




Merhaba konuya başlamadan önce diğer veri analizi ve zaman serisi konularıma göz atabilirsiniz.
Python Regresyon
Regresyon, bağımlı bir değişken ile bir veya daha fazla bağımsız değişken arasındaki ilişkiyi modellemek için kullanılan bir istatistiksel yöntemdir. Genellikle sürekli bir hedef değişkeni tahmin etmek için kullanılır. Regresyon analizinde amaç veri setine en uygun olan doğrusal ya da...
www.turkhackteam.org
Python Mann Kendall Trend Test
Merhaba herkese, Bugün bir zaman serisi içerisindeki trendin varlığından bahsedebilmemiz için kullanabileceğimiz istatiksel bir test yapısından bahsedeceğiz.Süreçler ve zaman serileri birden fazla testler ile test edilebilir ama bizz bugün ki konumuzda Mann-Kendall Trend Test testinden...
www.turkhackteam.org
Ekonomi ve finans literatüründe değişkenler arasındaki uzun vadeli ilişkilerin analiz edilmesi sıklıkla gereklidir. Bu tür analizler ekonomik göstergeler gibi zaman serisi verileri üzerinde çalışan araştırmacılar ve analistler için oldukça değerlidir.
Zaman serisi analizi genellikle belirli değişkenlerin zaman içindeki hareketlerini ve birbirleriyle olan ilişkilerini anlamak için kullanılır. Bu bağlamda, Vektör Hata Düzeltme Modeli (VECM), koentegrasyon ilişkisi olan zaman serisi verileriyle çalışmak için oldukça güçlü bir araçtır.
Bu konumuzda Python kullanarak VECM modellemesi üzerinde derinlemesine bir inceleme yapacağız.
Öncelikle VECM'nin teorik temellerini açıklayacağız, ardından Python programlama dili ve ilgili kütüphanelerle nasıl uygulanabileceğini ayrıntılı olarak ele alacağız. Aynı zamanda, VECM'nin ekonometrik bağlamdaki önemi, veri hazırlama süreçleri ve sonuçların yorumlanması gibi konulara da değineceğiz.
Zaman Serisi Analizi ve VECM’nin Teorik Temelleri
1-Zaman Serisi Analizi
Zaman serisi analizi belirli bir değişkenin geçmişteki değerlerine bakarak gelecekteki hareketlerini tahmin etmeye yönelik bir disiplindir. Birçok ekonomik gösterge, hisse senedi fiyatları, GSYH, döviz kurları ve benzeri veriler zaman serisi analizine konu olur. Bu tür analizlerde, değişkenlerin zaman içindeki davranışlarını anlamak kadar, birbirleriyle olan ilişkilerini incelemek de önemlidir.
2-Durağanlık ve Fark Alma İşlemi
Zaman serisi analizinin ilk adımı, verilerin durağan olup olmadığını belirlemektir. Durağan bir zaman serisi, ortalaması ve varyansı zamanla değişmeyen bir seri olarak tanımlanır. Eğer bir zaman serisi durağan değilse, genellikle fark alma işlemi uygulanarak durağan hale getirilir. Ancak, bazı seriler arasındaki ilişkiler, uzun vadede durağan olmayan seriler arasında bile olabilir. Bu gibi durumlarda koentegrasyon ve hata düzeltme modelleri devreye girer.
3-Koentegrasyon
İki ya da daha fazla zaman serisinin aynı yönde uzun vadeli bir ilişkiye sahip olduğu durumlarda, bu seriler koentegredir. Koentegrasyon, seriler arasındaki kısa vadeli sapmaların zamanla geri döneceği anlamına gelir. Koentegrasyon ilişkisine sahip zaman serileri, uzun vadede birlikte hareket ederler, bu nedenle bu tür ilişkiler ekonometrik modellemelerde önemli bir yer tutar.
4-Vektör Otoregresif (VAR) Modeller
VECM Vektör Otoregresif Model (VAR) ile yakından ilişkilidir. VAR modeli birden fazla zaman serisi değişkeninin geçmiş değerlerine dayalı olarak birbirlerini nasıl etkilediğini analiz etmek için kullanılır.
Ancak VAR modeli sadece durağan zaman serileriyle çalışabilir. Koentegrasyon ilişkisi olan seriler için, bu model yetersiz kalır ve VECM modeli tercih edilir.
5-Vektör Hata Düzeltme Modeli (VECM)
VECM koentegre zaman serileri arasında uzun vadeli dengeyi modelleyen bir yaklaşımdır. VECM, seriler arasındaki kısa vadeli dalgalanmaları ve uzun vadeli denge ilişkilerini aynı anda modellemek için kullanılır.
Kısa vadeli sapmaların düzeltilmesi, modelin temelini oluşturur. Bu sapmaların düzeltilmesi "hata düzeltme" terimiyle ifade edilir. VECM modeli, uzun vadeli denge ilişkisi olan değişkenler arasındaki kısa vadeli dinamikleri incelemek için idealdir.
Pythonda Zaman Serisi Analizi İçin Gerekli Kütüphaneler
Python zaman serisi analizinde kullanılabilecek birçok güçlü kütüphane sunar. VECM modellemesi için başvurulacak temel kütüphaneler şunlardır:
- pandas: Veri işleme ve zaman serisi manipülasyonu için kullanılır.
- numpy: Matematiksel işlemler ve matris hesaplamaları için kullanılır.
- statsmodels: İstatistiksel modelleme ve ekonometrik analizler için önemli bir kütüphanedir.
- matplotlib: Grafikler ve görselleştirme için kullanılır.
- arch: Zaman serisi modelleri ve GARCH modellemeleri için yararlı bir kütüphanedir.
Bu kütüphaneleri kurmak için:
Kod:
pip install pandas numpy statsmodels matplotlib archKomutunu kullanabiliriz.
VECM Modeline Uygun Veri Seti
VECM modeli koentegrasyon ilişkisi olan birden fazla değişkenle çalışır. Ekonomik göstergeler, döviz kurları, hisse senedi fiyatları gibi veri setleri VECM analizi için uygun olabilir. Örneğin, döviz kuru ile enflasyon arasındaki ilişkiyi analiz etmek için kullanılabilir.
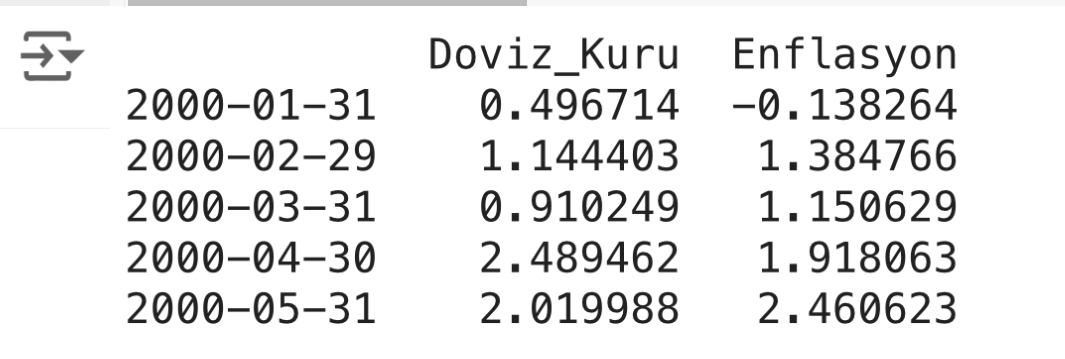
Aşağıda örnek bir veri seti oluşturalım
Python:
import pandas as pd
import numpy as np
np.random.seed(42)
dates = pd.date_range('2000-01-01', periods=100, freq='M')
data = np.random.randn(100, 2).cumsum(axis=0)
df = pd.DataFrame(data, columns=['Doviz_Kuru', 'Enflasyon'], index=dates)
print(df.head())Çıktı:
Koentegrasyon Testi (Johansen Testi)
VECM modellemesine başlamadan önce, serilerin koentegre olup olmadığını test etmek gerekir. Bu amaçla Johansen testi kullanılır. Johansen testi, birden fazla değişken arasında kaç tane koentegrasyon ilişkisi olduğunu belirler.
Python'da Johansen testi yapmak için statsmodels kütüphanesi kullanılabiliriz.
Örnek kod parçası:
Python:
from statsmodels.tsa.vector_ar.vecm import coint_johansen
def johansen_test(data, det_order=0, k_ar_diff=1):
test_result = coint_johansen(data, det_order, k_ar_diff)
return test_result
"""Koentegrasyon testi"""
johansen_test(df)Johansen testi sonuçlarına göre seriler arasında koentegrasyon varsa VECM modeli uygulanabilir. Test sonuçlarına göre koentegrasyon sayısı belirlenir ve VECM modeline bu bilgi dahil edilir.
VECM Modelinin Kurulması
Koentegrasyon testinin ardından VECM modelini kurmak için statsmodels kütüphanesindeki VECM sınıfı kullanılır. VECM koentegrasyon ilişkisini dikkart alarak kısa vadeli dinamikleri modellemeye olanak tanır
Python:
from statsmodels.tsa.vector_ar.vecm import VECM
#VECM modelinin kurulması
vecm = VECM(df, k_ar_diff=1, coint_rank=1)
vecm_fitted = vecm.fit()
#Model sonuçları
print(vecm_fitted.summary())Model Sonuçlarının Yorumlanması
VECM modelinin çıktılarını yorumlamak modelin anlaşılması için oldukça önemlidir. Çıktılar arasında uzun vadeli ilişkiyi gösteren parametreler, kısa vadeli dinamikleri açıklayan katsayılar ve hata düzeltme mekanizması yer alır
- Koentegrasyon Parametreleri Seriler arasındaki uzun vadeli ilişkiyi gösterir.
- Kısa Vadeli Parametreler: Değişkenlerin kısa vadede birbirleri üzerindeki etkilerini gösterir.
- Hata Düzeltme Terimi: Uzun vadeli dengeye dönüş hızını temsil eder. Bu terimin katsayısı negatif ve anlamlı olmalıdır
Modelin Doğrulama ve Test Süreçleri
VECM modelinin performansını değerlendirmek ve sonuçların güvenilir olup olmadığını test etmek için çeşitli teknikler kullanılır.Bunlar:
1-Artık Analizi
Modelin artıkları (residuals) incelenerek modelin hatalarının dağılımı kontrol edilir. İdeal olarak modelin artıkları beyaz gürültü şeklinde olmalıdır, yani normal dağılıma sahip olmalı ve otokorelasyon içermemelidir.
Python:
import matplotlib.pyplot as plt
#Artıkların çizimi
residuals = vecm_fitted.resid
plt.plot(residuals)
plt.title('Artıkların Zamanla Dağılımı')
plt.show()2-Granger Nedensellik Testi
VECM modeli değişkenlerin birbirleri üzerindeki etkilerini kısa vadede nasıl anlamlı bir şekilde açıklayabileceğimizi araştırmamıza yardımcı olur. Granger nedensellik testi, bir değişkenin diğerini anlamlı bir şekilde tahmin edip edemeyeceğini kontrol eden bir istatistiksel testtir.
VECM modeli Granger nedensellik ilişkisini de inceler ve bir değişkenin diğer değişkeni kısa vadede etkileyip etkilemediğini gösterir.
Granger nedensellik testi için statsmodels kütüphanesini kullanabiliriz. Örnek kullanım:
Python:
from statsmodels.tsa.stattools import grangercausalitytests
#Granger nedensellik testi
granger_test = grangercausalitytests(df, maxlag=2)Bu testin sonuçlarına bakarak hangi değişkenin diğerini kısa vadede etkilediğini anlayabiliriz. Granger nedenselliği test etmek, özellikle kısa vadede karar verme süreçlerinde faydalıdır.
VECM Modeli Sonrası Tahmin ve Simülasyonlar
VECM modeli kurulduktan ve sonuçları incelendikten sonra bu model ile gelecekteki veri noktalarını tahmin edebiliriz. Tahminler hem kısa vadeli hem de uzun vadeli tahminler olabilir. VECM’nin koentegrasyon ilişkisi, uzun vadeli tahminlerde daha etkili olurken, kısa vadeli dinamikler ise tahminlerin hassasiyetini artırır.
1-VECM Modeli ile Tahmin
VECM modeli ile gelecekteki veri noktalarını tahmin etmek için aşağıdaki kodu kullanabiliriz:
Python:
#Gelecekteki 10 dönem için tahmin yapma
forecast = vecm_fitted.predict(steps=10)
print(forecast)Tahmin edilen değerler modelin kısa ve uzun vadeli ilişkilerine dayalı olarak hesaplanır Bu tahminler özellile ekonometrik tahminler veya finansal zaman serisi analizi için oldukça değerlidir.
2-VECM Tahminlerinin Görselleştirilmesi
Tahmin edilen sonuçları görselleştirerek modelin gelecekteki hareketleri nasıl öngördüğünü gözlemleyebiliriz. Bu sonuçların daha anlaşılır hale gelmesini sağlar.
Python:
#Gerçek ve tahmin edilen değerlerin karşılaştırılması
plt.plot(df.index[-10:], df.values[-10:], label='Gerçek Değerler')
plt.plot(pd.date_range(df.index[-1], periods=10, freq='M'), forecast, label='Tahmin Edilen Değerler')
plt.legend()
plt.title('Gerçek ve Tahmin Edilen Değerler')
plt.show()Bu modelleme ile son 10 veri noktasıyla modelin gelecekteki 10 veri noktası tahminleri karşılaştırılır. Tahmin edilen değerlerin zamanla nasıl hareket ettiği incelenebilir.

VECM modeli sadece tahmin yapmakla sınırlı kalmaz ileri düzeyde finansal analizlerde veya makroekonomik modellemelerde VECM çeşitli stratejik kararlar için kullanılabilir. Özellikle döviz piyasaları hisse senedi piyasaları veya makroekonomik göstergeler gibi alanlarda, VECM uzun vadeli denge ilişkilerini yakalarken kısa vadeli tahminler de sunar.
Finansal piyasalarda VECM modelinin çıktılarıi döviz kuru veya hisse senedi fiyatları gibi değişkenler arasındaki ilişkiyi anlamak ve buna göre stratejik kararlar almak için kullanılabilir. Örneğin, VECM kullanarak döviz kuru ve faiz oranları arasındaki uzun vadeli ilişkiyi anlayarak, uygun risk yönetimi stratejileri geliştirilebilir.
Şok Analizi (Impulse Response Analysis)
VECM modeli bir değişkende meydana gelen ani bir şokun diğer değişkenler üzerindeki etkisini analiz etmek için de kullanılabilir. Bu analiz finansal piyasalarda veya ekonomik analizlerde büyük önem taşır. Örneğin döviz kurlarında meydana gelen ani bir değişikliğin enflasyon üzerinde nasıl bir etkisi olduğunu incelemek, politika yapıcılar için önemli bilgiler sunar.
Python'da şok analizi yapmak için aşağıdaki adımlar izlenir:
Python:
#Şok analizi (Impulse Response Function)
irf = vecm_fitted.irf(10)
irf.plot(orth=False)
plt.show()Bu kod ile yapılacak modellemede belirli bir değişkende meydana gelen bir şokun diğer değişkenler üzerindeki etkisi zamanla nasıl geliştiği gösterilir. Şok analizleri özellikle makroekonomik modellemelerde, değişkenlerin kısa ve uzun vadede birbirlerine nasıl tepki verdiğini anlamak için kullanılır.
Varyans Ayrıştırması (Variance Decomposition)
Varyans ayrıştırması bir değişkenin toplam varyansının diğer değişkenlerin katkılarıyla nasıl açıklandığını gösterir. Bu yöntem hangi değişkenin diğerleri üzerindeki etkisinin daha baskın olduğunu anlamamıza yardımcı olur. VECM modelinde varyans ayrıştırması, özellikle uzun vadeli tahminlerde hangi faktörlerin daha önemli olduğunu anlamak için kullanılır.
Python:
#Varyans ayrıştırması
fevd = vecm_fitted.fevd(10)
fevd.plot()
plt.show()Bu kod ile yapılacak analizin zamanla bir değişkenin varyansının ne kadarının diğer değişkenler tarafından açıklandığını görebiliriz. Örneğin döviz kuru varyansının ne kadarının enflasyon faiz oranları veya diğer makroekonomik değişkenler tarafından açıklandığını analiz edebiliriz.
Model Performansının İyileştirilmesi
VECM modeli teorik olarak güçlü bir model olmasına rağmen pratikte modelin performansını artırmak için birkaç yöntem kullanabiliriz.
1-Model Seçimi ve Parametre Optimizasyonu
VECM modelindeki gecikme sayısı (lag) modelin performansını doğrudan etkiler. Modelin gecikme sayısı veri setinin yapısına uygun olarak optimize edilmelidir. Bunun için çeşitli bilgi kriterleri kullanılarak en uygun gecikme sayısı seçilebilir. Python'da aic, bic veya hqic gibi kriterler kullanılarak optimal gecikme sayısı bulunabilir.
Python:
#Optimal gecikme sayısının bulunması
from statsmodels.tsa.vector_ar.vecm import select_order
lag_order = select_order(df, maxlags=10, trend='c')
print(lag_order.summary())Bu komut ile elde edilen sonuçlar modelin en iyi performansı göstereceği gecikme sayısını belirlememize yardımcı olur.
2-Modelin Yeniden Eğitilmesi ve Güncellenmesi
Zaman serisi verileri sürekli değiştiği için modelin performansını koruyabilmek adına VECM’in düzenli olarak yeniden eğitilmesi gerekebilir. Özellikle finansal veri analizlerinde, piyasalardaki ani değişiklikler veya ekonomik koşullardaki dönüşümler modelin doğruluğunu etkileyebilir. Bu nedenle modeli periyodik olarak yeniden eğitmek ve güncellemek tahmin performansını artırmak için önemlidir.
Şimdi güzel bir örnekle konuyu sonlandıralım
Python:
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.vector_ar.vecm import coint_johansen, VECM
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.vector_ar.vecm import select_order
from statsmodels.tsa.stattools import grangercausalitytests
#Yüksek çözünürlükte grafikler
plt.rcParams['figure.dpi'] = 100
#verilerin Çekilmesi (Microsoft ve Google)
symbols = ['MSFT', 'GOOGL']
data = yf.download(symbols, start="2020-01-01", end="2024-09-01")['Adj Close']
#Verilere göz atalım
print(data.tail())
#Birinci farkları alarak serileri durağan hale getiriyoruz
data_diff = data.diff().dropna()
#Farklandırılmış verilerin grafiği
data_diff.plot(title="Birinci Farklandırılmış Kapanış Fiyatları")
plt.show()
#Johansen Koentegrasyon Testi Fonksiyonu
def johansen_test(df, significance_level=0.05):
result = coint_johansen(df, -1, 1)
traces = result.lr1
cvts = result.cvt[:, 1] # 5% significance level
for col, trace, cvt in zip(df.columns, traces, cvts):
print(f'Koentegrasyon testi: {col} - Test istatistiği: {trace:.2f}, Kritik değer: {cvt:.2f}')
if trace > cvt:
print(f'{col} için koentegrasyon var.')
else:
print(f'{col} için koentegrasyon yok.')
#Koentegrasyon Testini Uygulama
johansen_test(data)
#Optimal gecikme sayısını buluyoruz
lag_order = select_order(data_diff, maxlags=10, deterministic='ci')
print(lag_order.summary())
#VECM modelini kuruyoruz
vecm = VECM(data_diff, k_ar_diff=lag_order.aic, coint_rank=1, deterministic="ci")
vecm_fitted = vecm.fit()
print(vecm_fitted.summary())
#Granger Nedensellik Testi
granger_test = grangercausalitytests(data_diff, maxlag=2)
#Gelecekteki 10 dönem için tahmin yapma
forecast = vecm_fitted.predict(steps=10)
#Tahmin edilen ve gerçek değerlerin grafiği
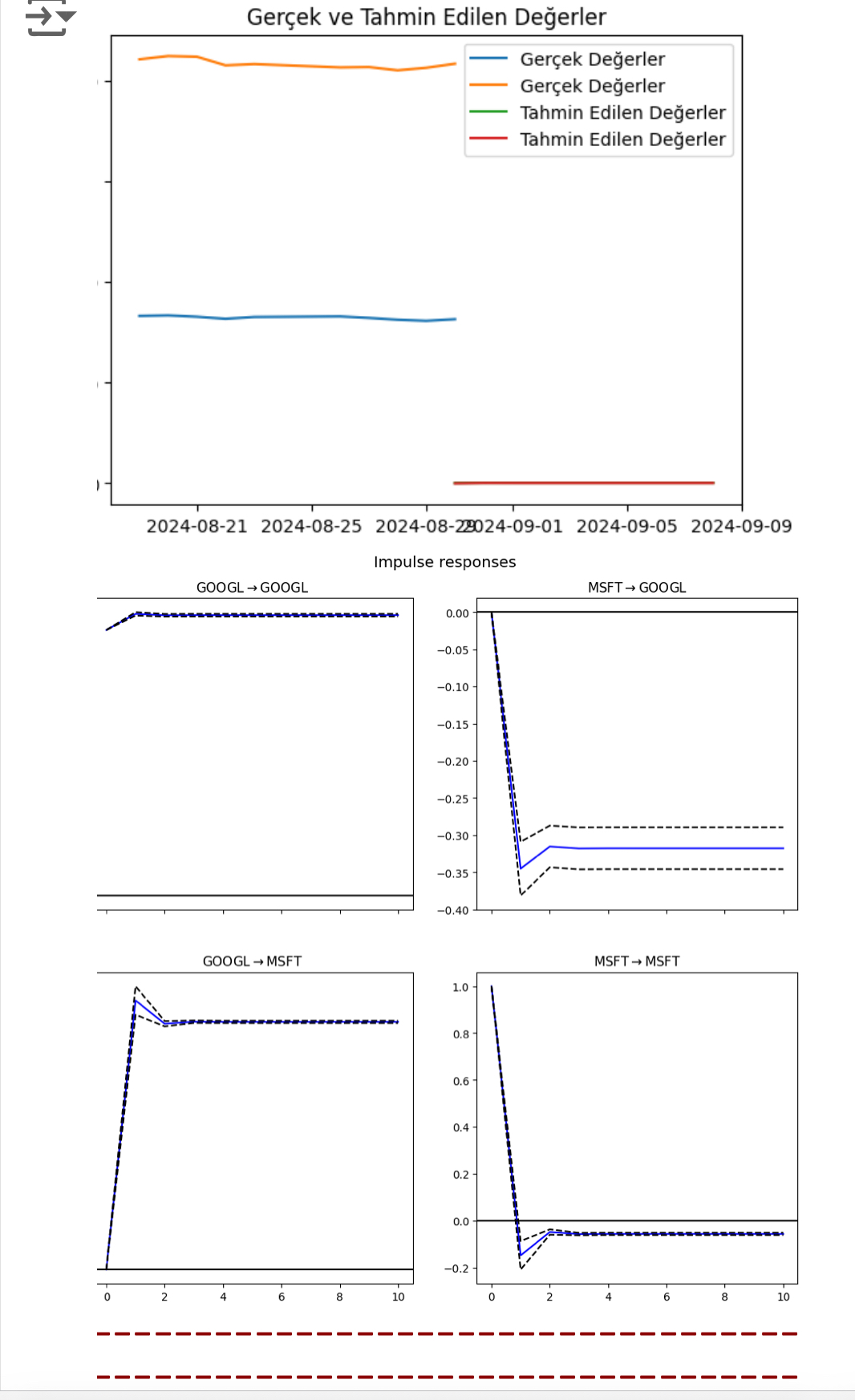
plt.plot(data.index[-10:], data.values[-10:], label='Gerçek Değerler')
plt.plot(pd.date_range(data.index[-1], periods=10, freq='D'), forecast, label='Tahmin Edilen Değerler')
plt.legend()
plt.title('Gerçek ve Tahmin Edilen Değerler')
plt.show()
#Şok analizi
irf = vecm_fitted.irf(10)
irf.plot(orth=False)
plt.show()
#Varyans ayrıştırması
fevd = vecm_fitted.fevd(10)
fevd.plot()
plt.show()Çıktı:
Pekiiii bu örnekte ne yaptık onu da anlatsana be adam dediğinizi duyar gibiyim.. Madde madde sırasıyla açıklayalım
1- Veri Çekme
Öncelikle yfinance kütüphanesini kullanarak Microsoft (MSFT) ve Google (GOOGL) hisse senetlerinin kapanış fiyatlarını 2020-2024 yılları arasındaki dönemde çektik. Bu iki şirketin hisse senetleri üzerinden güncel verileri alarak analizimizi başlattık
2-Zaman Serisini Durağan Hale Getirme (Farklandırma)
Zaman serisi verilerinde modelleme yapabilmek için serilerin durağan olması gerekir. Bu nedenle kapanış fiyatlarının birinci farkını aldık. Bu işlem, serilerdeki trend ve mevsimsellik etkilerini ortadan kaldırarak serileri durağan hale getirmeyi amaçladı. Durağanlık zaman serisi analizinde önemli bir adımdır çünkü yalnızca durağan seriler üzerinde etkili tahmin modelleri kurulabilir.
3-Koentegrasyon Testi (Johansen Cointegration Test)
Koentegrasyon, iki veya daha fazla zaman serisi arasında uzun dönemli bir ilişki olup olmadığını gösterir. Microsoft ve Google hisse senetlerinin fiyatları arasında koentegrasyon olup olmadığını test ettik. Johansen testiyle bu seriler arasında uzun vadeli bir denge ilişkisi olup olmadığını kontrol ettik. Eğer koentegrasyon varsa, bu seriler birlikte hareket eder; yani birindeki uzun vadeli değişiklik diğerini etkiler.
4-VECM Modeli Kurulumu
Koentegrasyon tespit edildikten sonrak VECM modelini kurduk. VECM koentegrasyon ilişkisi olan serilerde kısa vadeli sapmaları ve uzun vadeli denge ilişkisini modellemek için kullanılır. Modeli kurmadan önce optimal gecikme sayısını belirledik. Bu gecikme sayısı, modelde kaç zaman adımı geriye gidileceğini gösterir ve doğru gecikme sayısını seçmek modelin doğruluğunu artırır.
5-Granger Nedensellik Testi
Granger nedensellik testi ile seriler arasındaki kısa vadeli nedenselliği test ettik. Yani, bir değişkenin diğerini kısa vadede etkileyip etkilemediğini inceledik. Örneğin Microsoft hisselerindeki bir hareketin Google hisselerini kısa vadede etkileyip etkilemediğini bu test ile kontrol ettik.
6-Tahmin (Forecasting)
VECM modelini kullanarak gelecekteki 10 dönem için hisse senedi fiyatlarını tahmin ettik. Tahmin edilen değerleri gerçek değerlerle kıyaslayarak modelin performansını gözlemledik. Bu tür bir tahmin, finansal piyasalarda gelecekteki olası fiyat hareketlerini anlamaya ve kararlar almaya yardımcı olabilir.
7-Şok Analizi (Impulse Response Analysis)
Şok analiziyle bir değişkende meydana gelen ani bir şokun (örneğin Microsoft hisselerindeki ani bir değişiklik) diğer değişkenler (Google hisseleri) üzerindeki etkisini inceledik. Bu analiz, piyasalardaki ani değişimlerin domino etkisini görmek için kullanılır.
8-Varyans Ayrıştırması (Variance Decomposition)
Varyans ayrıştırması ile bir değişkenin toplam varyansının ne kadarının diğer değişkenler tarafından açıklandığını hesapladık. Bu, bir piyasa değişkeninin diğerleri üzerindeki etkisini nicel olarak göstermeye yarar. Örneğin, Google hisselerinin toplam fiyat değişkenliğinin ne kadarının Microsoft hisseleri tarafından açıklandığını bu yöntemle görebildik
Okuduğunuz için teşekkür eder güzel bir gün dilerim.
Son düzenleme:


