



Biopython, biyolojik hesaplamalar ve biyolojik verileri depolama teknikleri içeren uluslararası geliştirciler tarafından ücretsiz sürülen Python projesidir.
https://biopython.org adresinden edinebilir ve proje hakkında daha çok bilgiye erişebilirsiniz.
1) Kurulumu
https://biopython.org/wiki/Download adresinden edinebilirsiniz.
Dizindeki setup.py scriptine build parametresi vererek yapılandırmalıyız.
Daha sonra test parametresi ile yapılandırmanın doğrulunu test edelim.
Ardından install parametresi ile kuruluma başlayalım.
Ve ya PyPI üzerinden direkt olarak edinmek için ise:
2) DNA Protein Dizilimi ve Kodonlar
Modülün yüklendiğinden emin olmak için projemize dahil edelim.
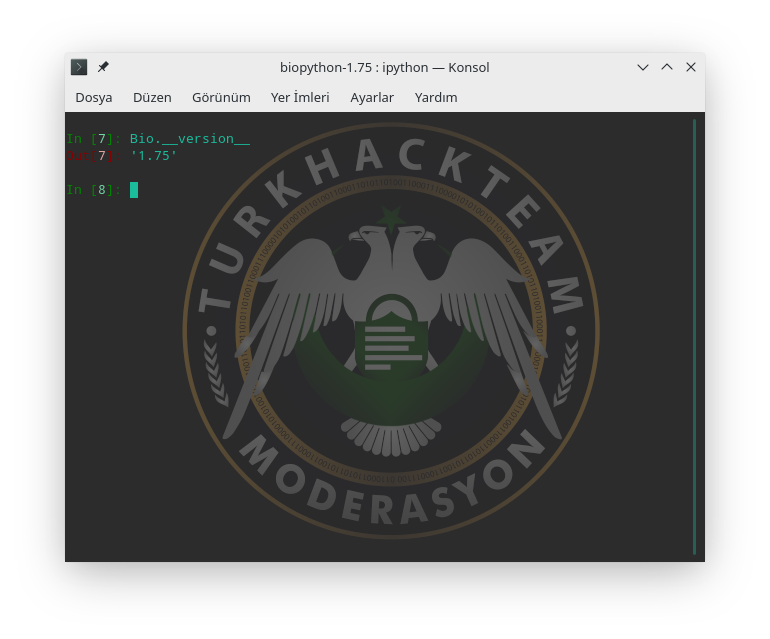
Artık Bio modülünü inceleyebiliriz.
Başlamadan önce kullancağımız bazı biyolojik terimlerden bahsedelim.
RNA: Ribo Nükleik Asit, bir polimerdir. Yapısında ribo şeker, fosfat ve azotlu baz bulunur. DNA zincirinin kopyalanmasında (genetik bilginin proteine çevirisinde) önemli rol alır.
mRNA: Messenger RNA namı değer mesajcı RNA, bir protein amino asit sentezinde diziyi belirleyen kimyasal kodu (bilgi/mesaj) DNA'dan alıp ribozom'a ileten moleküldür.
Transkripsiyon: Ve ya mRNA sentezi, mRNA ile taşınan kalıp iplikçiğin karşısına gelecek olan kodu oluşturan işlemdir.
Urasil: Urasil, RNA'da bulunan 4 asitlik kuvvetten biridir. DNA'da ise Urasil yerine Timin kullanılır. Her ikiside Adenin ile zayıf (çift hidrojenli) baz çifti yapar. (C4H4N2O2)
Timin: Timin DNA'da bulunan bir bazdır. Urasilden farkı ise, urasilde metil grubu bulundurmasıdır. Adenin ile çift hidrojenli bağ yapar. (C5H6N2O2)
Adenin: Urasil ve Timin ile hem RNA hem DNA da bağ yapan bir bazdır. (C5H5N5)
Guanin: Adenin, Timin, Sitozin ve Urasil gibi bir temel olan azotlu bazdır. Guanin, Sitozin ile güçlü (3'lü hidrojen) bağ yapar. Bu bağa Watson-Crick baz eşleşmesi denir. (C5H5N5O)
Sitozin: Tanıtacağımız son azotlu bazdır. Watson-Crick eşleşmesi ile Guanin ile 3 hidrojenli bağ yapar.
Şimdilik kullanacağımız terimleri tanıttık. Basit bir kalıp zincir oluşturup bunu eşleyelim. Tabii bunları Python üzerinde yapacağız")
Bunun için Bio modülünden Seq (sequence, dizi) çekelim. Ayrıca DNA zinciri üzerindeki alfabeyi çözümlemek için Alphabet'in içinden IUPAC modülünü alalım. Bir tane de kalıp iplikçik kodu oluşturalım. Burada Adenin için, A; Timin için, T; Guanin için, G; Sitozin için, C; harfleri tanımlanmıştır.
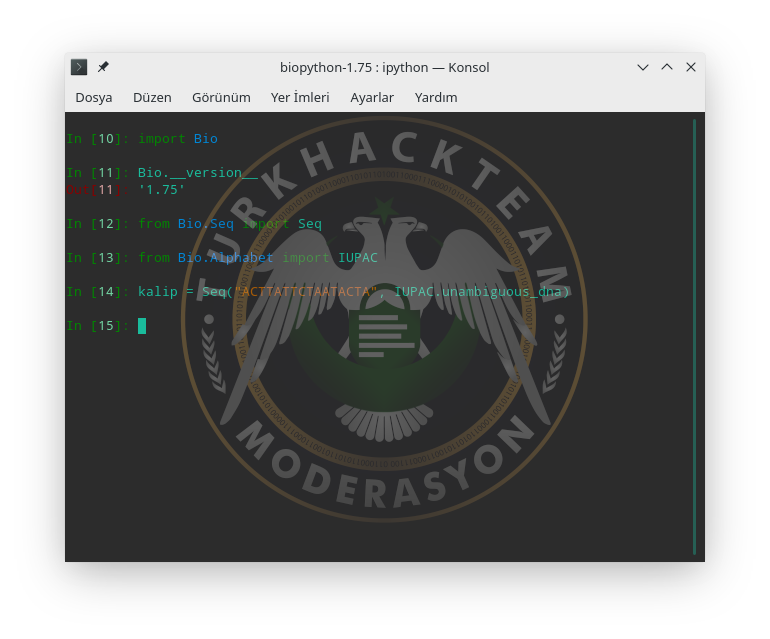
Örnek kalıbımız: "ACTTATTCTAATACTA" olsun. Ve onun bir DNA zinciri olduğunu IUPAC.ambiguous_dna ile belirtelim.
Daha sonra complement() fonksiyonu ile karşısına gelecek olan baz kodunu oluşturalım.
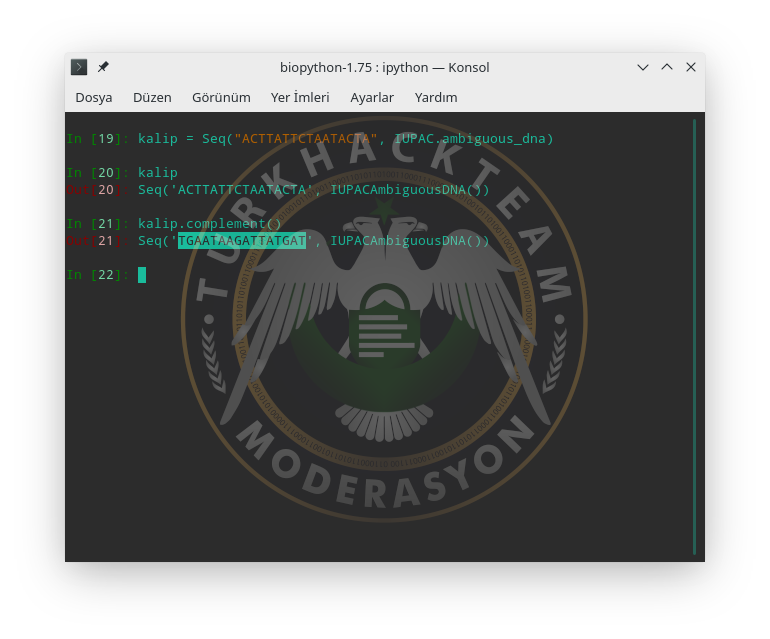
"TGAATAAGATTATGAT" zincirini elde etmiş olduk. Adenin karşısına zayif bağ ile Timin ve Guanin karşısına güçlü bağ ile Sitozinler yerleşmiş. Tabii bu eşleşme DNA zinciri
içindi. RNA zinciri için Seq fonksiyonun 2. operatörüne IUPAC.ambiguous_rna verelim ve tekrar complement() fonksiyonunu çağıralım.
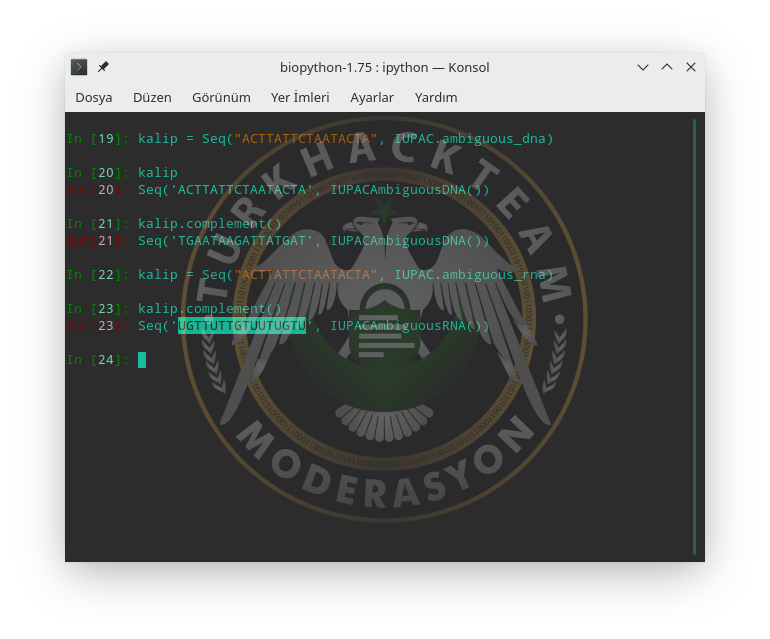
"UGTTUTTGTUUTUGTU" zincirini çıktı verdi. Adeninlerin karşısına terimlerde de belirttiğimiz gibi Timin yerine Urasil geldi.
Tabii koskoca Bio modülü sadece DNA ipliği eşlemeye yaramıyor İçinde pek çok veri de mevcut. Örnek olarak kodon tablosu gibi.
Yeni kullanacağımız terimleri tanıyalım.
Genom: Bir canlı organizmasının kromozomlarındaki bütün genetik dizilerin (şifrelerin) hepsidir. Wiki'de gördüğüm en sade ve hoş anlatım ile "canlının hücrelerinin içine yerleştirilmiş genetik program" .
Gen: Genom içerisinde kalıtımın birimidir. Transkripsiyon işlemi bu gen adındaki ufak birimde gerçekleşir. Baskın genler büyük harf ile gösterilir. Çekinik gen ise küçük harf ile. Çekinik gen, baskın genin mutantı olarak kabul görür.
Kodon: Protein biyosentezi denilen biyokimyasal süreçte gerekli kodu içeren 3 nükleit gruplarından oluşan yapıdır. Örnek GCC ((Ala/A)Alanin), Guanin - Sitozin - Sitozin.
Kodon Tablosu: Oluşabilcek tüm kodonların bulunduğu tablodur. Toplam 64 tane olan kodonlar bu tablo sayesinde gruplanarak ortaya çıkan amino asitlere bize daha rahat çalışılabilir ortam sunar.
Bio modülündeki Data sınıfından CodonTable adındaki yapıyı çekelim.
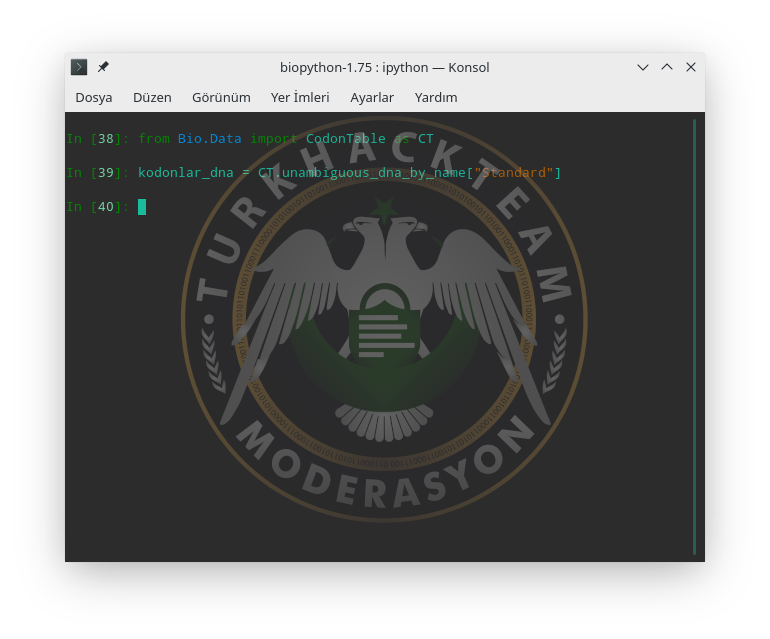
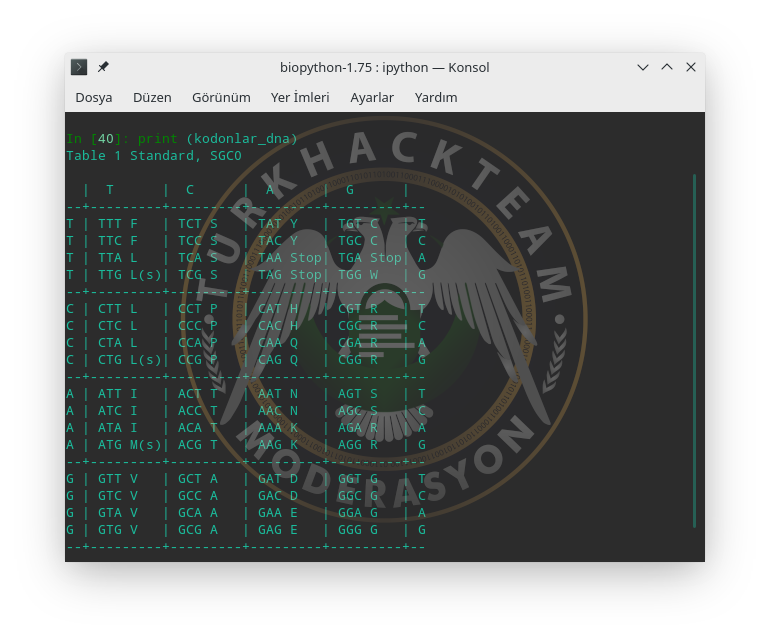
Daha sonra CT'yi bir değişkende tanımlayıp DNA için standart kodon tablosunu basalım.
İstersek RNA'nın kodon tablosu için CT.unambiguous_dna_by_name'i CT.unambiguous_rna_by_name olarak değiştirelim.
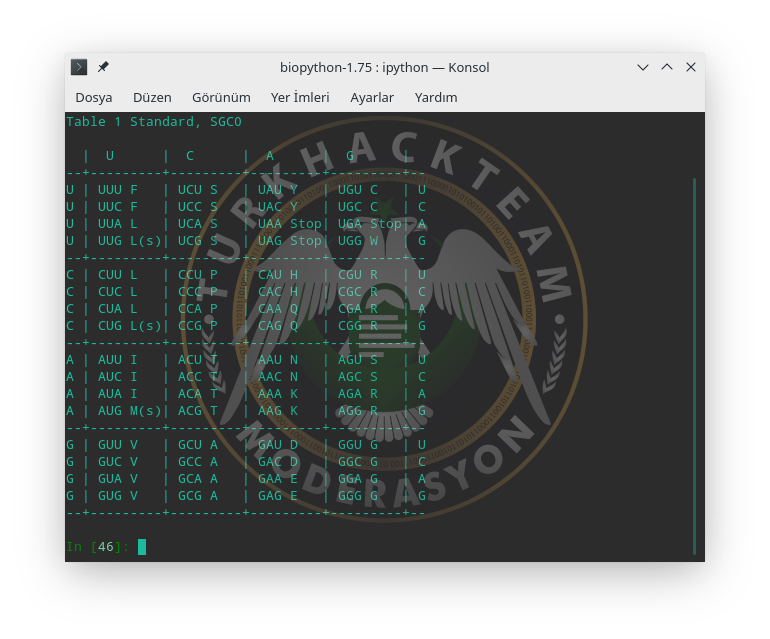
Başlatıcı kodonların yanında (s) ve durdurucu kodonların yanın STOP; Fenilalaninler'in yanın F; İzolösin için I; Treonin için T harfi gibi canlıların yapısında bulunan aminoasitler karşımıza gruplanmış halde çıkmış oldu. Tabii RNA ile DNA arasında Timin ve Urasil farkı var.
3) Gen Bankası
Bir diğer başığımız GenBank yani adından da anlaşılacağı üzeri gen bankası. "gbk" verilerin işlenmesi. Gen verilerine "The National Center for Biotechnology Information" (NCBI) ait FTP sunucusu üzerinden erişebilirsiniz.
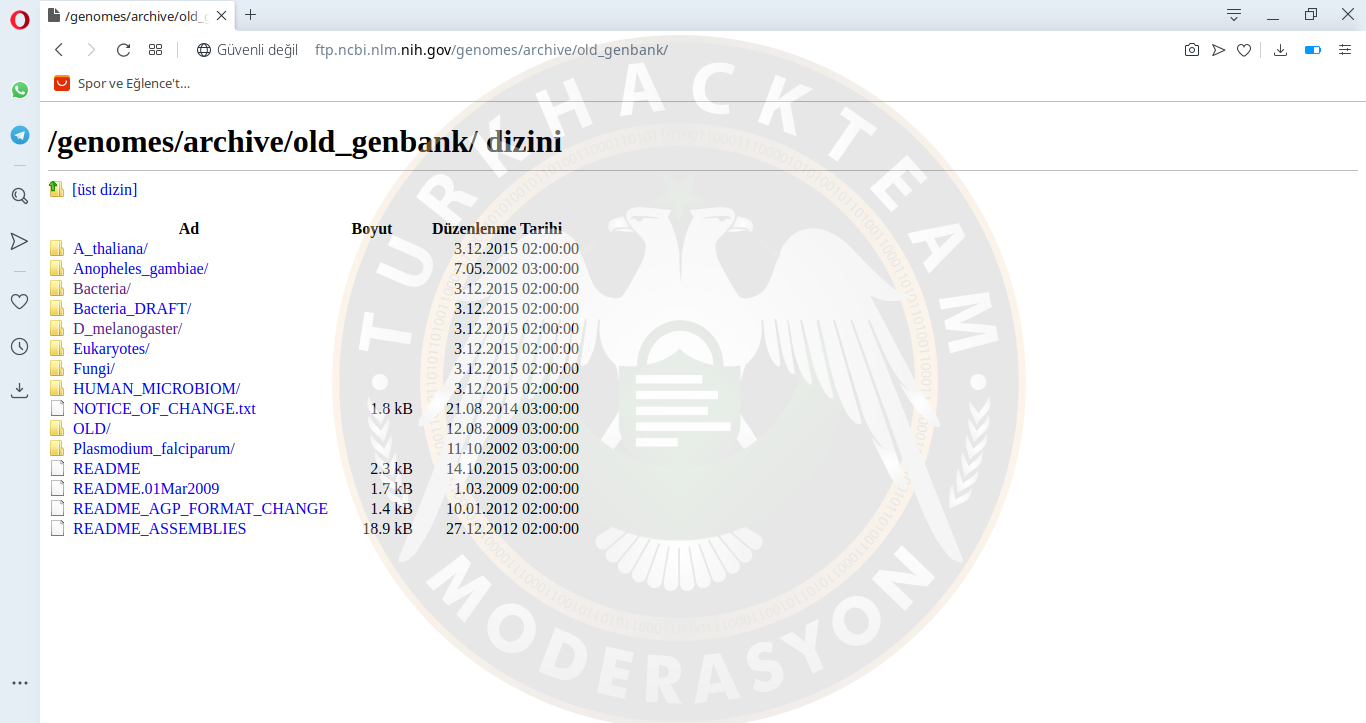
Daha sonra Bakteriler bölümünden rasgele bir bakteri geni çekelim. Ben "Buchnera UID 245" adlı bir bakteri örneğini inceleyeceğim. Ardından bir GenBank dosyası gbk'yi indireceğim.
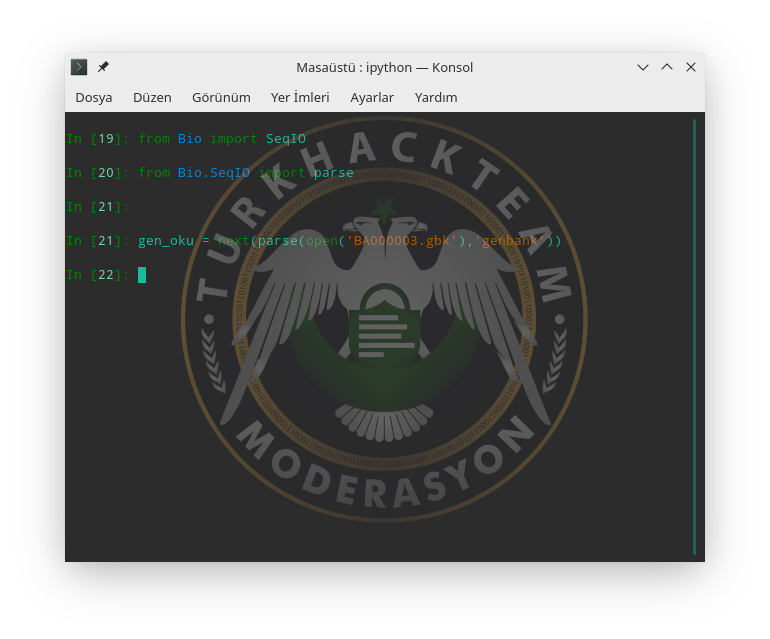
Ardından bu gbk gen dosyasını okumak ve parse etmek için SeqIO (input/output) ve parse sınıf ve fonksiyonunu import etmemiz gerekecek.
Parse fonksiyonuda ilk parametre gen dosya yolu ve onun genbank olduğunu(gbk) tanıttık.
description ile bu bakteri hakkında yapılan açıklamayı görebiliriz.
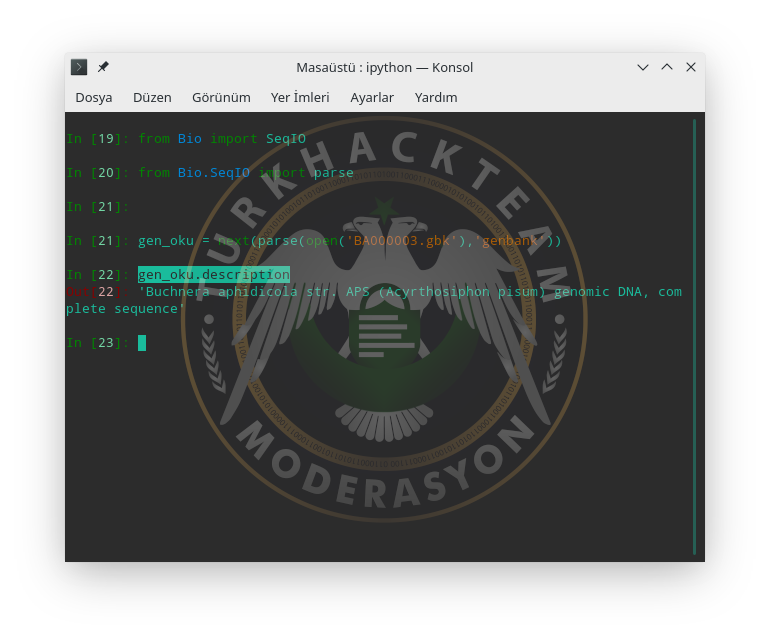
'Buchnera aphidicola str. APS (Acyrthosiphon pisum) genomic DNA, complete sequence'
Açıklamada (bu kısım anladığım kadarı ile) Buchnera aphidicola yani incelediğimiz bakterinin DNA'sı, Acyrthosiphon pisum yani bir tür bezelye biti DNA'sı ile bağlantılı.
Ayrıca Buchnera Aphidicola'nın DNA zincirini de çıkartlam.
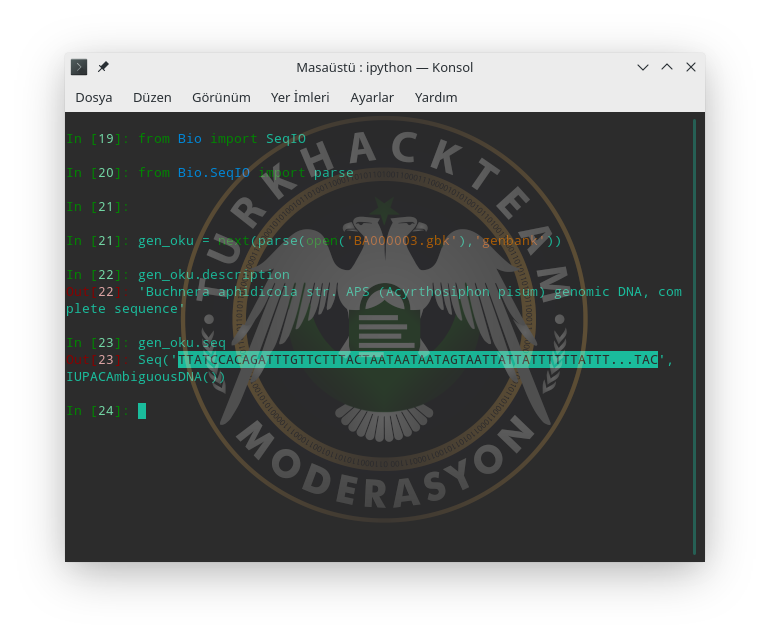
Ayrıca bu canlının taksonomi yani sınıflarını görmek için ise annotations sözlük (dict) yapısından taxonomy'i çağırabiliriz.
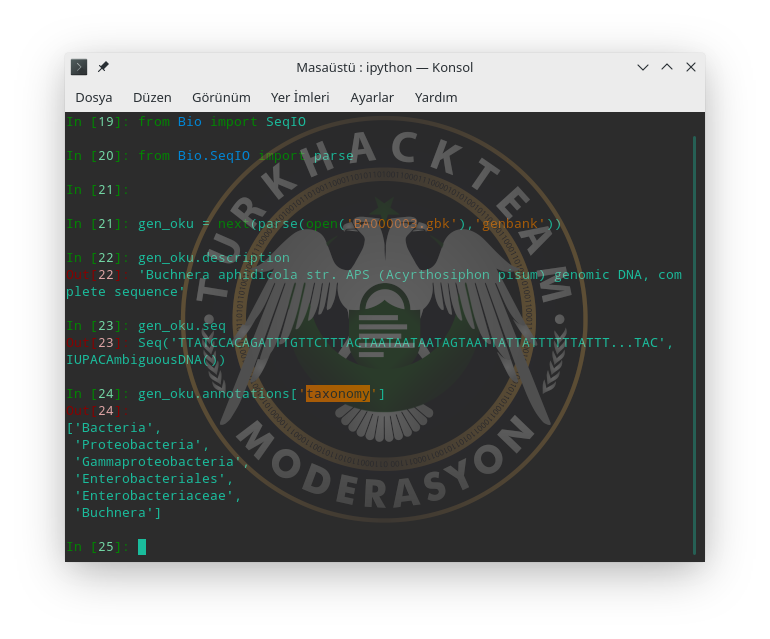
şeklinde bir çıktı elde ettik. Yani
Bakteri Alemi - Proteobakteriler Şube - Gammaproteobakteriler Sınıfı - Enterobacteriales Takımı - Enterobacteriaceae Ailesi - Buchnera Üye (bu da bizimki)
Buradan anlayacağımız; Enterobacteriaceae üyeleri hastalık yapan bakteriler olduğundan Buchnera zararlı bir bakteri.
https://biopython.org adresinden edinebilir ve proje hakkında daha çok bilgiye erişebilirsiniz.
1) Kurulumu
https://biopython.org/wiki/Download adresinden edinebilirsiniz.
Kod:
[COLOR="White"]wget http://biopython.org/DIST/biopython-1.75.zip[/COLOR]
Kod:
[COLOR="white"]unzip biopython-1.75.zip[/COLOR]
Kod:
[COLOR="white"]cd biopython-1.75.zip[/COLOR]Dizindeki setup.py scriptine build parametresi vererek yapılandırmalıyız.
Kod:
[COLOR="white"]python setup.py build[/COLOR]
Kod:
[COLOR="white"]python setup.py test[/COLOR]Ardından install parametresi ile kuruluma başlayalım.
Kod:
[COLOR="white"]python setup.py install[/COLOR]Ve ya PyPI üzerinden direkt olarak edinmek için ise:
Kod:
[COLOR="white"]python -m pip install biopython[/COLOR]2) DNA Protein Dizilimi ve Kodonlar
Modülün yüklendiğinden emin olmak için projemize dahil edelim.
Artık Bio modülünü inceleyebiliriz.
Başlamadan önce kullancağımız bazı biyolojik terimlerden bahsedelim.
RNA: Ribo Nükleik Asit, bir polimerdir. Yapısında ribo şeker, fosfat ve azotlu baz bulunur. DNA zincirinin kopyalanmasında (genetik bilginin proteine çevirisinde) önemli rol alır.
mRNA: Messenger RNA namı değer mesajcı RNA, bir protein amino asit sentezinde diziyi belirleyen kimyasal kodu (bilgi/mesaj) DNA'dan alıp ribozom'a ileten moleküldür.
Transkripsiyon: Ve ya mRNA sentezi, mRNA ile taşınan kalıp iplikçiğin karşısına gelecek olan kodu oluşturan işlemdir.
Urasil: Urasil, RNA'da bulunan 4 asitlik kuvvetten biridir. DNA'da ise Urasil yerine Timin kullanılır. Her ikiside Adenin ile zayıf (çift hidrojenli) baz çifti yapar. (C4H4N2O2)
Timin: Timin DNA'da bulunan bir bazdır. Urasilden farkı ise, urasilde metil grubu bulundurmasıdır. Adenin ile çift hidrojenli bağ yapar. (C5H6N2O2)
Adenin: Urasil ve Timin ile hem RNA hem DNA da bağ yapan bir bazdır. (C5H5N5)
Guanin: Adenin, Timin, Sitozin ve Urasil gibi bir temel olan azotlu bazdır. Guanin, Sitozin ile güçlü (3'lü hidrojen) bağ yapar. Bu bağa Watson-Crick baz eşleşmesi denir. (C5H5N5O)
Sitozin: Tanıtacağımız son azotlu bazdır. Watson-Crick eşleşmesi ile Guanin ile 3 hidrojenli bağ yapar.
Şimdilik kullanacağımız terimleri tanıttık. Basit bir kalıp zincir oluşturup bunu eşleyelim. Tabii bunları Python üzerinde yapacağız
Bunun için Bio modülünden Seq (sequence, dizi) çekelim. Ayrıca DNA zinciri üzerindeki alfabeyi çözümlemek için Alphabet'in içinden IUPAC modülünü alalım. Bir tane de kalıp iplikçik kodu oluşturalım. Burada Adenin için, A; Timin için, T; Guanin için, G; Sitozin için, C; harfleri tanımlanmıştır.
Örnek kalıbımız: "ACTTATTCTAATACTA" olsun. Ve onun bir DNA zinciri olduğunu IUPAC.ambiguous_dna ile belirtelim.
Daha sonra complement() fonksiyonu ile karşısına gelecek olan baz kodunu oluşturalım.
"TGAATAAGATTATGAT" zincirini elde etmiş olduk. Adenin karşısına zayif bağ ile Timin ve Guanin karşısına güçlü bağ ile Sitozinler yerleşmiş. Tabii bu eşleşme DNA zinciri
içindi. RNA zinciri için Seq fonksiyonun 2. operatörüne IUPAC.ambiguous_rna verelim ve tekrar complement() fonksiyonunu çağıralım.
"UGTTUTTGTUUTUGTU" zincirini çıktı verdi. Adeninlerin karşısına terimlerde de belirttiğimiz gibi Timin yerine Urasil geldi.
Tabii koskoca Bio modülü sadece DNA ipliği eşlemeye yaramıyor
İçinde pek çok veri de mevcut. Örnek olarak kodon tablosu gibi. Yeni kullanacağımız terimleri tanıyalım.
Genom: Bir canlı organizmasının kromozomlarındaki bütün genetik dizilerin (şifrelerin) hepsidir. Wiki'de gördüğüm en sade ve hoş anlatım ile "canlının hücrelerinin içine yerleştirilmiş genetik program" .
Gen: Genom içerisinde kalıtımın birimidir. Transkripsiyon işlemi bu gen adındaki ufak birimde gerçekleşir. Baskın genler büyük harf ile gösterilir. Çekinik gen ise küçük harf ile. Çekinik gen, baskın genin mutantı olarak kabul görür.
Kodon: Protein biyosentezi denilen biyokimyasal süreçte gerekli kodu içeren 3 nükleit gruplarından oluşan yapıdır. Örnek GCC ((Ala/A)Alanin), Guanin - Sitozin - Sitozin.
Kodon Tablosu: Oluşabilcek tüm kodonların bulunduğu tablodur. Toplam 64 tane olan kodonlar bu tablo sayesinde gruplanarak ortaya çıkan amino asitlere bize daha rahat çalışılabilir ortam sunar.
Bio modülündeki Data sınıfından CodonTable adındaki yapıyı çekelim.
Daha sonra CT'yi bir değişkende tanımlayıp DNA için standart kodon tablosunu basalım.
İstersek RNA'nın kodon tablosu için CT.unambiguous_dna_by_name'i CT.unambiguous_rna_by_name olarak değiştirelim.
Başlatıcı kodonların yanında (s) ve durdurucu kodonların yanın STOP; Fenilalaninler'in yanın F; İzolösin için I; Treonin için T harfi gibi canlıların yapısında bulunan aminoasitler karşımıza gruplanmış halde çıkmış oldu. Tabii RNA ile DNA arasında Timin ve Urasil farkı var.
3) Gen Bankası
Bir diğer başığımız GenBank yani adından da anlaşılacağı üzeri gen bankası. "gbk" verilerin işlenmesi. Gen verilerine "The National Center for Biotechnology Information" (NCBI) ait FTP sunucusu üzerinden erişebilirsiniz.
Kod:
Adres: [url]ftp://ftp.ncbi.nlm.nih.gov/genomes/archive/old_genbank/[/url]Daha sonra Bakteriler bölümünden rasgele bir bakteri geni çekelim. Ben "Buchnera UID 245" adlı bir bakteri örneğini inceleyeceğim. Ardından bir GenBank dosyası gbk'yi indireceğim.
Ardından bu gbk gen dosyasını okumak ve parse etmek için SeqIO (input/output) ve parse sınıf ve fonksiyonunu import etmemiz gerekecek.
Parse fonksiyonuda ilk parametre gen dosya yolu ve onun genbank olduğunu(gbk) tanıttık.
description ile bu bakteri hakkında yapılan açıklamayı görebiliriz.
'Buchnera aphidicola str. APS (Acyrthosiphon pisum) genomic DNA, complete sequence'
Açıklamada (bu kısım anladığım kadarı ile) Buchnera aphidicola yani incelediğimiz bakterinin DNA'sı, Acyrthosiphon pisum yani bir tür bezelye biti DNA'sı ile bağlantılı.
Ayrıca Buchnera Aphidicola'nın DNA zincirini de çıkartlam.
Kod:
[COLOR="yellow"]TTATCCACAGATTTGTTCTTTACTAATAATAATAGTAATTATTATTTTTTATTT...TAC[/COLOR]Ayrıca bu canlının taksonomi yani sınıflarını görmek için ise annotations sözlük (dict) yapısından taxonomy'i çağırabiliriz.
Kod:
['Bacteria',
'Proteobacteria',
'Gammaproteobacteria',
'Enterobacteriales',
'Enterobacteriaceae',
'Buchnera']şeklinde bir çıktı elde ettik. Yani
Bakteri Alemi - Proteobakteriler Şube - Gammaproteobakteriler Sınıfı - Enterobacteriales Takımı - Enterobacteriaceae Ailesi - Buchnera Üye (bu da bizimki)
Buradan anlayacağımız; Enterobacteriaceae üyeleri hastalık yapan bakteriler olduğundan Buchnera zararlı bir bakteri.
.
Son düzenleme:

