


---> DATA LITERACY <---
VERİ OKURYAZARLIĞI

Alt başlıklar;
Veri nedir?
Popülasyon, örneklem
Gözlem birimi
Değişkenler ve değişken türleri
Ölçek türleri
M.E.Ö Aritmetik ortalama
M.E.Ö Medyan
M.E.Ö Mod
M.E.Ö Kartiller
M.E.Ö Merkezi eğilimin önemini anlamak
D.Ö Değişim aralığı
D.Ö Standart sapma
D.Ö Varyans
D.Ö Çarpıklık
D.Ö Basıklık
İstatistiksel Düşünce Modelleri
Verinin tanımlanması
Verinin organize edilmesi ve indirgenmesi
Verinin gösterimi
Verinin analiz edilmesi ve yorumlanması
Merhaba dostlarım, bu gün sizlere "istatistik,veri bilimi,veri analizi" gibi popüler alanlarda temelde olan ve başlı başına öğrenilmesi gereken bir konu olan "Veri okuryazarlığı"na değineceğim.
Bu konuyu anlatmak istemem; ister bu alanlarda bilgi sahibi olmak isteyin, isterseniz hiç ilgilenmeyin ancak veriler nasıl işlenir, nasıl okunur, nasıl yorumlanır, bunların bilinmesi gerektiğini düşünmemdir.
Böylelikle; sosyal medyada, haberlerde,forumlarda vb. yerlerde yayınlanan verilerin, istatistiklerin doğruluğuna %100 güvenmemeyi ve kendi istatistiklerinizi çıkarmayı öğrenmiş olacaksınız.
Veri okuryazarlığına geçmeden önce “veri nedir?” başlığına değinmek istiyorum.
VERİ (DATA) NEDİR?

Bilgisayar bilimindeki tanımı ile; bilgisayar ortamında bulunan bilgilerin, programlar tarafından işlenebilmesini sağlamak amacı ile derlenmiş ve formüle edilmiş şekline veri denir. Bu kavram genellikle enformasyon alanında kullanılan bir terimi ifade etmek için kullanılır.
Ancak veri(data) kavramı çok geniş bir alanı kapsamaktadır. Araştırmalardan, gözlemlerden, sosyal medya ve internetten vb. farklı alanlardan elde edilen genel bir terimdir. Hemen hemen hayatımızın her alanında verilerden yararlanabiliriz.
Veri okuryazarlığı alanında veri türlerini kısaca;
> Sayısal Veri
> Alfanümerik / Karakter Veri
> Mantıksal Veri
olarak adlandırabiliriz.
Veri nedir kısaca bahsettik.
Peki, Veri okuryazarlığı (Data Literacy) nedir?
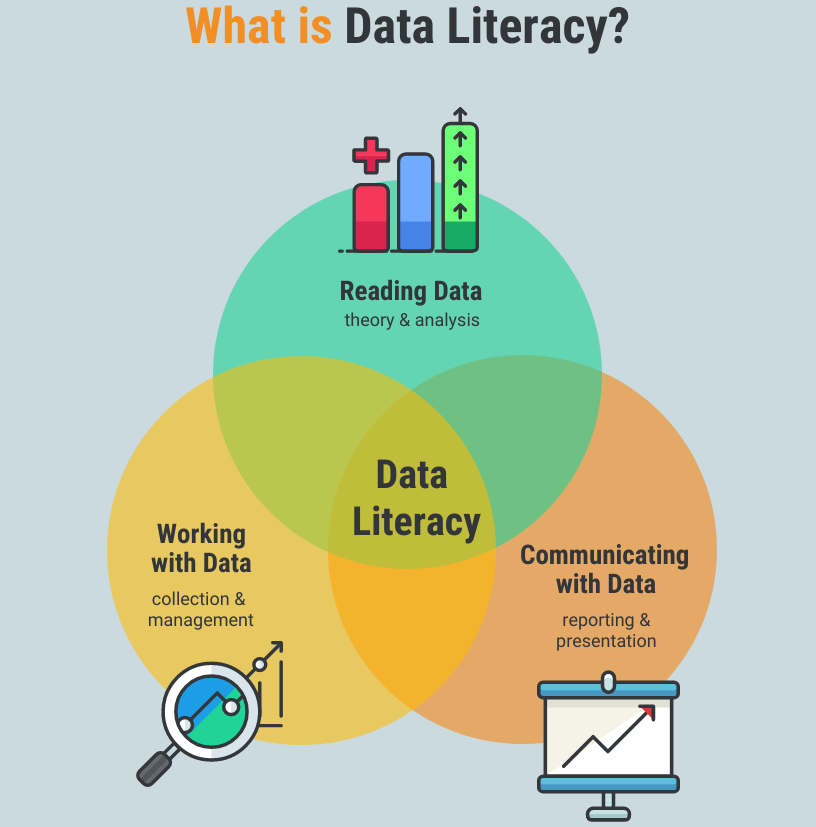
Data Literacy; her türden veri tipini,değişken ve ölçek türlerini tanımlayabilme,betimsel istatistikleri ve istatistiksel grafikleri kullanarak veriyi değerlendirebilme yeteneğidir.
Jordan Morrow’un tanımı ile ;” Veriler değerlidir, ancak tıpkı petrol gibi insanlardan geçmelidir ve değer kazanması için arıtılması gerekir. Bu veri okuryazarlığıdır.
Data Literacy için temel kavramlara değinelim.
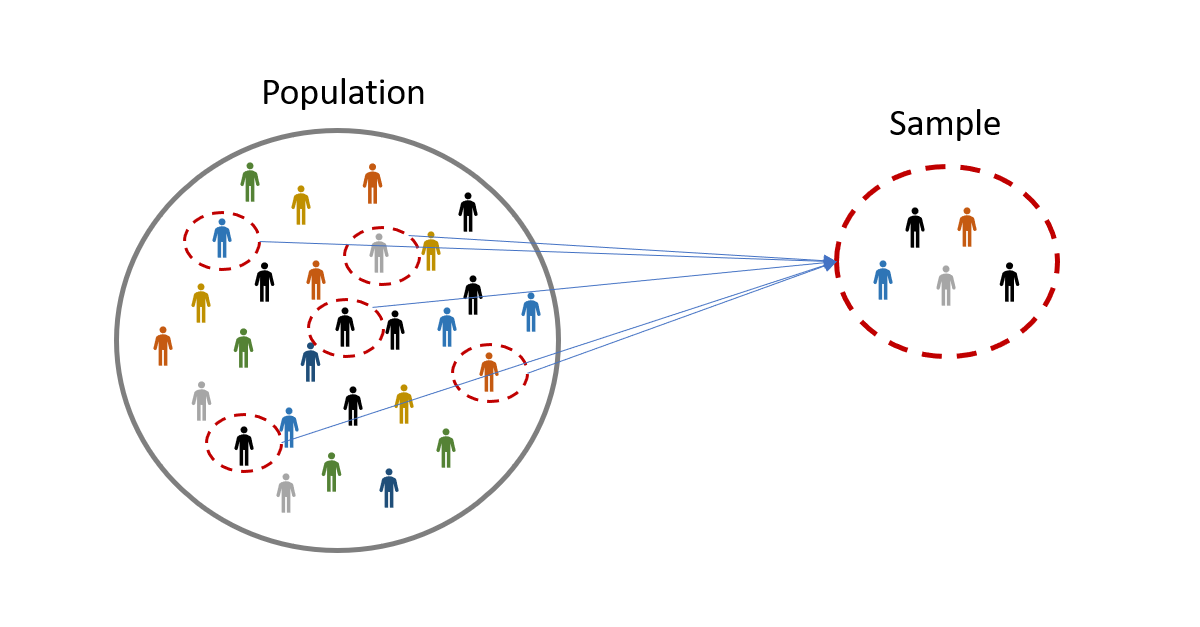
Population and Sample(Popülasyon ve Örneklem):
- Üzerinde çalışılan tüm gruba ya da istatistiksel sonuçların genelleştirileceği gruba kitle denir.Örneklem ise bu seçilen anakitlenin alt kümesi diyelibiliriz.
- Yani kısaca; Verinin tamamına popülasyon, bu veriyi temsil eden alt kümeye de örneklem denir.
- Burada esas olan durum, örneklemin popülasyonu tam anlamıyla temsil etmesi gerekmesidir. Sebebi ise, iş bittiğinde biz bu örneklemi popülasyonun kendisiymiş gibi kullanabilmeliyiz.
Parametre:
- Bir kitlenin tanımlayıcı sayısal ölçüsüdür.
- Bir örneklemin tanımlayıcı sayısal ölçüsüdür.
- Araştırma esnasında incelenen birimlerdir diyebiliriz. Örneklem(temsilci kitle)’in içerisindeki herbir elemana “gözlem birimi” denir.
- Kısaca birimlerin farklı değerler alabildikleri nitelik veya niceliklerine değişken denir. Değişken türlerini ise yapay zeka alanında ikiye ayırabiliriz.
Bunlar;
- Sayısal Değişkenler(Nicel, Kantitatif) , Katagorik Değişkenler(Nitel, Kalitatif) dir.
- Kısaca bir değişkenin değerini ölçümlemek olarak adlandırabiliriz. Bunuda yine ikiye ayıracağız.
Bunlar;
- Sayısal değişkenler için ölçekler; Aralık, Oran , Katagorik değişkenler için ölçekler; Nominal, Ordinal
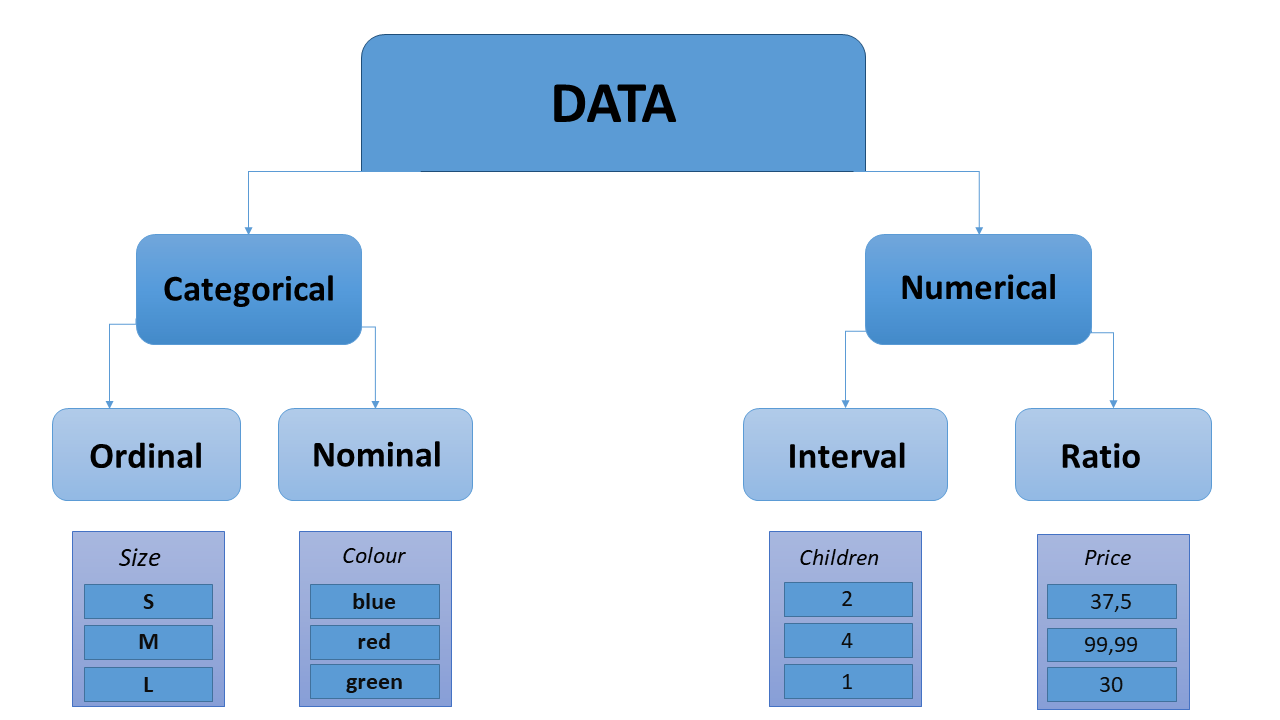
Nedir bunların meali;
1-Sınıflayıcı (Nominal) Ölçek: Ortak özelliklere göre alt gruplara ayrılma (eşit-eşit değil). Cinsiyet, medeni durum, hastalığın var olup olmaması vb. durumları örnek gösterebiliriz.
2-Sıralayıcı (Ordinal) Ölçek: Ölçme sonuçlarını sıralayabilmeye dayanmaktadır. Örneğin, bir online alışveriş sitesinin memnuniyet derecesinde sıralayıcı ölçek kullanılır.
3-Aralık (İnterval) Ölçek: Ölçme birimleri arasındaki farkların eşit olduğu durumlarda kullanılır. Eşit aralıklı ölçek düzeyindeki bir değişkende ‘izafi/göreli/yapay/sıfır’ ya da ‘izafi başlangıç noktası’ tanımlıdır. Bu nokta mutlak yokluğu ifade etmez. Verilerle doğrudan çarpma-bölme gibi işlemler bir anlam ifade etmez, bu ölçekte değişkenler arasındaki farklar önemlidir. Örneğin, 150°C her zaman 100°C’den daha yüksektir ve bu iki sıcaklık arasındaki fark 80°C ile 30°C arasındaki farka eşittir.
4-Oran (Ratio) Ölçek: Eşit oranlı ölçeklerde birimler eşittir ancak sıfır mutlak olmalıdır. Sıfırın anlamlı olduğu bilinmelidir. Örneğin; metre ile yapılan ölçümler, kilo ile yapılan ölçümler, hasta sayısı, hız, gelir gibi değişkenler bu ölçme düzeyinde ölçülmektedir
Evet, şimdide biraz işin matematiğine değineceğim. Matematik dediğime bakmayın, liseden veya ortaokuldan bildiğimiz formüller
")
Merkezi eğilim ölçüleri – Arithmetic Mean (Aritmetik Ortalama):
Elde bulunan verilerin toplamının veri sayısına bölünmesi ile ortaya çıkan sayıya denir.

1.formül "Anakütle" aritmetik ortalama formülü ike 2.formül "Örneklem" aritmetik ortalama formülüdür.
Merkezi eğilim ölçüleri – Median (Medyan):
Bir seriyi(değişkeni) küçükten büyüğe veya büyükten küçüğe sıraladığımızda tam orta noktadan seriyi iki eşit parçaya ayıran değere denir.
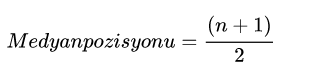
Merkezi eğilim ölçüleri – Mode (Mod):
Bir seride(değişkende) en çok tekrar eden değere denir.
Merkezi eğilim ölçüleri – Quartiles (Kartiller):
Küçükten büyüğe doğru sıralanan bir seriyi(değişkeni) 4 parçaya ayıran değere denir.
Hem eğilim hemde dağılım ölçülerinde kullanılır.

Dağılım ölçüleri – Range (Değişim Aralığı):
Bir seride(değişkende) maximum değerden minimum değeri çıkardığımızda bulduğumuz değerdir.
Dağılım ölçüleri – Standard Deviation (Standart Sapma):Ortalamadan olan sapmaların genel bir ölçüsü diyebiliriz.
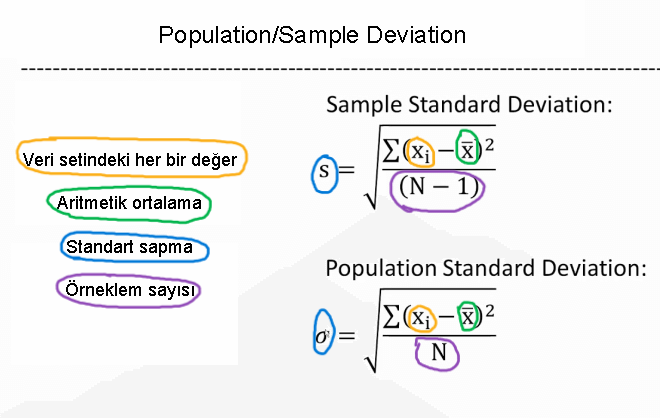
Dağılım ölçüleri – Variance (Varyans):
Bu değer, standart sapmanın karesidir. Ortalamadan olan sapmaların karelerinin ortalamasıdır.
Yukarıdaki formülün karesini alabilirsiniz.
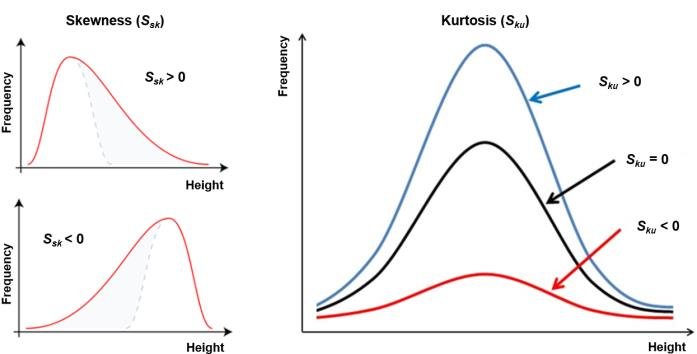
Dağılım ölçüleri – Skewness (Çarpıklık):Çarpıklık, bir değerin dağılımının simetrik olamayışıdır.
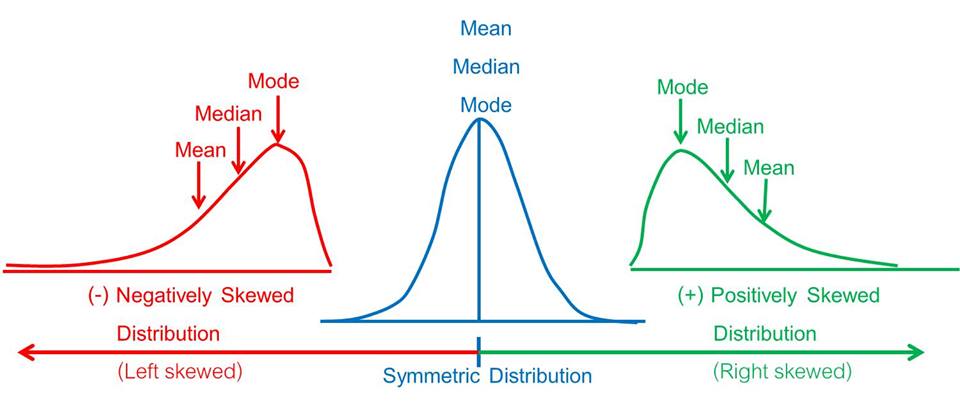
Dağılım ölçüleri – Kurtosis (Basıklık):Dağılımın basıklığını/sivriliğini gösterir.
Skewness(çarpıklık) 0'dan büyük olduğunda "Positive kurtosis"
Skewness(çarpıklık) 0'a eşit olduğunda "Normal distribution"
Skewness(çarpıklık) 0'dan küçük olduğunda "Negative kurtosis" gözlemlenir.
Biliyorum, bu iş matematik gerektiriyor ancak matematik olmadan da birşey olmuyor dostlarım.
Şimdi ise diğer bir başlığımız olan "İstatistiksel düşünce modelleri" konusuna biraz değineceğim.
İstatistiksel Düşünce Modelleri (Statistical Thinking Models)

Kısaca, veri okuryazarlığından veri analitiğine giden yolu modelleyen yol göstericilerdir.
Bir başka açıklamayla ise; analitik düşünme becerilerini veri analitiği kapsamında belirli bir programatik şema ile ele alınmasını sağlayan teorik modellerdir.
- Ben- Zvi ve Friedlander (1997)
- Jones ve diğerleri (2000)
- Wild ve Pfannkuch (1999)
- Hoerl ve Snee (2001)
- Mooney (2002)
Bu model 4 basamaktan oluşuyor.
- Veri tanımlaması
- Verinin organize edilmesi ve indirgenmesi
- Verinin gösterimi
- Verinin analiz edilmesi ve yorumlanması
2-)Verinin organize edilmesi ve indirgenmesi; karmaşık ve henüz işleme uğramamış veri yığınlarını, anlaşılır ve yorumlanabilir sonuçlara dönüştürme bölümüdür diyebiliriz.
3-)Verinin gösterimi; eldeki verilerin grafiksel olarak, ister teknik ister amaca yönelik, yorumlanabilir bir biçimde gösterilmesi bölümüdür.
4-)Verinin analiz edilmesi ve yorumlanması; şu ana kadar gösterilen ve anlatılan konuların toplandığı, gerçek hayat senaryolarında verilerin geçirdiği son evre olan ve artık bir sonuca varılan bölümdür.
------------- S O N -------------
Evet dostlarım, bu makaleninde sonuna geldik.
Değerli bir alan olduğunu düşünüyorum ve herkesin bundan faydalanmasını ve daha detaylı araştırmasını isterim.
Yavaş yavaş "Yapay Zeka" temellerine doğru ilerleriz vaktim olursa.
Teşekkürler...
------------- S O N -------------