




DESMAP — Site Link Collector (0x1A7)
Basit, sağlam ve kullanımı kolay link toplayıcı / recon aracı
Geliştirici: 0x1A7 | Sürüm: 1.0 | Platform: Windows / Cross-platform (CLI)

Kısa Tanım:
DESMAP, bir web sitesine girip o sitedeki tüm linkleri, script dosyalarındaki URL’leri, robots.txt ve sitemap.xml içerisindeki bağlantıları otomatik olarak toplar.
Sonuçları JSON / CSV / TXT olarak dışa aktarır.
Pentest, Recon, OSINT veya web haritalama süreçleri için uygundur.
Özellikler:
->HTML tag’lerinden (a, img, link, iframe, form, source, script) link toplama
->Inline JavaScript veya script dosyalarındaki URL’leri bulur
->robots.txt okur (Allow / Disallow / Sitemap)
->sitemap.xml dosyasındaki URL’leri çıkarır
->Domain içi / dışı tarama desteği
->Derinlik kontrolü (--depth)
-> Maksimum sayfa limiti (--max-pages)
-> Çoklu thread desteği (paralel istekler)
->JSON / CSV / TXT çıktı desteği
->Tamamen komut satırı tabanlı (GUI’siz, hızlı, stabil)
Hızlı Kurulum (Windows):
->Python 3.10 veya üzeri sürümü indir → [URL='https://www.python.org/downloads[/url']https://www.python.org/downloads[/url]
-> Kurulumda Add Python to PATH seçeneğini işaretle.
->DESMAP klasörünü aç, install.bat dosyasını çalıştır.
->Komut satırına gir:
Kod:
call .venv\Scripts\activate
python site_link_collector.py https://testphp.vulnweb.com --depth 1 --format allrequirements.txt
Kod:
requests>=2.28
beautifulsoup4>=4.12
lxml>=4.9(Bu modüller install.bat ile otomatik kurulacaktır.)
Kullanım Örnekleri:
Kod:
python site_link_collector.py https://example.com
python site_link_collector.py https://example.com --depth 2
python site_link_collector.py https://example.com --format all --output example_links
python site_link_collector.py https://example.com --follow-sitemap yes
python site_link_collector.py https://example.com --follow-external yesArgümanlar:
->--depth N → Kaç kat derinliğe kadar tarasın.
->--concurrency N → Aynı anda kaç istek atılsın.
->--obey-robots yes|no → robots.txt kurallarına uysun mu?
->--follow-external yes|no → Dış domainlere geçsin mi?
->--follow-sitemap yes|no → robots.txt içindeki sitemap linklerini dahil etsin mi?
->--js-scan yes|no → Script dosyalarını regex ile tarasın mı?
->--timeout S → HTTP zaman aşımı.
->--max-pages N → Maksimum taranacak sayfa.
->--output NAME → Çıktı dosya adı.
->--format json|csv|txt|all → Çıktı formatı.
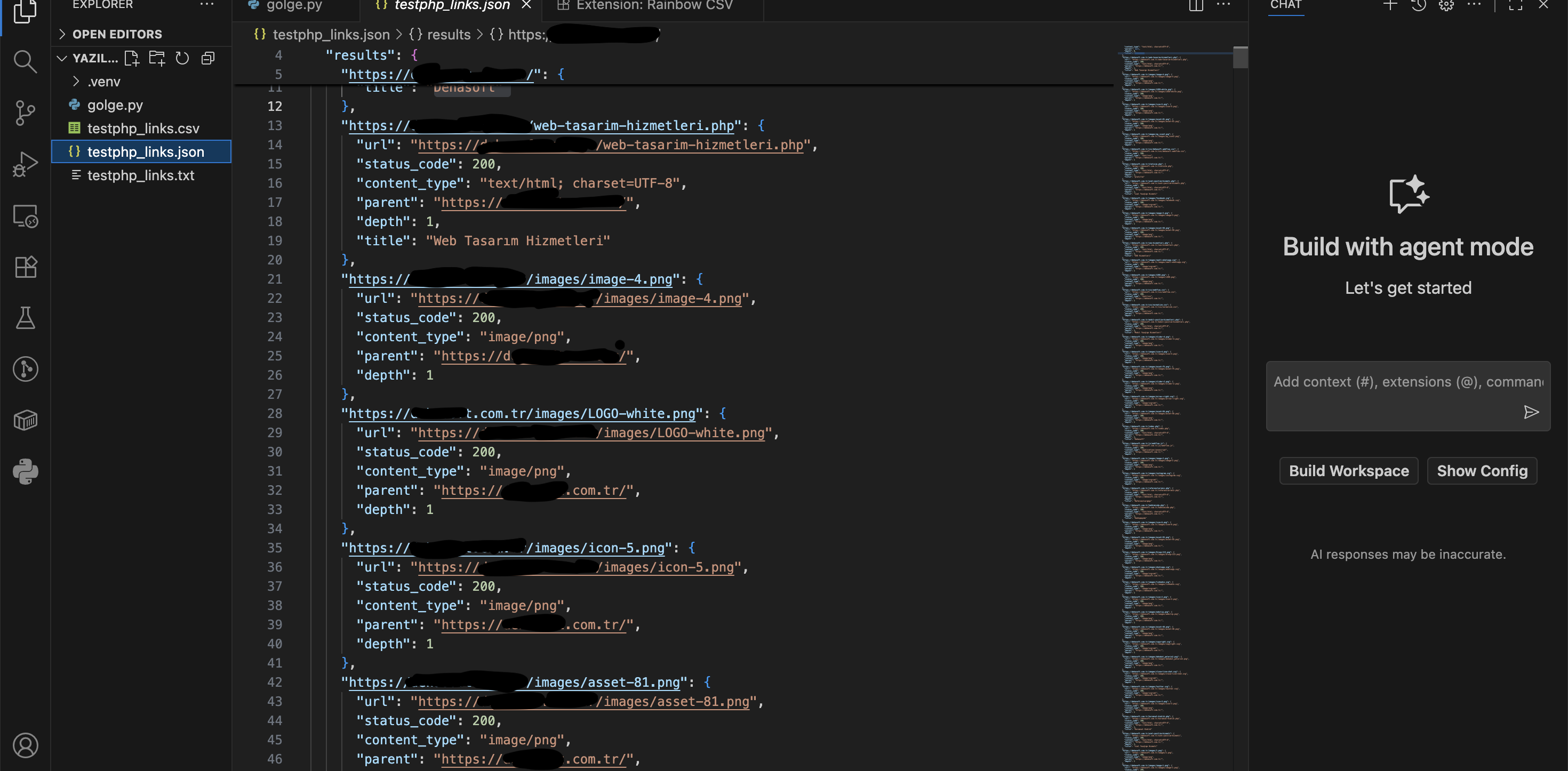
Çıktı Örneği (JSON):
Kod:
{
"base": "https://example.com",
"results": {
"https://example.com/": {
"status_code": 200,
"content_type": "text/html",
"depth": 0,
"title": "Example Domain"
},
"https://example.com/about": {
"status_code": 200,
"content_type": "text/html",
"parent": "https://example.com/",
"depth": 1
}
}
}
Notlar:
-> --depth büyüdükçe tarama süresi uzar, dikkatli kullanılmalı.
-> --follow-sitemap yes binlerce link çıkarabilir.
-> Varsayılan olarak robots.txt’e uyar.
-> Yalnızca izinli testlerde kullanın.
Geliştirici:
0x1A7 — TurkHackTeam
İstek, öneri ve katkılarınızı başlık altına yazabilirsiniz.
İleride: proxy desteği, Graph export, çoklu domain tarama planlanıyor.
“GİTHUB”
 DESMAP — “Discover Every Site Map.”
DESMAP — “Discover Every Site Map.”
Son düzenleme:

