

Herkese merhaba arkadaşlar
bugün size
C# ile ses tanıma, sesle komut işleme konusundan bahsedip örnek bir proje paylaşacağım.
çalışma mantığı dilin metne dökülmesinden ibarettir.
Ses tanıma algoritmaları iki farklı metoda dayanıyor. Bunlar;
Automatic Speech Recognition(ASR) ve Speech ToText (STT)
olarak sıralanabilir.
Automatic Speech Recognition(ASR),
otomatik ses tanıma olarak çevrilebilir.
Alınan seslerin donanım tabanlı teknikler ve yazılımla birlikte kullanılarak işlenmesi anlamına geliyor.
Speech ToText (STT)
sesi metne dönüştürme sistemidir.
Seslerin cihaz tarafından metne dönüştürülmesini sağlar.
Algoritmalardan beslenen ses tanıma teknolojileri HiddenMarkov Model(HMM) ve Dynamic Time Warping (DTW) modelleri ile matematiksel olarak çalışır
Nedir bu markov modeli?
Saklı Markov Modeli konuşma gibi istatistiksel özellikleri zamanla değişkenlik gösteren dizilerin modellenmesinde kullanılır.
Saklı Markov modelinde durumlar doğrudan gözlenemez.
Konuşma tanımada yaygın olarak kullanılması 1980’lerden sonra başlamıştır.
Konuşma sinyali istatistiksel özellikleri zamanla değişen bir sinyaldir.
Herhangi bir anlamlı ses dizisi üretmek istediğimizde gırtlak ve dil gibi ses organlarımız hava basıncını ve hava akışını duyulabilecek ses dizileri üretecek şekilde modüle ederler.
Bazı sesler kHz’ler düzeyinde spektral bileşenler içerebilir.
Buna rağmen ses organlarımızın yapısı saniyede en fazla 10 kere değişir.
Ses modelleme, belirli seslerin kısa zaman spektral özelliklerinin analizini içerir ve bu modelleme farklı seslere karşılık gelen ses 8 organ yapısının uzun zaman değişimini tanımlamamızı sağlar.
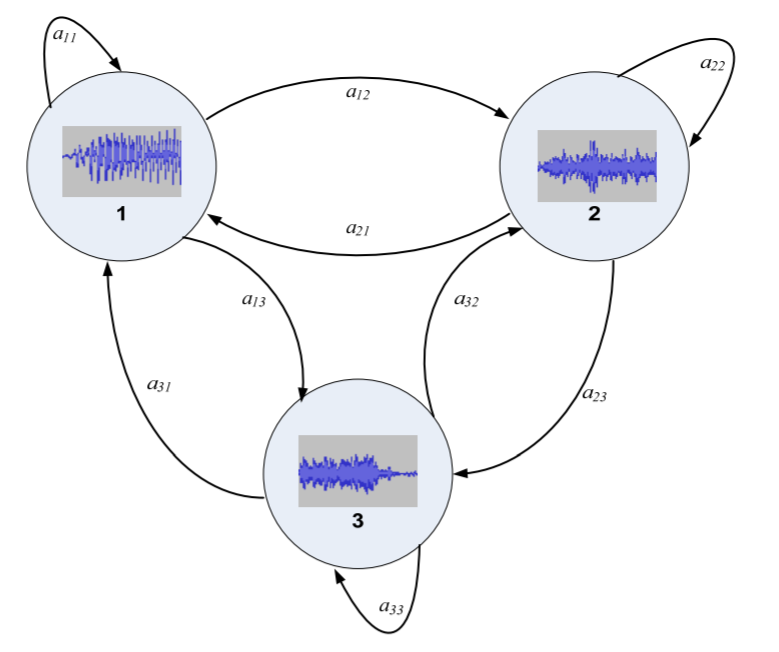
Zamanla değişkenlik gösteren ve spektral gözlem dizileri ile temsil edilen ses dizilerini tanımlayabilmenin bir yolu bu diziyi bir sesten diğer bir sese geçiş şeklinde Markov zincirleri ile göstermektir. aşağıda görülen birinci derece 3 durumlu Markov zincirinde, sistemin bir t anında N farklı durumdan birinde (S1, S2, S3, S4, SN) olacak şekilde tanımlanabilir.
Nedir bu Dynamic Time Warping?
DTW Belirli bir sözcüğün seslendirilmesi, kişiden kişiye hatta aynı kişinin farklı zamanlarda seslendirmesi ile zaman içinde farklılık gösterebilmektedir.
Aynı sözcüğün seslendirilmesi, bir seslendirmede uzun, bir seslendirmede ise daha kısa zamanda gerçekleştirilebilir.
Aynı zamanda, ses sinyalinde kimi fonemler daha uzun, kimileri ise daha kısa yer almaktadır.
Dynamic Time Warping algoritması yardımıyla, bu iki seslendirme, zaman içinde yayılarak ya da daraltılarak birbirine yaklaştırılmaya çalışır.
Yani bu iki seslendirmenin, zaman olarak örtüştürülmesi işlevi gerçekleştirilir.
DTW, sözcük tabanlı ses tanıma sistemlerinde etkin ve sıkça kullanılan bir yöntemdir.
Bu yaklaşımla, çalışma anında tespit edilen sözcük kesimlemesi,
sistemde kayıtlı sözcük şablonları ile seslendirme zamanları örtüştürülerek karşılaştırılması gerçekleştirilebilir.
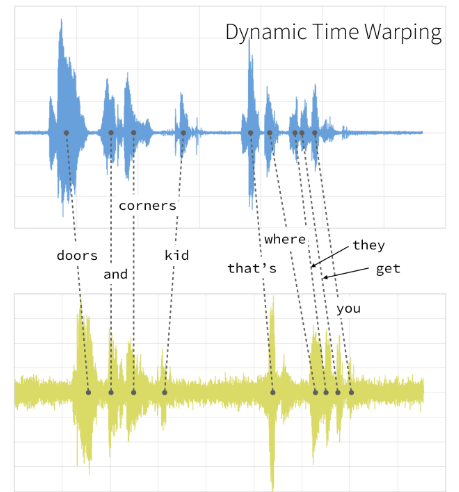
aşağıda iki ses sinyali arasında DTW algoritmasının zaman ekseninde uygulanması gösterilmektedir.
o halde artık örnek uygulamamıza geçelim
öncelikle, kendi örneğinizi yapmak isterseniz
using System.Speech.Recognition;
kütüphanesini kurmalı ve
BAŞVURU EKLE
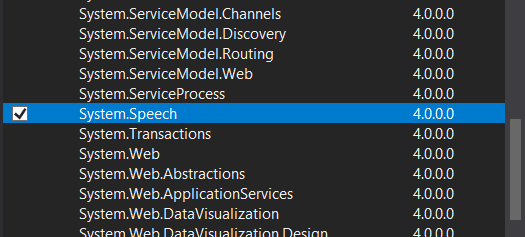
şeklinde başvuru eklemelisiniz
PROGRAM EKRAN GÖRÜNTÜSÜ
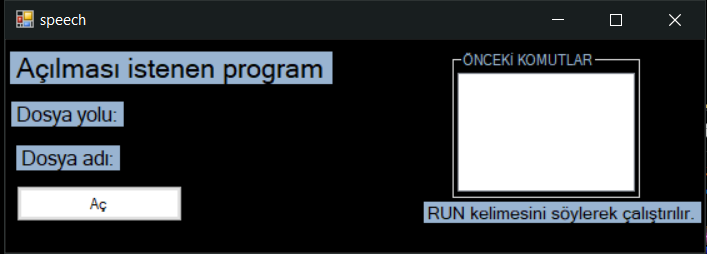
Program sizden "RUN" sesli komutunu alınca
seçtiğiniz programı açar.
(mikrofon tavsiye edilir)
KAYNAK KOD/GİTHUB LİNKİ
PROGRAM İNDİRME LİNKİ
 s6.dosya.tc
s6.dosya.tc
virustotal linki
(false positive var)
(dil paketi uyumsuzluğu ya da çeşitli problemler çıkarabilir
çözümleri için dm gelebilirsiniz ya da alta yazabilirsiniz.)
bugün size
C# ile ses tanıma, sesle komut işleme konusundan bahsedip örnek bir proje paylaşacağım.
çalışma mantığı dilin metne dökülmesinden ibarettir.
Ses tanıma algoritmaları iki farklı metoda dayanıyor. Bunlar;
Automatic Speech Recognition(ASR) ve Speech ToText (STT)
olarak sıralanabilir.
Automatic Speech Recognition(ASR),
otomatik ses tanıma olarak çevrilebilir.
Alınan seslerin donanım tabanlı teknikler ve yazılımla birlikte kullanılarak işlenmesi anlamına geliyor.
Speech ToText (STT)
sesi metne dönüştürme sistemidir.
Seslerin cihaz tarafından metne dönüştürülmesini sağlar.
Algoritmalardan beslenen ses tanıma teknolojileri HiddenMarkov Model(HMM) ve Dynamic Time Warping (DTW) modelleri ile matematiksel olarak çalışır
Nedir bu markov modeli?
Saklı Markov Modeli konuşma gibi istatistiksel özellikleri zamanla değişkenlik gösteren dizilerin modellenmesinde kullanılır.
Saklı Markov modelinde durumlar doğrudan gözlenemez.
Konuşma tanımada yaygın olarak kullanılması 1980’lerden sonra başlamıştır.
Konuşma sinyali istatistiksel özellikleri zamanla değişen bir sinyaldir.
Herhangi bir anlamlı ses dizisi üretmek istediğimizde gırtlak ve dil gibi ses organlarımız hava basıncını ve hava akışını duyulabilecek ses dizileri üretecek şekilde modüle ederler.
Bazı sesler kHz’ler düzeyinde spektral bileşenler içerebilir.
Buna rağmen ses organlarımızın yapısı saniyede en fazla 10 kere değişir.
Ses modelleme, belirli seslerin kısa zaman spektral özelliklerinin analizini içerir ve bu modelleme farklı seslere karşılık gelen ses 8 organ yapısının uzun zaman değişimini tanımlamamızı sağlar.
Zamanla değişkenlik gösteren ve spektral gözlem dizileri ile temsil edilen ses dizilerini tanımlayabilmenin bir yolu bu diziyi bir sesten diğer bir sese geçiş şeklinde Markov zincirleri ile göstermektir. aşağıda görülen birinci derece 3 durumlu Markov zincirinde, sistemin bir t anında N farklı durumdan birinde (S1, S2, S3, S4, SN) olacak şekilde tanımlanabilir.
Nedir bu Dynamic Time Warping?
DTW Belirli bir sözcüğün seslendirilmesi, kişiden kişiye hatta aynı kişinin farklı zamanlarda seslendirmesi ile zaman içinde farklılık gösterebilmektedir.
Aynı sözcüğün seslendirilmesi, bir seslendirmede uzun, bir seslendirmede ise daha kısa zamanda gerçekleştirilebilir.
Aynı zamanda, ses sinyalinde kimi fonemler daha uzun, kimileri ise daha kısa yer almaktadır.
Dynamic Time Warping algoritması yardımıyla, bu iki seslendirme, zaman içinde yayılarak ya da daraltılarak birbirine yaklaştırılmaya çalışır.
Yani bu iki seslendirmenin, zaman olarak örtüştürülmesi işlevi gerçekleştirilir.
DTW, sözcük tabanlı ses tanıma sistemlerinde etkin ve sıkça kullanılan bir yöntemdir.
Bu yaklaşımla, çalışma anında tespit edilen sözcük kesimlemesi,
sistemde kayıtlı sözcük şablonları ile seslendirme zamanları örtüştürülerek karşılaştırılması gerçekleştirilebilir.
aşağıda iki ses sinyali arasında DTW algoritmasının zaman ekseninde uygulanması gösterilmektedir.
o halde artık örnek uygulamamıza geçelim
öncelikle, kendi örneğinizi yapmak isterseniz
using System.Speech.Recognition;
kütüphanesini kurmalı ve
BAŞVURU EKLE
şeklinde başvuru eklemelisiniz
PROGRAM EKRAN GÖRÜNTÜSÜ
Program sizden "RUN" sesli komutunu alınca
seçtiğiniz programı açar.
(mikrofon tavsiye edilir)
KAYNAK KOD/GİTHUB LİNKİ
PROGRAM İNDİRME LİNKİ
speech.rar dosyasını indir - download
speech.rar dosyasını indir, download. Dosya.tc .Dosya Upload. Dosya Paylaş. Dosya Yükle
s6.dosya.tc
virustotal linki

(dil paketi uyumsuzluğu ya da çeşitli problemler çıkarabilir
çözümleri için dm gelebilirsiniz ya da alta yazabilirsiniz.)
Son düzenleme:
")




