyacımız olan bütün yapılar tamam (açıkça, positional encoding haricinde ve ona halihazırda sahip olduğumuzu varsayalım). Şimdi bunları bağlayıp bir adet "Encoder Block" oluşturabiliriz. Makalemiz N adet encoder ve decoder bloğunun birbirine seri bağlanabileceğini söylüyor. Bu noktada dikkat etmemiz gereken öldürücü nokta Multi-Head Attention bloğuna verdiğimiz Query, Key, Value vektörlerinin birebir aynı olduğu ve 2 defa elimizdeki verinin Residual Connection ile önceki veriyle birleştirilerek beslendiği. Bu Residual Connectionlardan birisi input verisiyle multi-head attention verisi arasındayken diğeri multi-head attention verisi ile FFN verisi arasında yer alıyor. Şimdiye kadar yazdığımız sınıfları birleştirelim ve encoder bloğunu oluşturalım. Ayrıca, bu encoder blocklarını bir liste halinde alıp birbirine bağlayacak bir encoder sınıfı da yazalım.
Python:
class EncoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)Encoder'ımız tamam! Normalde bu işin yarısı olurdu ama biz bir decoder'a sahip olmadığımız için yalnızca sınıflandırma amaçlı bir linear layer yazacak, ardından transformer yapımızı oluşturacağız.
Python:
class ClassifierLayer(nn.Module):
# encoder bloklarının çıkışına bağlanacak, output katmanı
def __init__(self, d_model: int, num_classes: int) -> None:
super().__init__()
self.classifier = nn.Linear(d_model, num_classes)
def forward(self, x):
x = x.mean(dim=1)
return self.classifier(x)Artık her şey hazır, oluşturduğumuz tüm yapıları birbirine bağlayarak transformer'ı kullanabiliriz.
Python:
class TransformerClassifier(nn.Module):
def __init__(self, encoder: Encoder, src_pos: PositionalEncoding, classifier_layer: ClassifierLayer, d_model: int, n_mels: int) -> None:
super().__init__()
self.encoder = encoder
self.src_pos = src_pos
self.classifier_layer = classifier_layer
self.input_proj = nn.Linear(n_mels, d_model)
def forward(self, x, mask=None):
x = self.input_proj(x)
x = self.src_pos(x)
x = self.encoder(x, mask)
x = self.classifier_layer(x)
return xBen test etmek için basit bir yapı oluşturdum ve ardından modelimin özetini yazdırdım.
Python:
src_pos = PositionalEncoding(d_model, time_steps, dropout)
encoder_blocks = []
for _ in range(N):
self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
encoder_block = EncoderBlock(self_attention_block, feed_forward_block, dropout)
encoder_blocks.append(encoder_block)
encoder = Encoder(nn.ModuleList(encoder_blocks))
classifier_layer = ClassifierLayer(d_model, num_classes)
transformer = TransformerClassifier(encoder, src_pos, classifier_layer, d_model, n_mels)
return transformer
Bash:
print(summary(get_model(config)))
S C:\Users\Hacknology\tht\EmotionDetectionFromSpeech> python .\main.py
================================================================================
Layer (type:depth-idx) Param #
================================================================================
TransformerClassifier --
├─Encoder: 1-1 --
│ └─ModuleList: 2-1 --
│ │ └─EncoderBlock: 3-1 33,220
│ │ └─EncoderBlock: 3-2 33,220
│ └─LayerNormalization: 2-2 2
├─PositionalEncoding: 1-2 --
│ └─Dropout: 2-3 --
├─ClassifierLayer: 1-3 --
│ └─Linear: 2-4 390
├─Linear: 1-4 4,160
================================================================================
Total params: 70,992
Trainable params: 70,992
Non-trainable params: 0
================================================================================")

