



Selamlar, bu konu birlikte çalıştığım bir arkadaşımın yazdığı blog yazısından alıntıdır.Temel elasticsearch mimarisini, indexing sharding gibi bazı kavramları giriş seviyesinde açıklar.
İlk blog yazım olarak ES101 sizlerle, yazı umarım açıklayıcı ve yararlı olmuştur. İçerik daha çok elasticsearchün mimarisi hakkında genel bilgi içermektedir. Genel olarak başlıklar şöyledir; index, inverted index, shard, lucene, segment. Evet ilk başta bu kavramlar çok karışık gelmektedir ancak görseller ile daha konuların oturduğunu söyleyebilirim.
Elasticsearch, lucene java kütüphanesi üzerine kurulmuş distributed arama motorudur. Elasticsearche gönderilen datayı lucene görür ve saklar.
Elasticsearch, lucene java kütüphanesi üzerine kurulmuş distributed arama motorudur. Elasticsearche gönderilen datayı lucene görür ve saklar.
NoSQL yapıları 4 temel başlıkta ayrılır:
- d ocument-based
- key-value
- graph-based
- column-based
Elasticsearch burada d ocument-based NoSQL grubuna girmektedir, key-value yapısına benzemektedir ancak value kısmında dökümanı tutmaktadır.
Index nedir?
Aslında her bir index Relational Databaseler deki tablo yapısına denk geliyor diyebiliriz. Indexi oluştururken iki yöntem vardır biri manuel olarak bizim oluşturmamız, ikincisi ise bunu elasticsearche bıraktığımız yöntemdir. Temelde bir index bir veya birden fazla shardı temsil eden alan adıdır. Indexlemek(indexing) kavramı ise; datayı elasticsearche göndermek(verinin geri istenebilecek şekilde saklanması ve arama yapılmabileceği) anlamına gelmektedir.
1. Yöntem
POST /users diyerek manuel oluşturmak
2. Yöntem
POST /users/user/1 diyerek yeni bir döküman eklerken, elasticsearch mappingleri kendisi yaparak bir index oluşturur
İndexi oluşturan bileşenler; mappings, settings ve aliasesdır.
Kod:
{
"index-name": {
"aliases": {},
"mappings": {
"user": {
"properties": {
"name": {
"type": "string"
}
}
}
},
"settings": {
"index": {
"creation_date": "1447004861339",
"uuid": "KzZW7zJyTPavy4n1TTeNkg",
"number_of_replicas": "1",
"number_of_shards": "5",
"version": {
"created": "1070399"
}
}
}
}
}Aliases, indexe verdiğimiz takma isimlerdir ve bize uygulamanın kesinti yaşamadan index değiştirebilmesini sağlar.
Mappings, index içerisinde saklanacak veri yapısını tutmaktadır, aslında RDBlerdeki tablo yapısı olarak düşünülebilir. Her ne kadar tutulan data json yapısında olarak bize esnek bir yapı sağlasada, data yapısını vermek bize performans sağlar.
Settings içerisinde index ile ilgili ayarlar bulunmaktadır, örnek olarak; kaç shard?, replika sayısı kaç? gibi soruların cevapları buradan ayarlanmaktadır. Bunun yanında analyzer bilgileride burada bulunmaktadır. Analyzer da seri işlemleri gerçekleştirerek en son bir çıktı verir elasticsearch için.
Type, benzer dökümanlar sınıfıdır diyebiliriz aslında şöyleki, user indexini düşünelim. Bu index altında admin,user ve staff gibi typelar oluşturabiliriz.
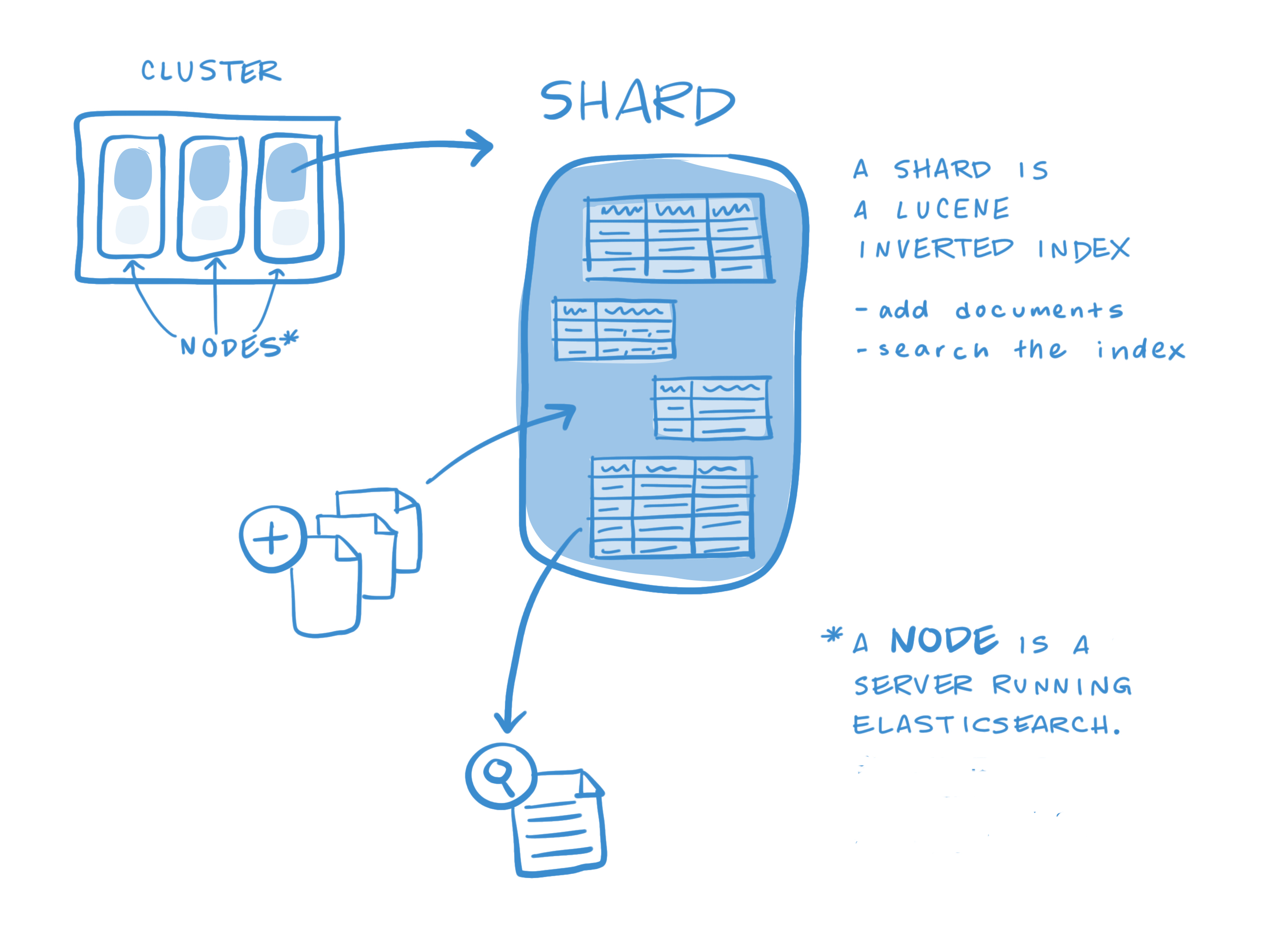
Shard nedir?
Elasticsearch clusterı içerisinde çalışan lucene instancelarını temsil eder ve ayrıyetten lucene index de diyebiliriz. Bir index tek başına bir sharddan oluşabilir ancak, genellikle indexin büyüyebilmesi ve bir kaç node üzerinde dağıtılabilmesi için bir kaç sharddan oluşmaktadır. Primary shard döküman için ev sahipliği yapmaktadır, replica shard ise primarynin bir kopyasıdır ve primary shard down olması durumunda replica shard kullanılır. Ayrıca dökümanı read ederkende replikalar kullanılabilir.(distributed read)
Replica, elasticsearch her verinin kopyasını başka makinalara da gönderir, böylece makinalardan bir tanesi down olması durumunda veri kaybı yaşanması engellenir.
Ayrıca elasticsearchde consistency level tanımlayarak, indexleme işleminin bitmesini tüm shardlarda indexledikten sonra başarılı olarak dönecek şekilde ayarlayabiliriz.
Bir elasticsearch index search işlemi yapıldığında, bu arama işlemi tüm shardların tüm segmentlerinde gerçekleşir ve merge olurlar.
Shard aslında elasticsearch için bir scaling unit anlamı taşımaktadır. Örnek olarak; iki elasticsearch index searchü (herbirine bir shard) ile bir indexin iki shard olması aynı durum çünkü, iki adet lucene index search işlemi gerçekleşir.
Dökümanları indexlerken, shardlara route olurlar, default olarak round-robin olarak dağıtılır. Index create edilirken verilen shard sayısı daha sonrasında değiştirilemez, bu demek değilki çözüm yolu yok. Bu durumda index shrink yada reindex işlemleri gerçekleştirilerek shard sayısı değiştirilebilir.
Index shrink işlemi shard sayısını azaltmak için kullanılır, burada önemli olan bir nokta ise; primary shard olarak düşünürsek yeni shard sayısı eski shard sayısının çarpanları olabilir. Örnek olarak, 15 primary shardlı bir index düşünür isek, shrink işlemi ile primary shard sayısı 1,3,5 den biri olabilir. Shrink işleminde, öncelikle aynı özelliklerde sadece shard sayısını azaltarak yeni bir index oluşturur, daha sonra eğer dosya sistemi izin veriyorsa segmentleri yeni indexe hard-link yapar(dosya sistemi izin vermiyor ise yeni indexe kopyalar ve bu süreç daha uzun sürer). Daha sonrasında ise yeni indexi eskisinin yerine koyarak işlemi tamamlar.
Reindex işleminde ise, yeni indexe eski indexteki konfigurasyonlar aktarılmaz ve yeni konfigurasyonlar ile index oluşturduktan sonra, dökümanlar yeni indexe kopyalanır.
Replica, elasticsearch her verinin kopyasını başka makinalara da gönderir, böylece makinalardan bir tanesi down olması durumunda veri kaybı yaşanması engellenir.
Ayrıca elasticsearchde consistency level tanımlayarak, indexleme işleminin bitmesini tüm shardlarda indexledikten sonra başarılı olarak dönecek şekilde ayarlayabiliriz.
Bir elasticsearch index search işlemi yapıldığında, bu arama işlemi tüm shardların tüm segmentlerinde gerçekleşir ve merge olurlar.
Shard aslında elasticsearch için bir scaling unit anlamı taşımaktadır. Örnek olarak; iki elasticsearch index searchü (herbirine bir shard) ile bir indexin iki shard olması aynı durum çünkü, iki adet lucene index search işlemi gerçekleşir.
Dökümanları indexlerken, shardlara route olurlar, default olarak round-robin olarak dağıtılır. Index create edilirken verilen shard sayısı daha sonrasında değiştirilemez, bu demek değilki çözüm yolu yok. Bu durumda index shrink yada reindex işlemleri gerçekleştirilerek shard sayısı değiştirilebilir.
Index shrink işlemi shard sayısını azaltmak için kullanılır, burada önemli olan bir nokta ise; primary shard olarak düşünürsek yeni shard sayısı eski shard sayısının çarpanları olabilir. Örnek olarak, 15 primary shardlı bir index düşünür isek, shrink işlemi ile primary shard sayısı 1,3,5 den biri olabilir. Shrink işleminde, öncelikle aynı özelliklerde sadece shard sayısını azaltarak yeni bir index oluşturur, daha sonra eğer dosya sistemi izin veriyorsa segmentleri yeni indexe hard-link yapar(dosya sistemi izin vermiyor ise yeni indexe kopyalar ve bu süreç daha uzun sürer). Daha sonrasında ise yeni indexi eskisinin yerine koyarak işlemi tamamlar.
Reindex işleminde ise, yeni indexe eski indexteki konfigurasyonlar aktarılmaz ve yeni konfigurasyonlar ile index oluşturduktan sonra, dökümanlar yeni indexe kopyalanır.
Lucene nedir?
Apache tarafından geliştirilen java tabanlı full-text search olanağı sağlayan bir kütüphanedir. Bir döküman basit olarak field:value olarak eşlenir. Lucene fieldın string yada tarih vb bir formatta olmasını önemsemez, opaque-bytes olarak kabul eder.
Lucenede biz bir dökümanı indexlediğimiz zaman, her bir alan(field)için değerler(values) inverted indexe eklenir ve isteğe bağlı olarak orjinal değerler daha sonrada ulaşılabilir olması için değişmeden de saklanabilir.
Elasticsearchteki type kavramının lucenede tam karşılığı yoktur ancak, lucenede bu veriler bir dökümanın m eta datasında _type diye bir alanda tutulur ve özel bir arama yaparken; lucene _type alanına göre filtreleme yapar.
Lucene üzerinde mapping diye bir kavram da bulunmamaktadır, mapping elasticsearchün karışık json dökümanının lucenein beklediği bir yapıya çevrilmesi için kullanılır.
Lucene her ne kadar transaction sağlasa bile, elasticsearch bunu sağlamaz.
Inverted Index Nedir?
Aslında inverted-index ile; terimler-döküman ilişkisini bir yerde tuttuğumuzu düşünürsek, bir term ile search işlemi gerçekleşirken bu terme denk gelen dökümanlara direkt erişebilirsiniz.
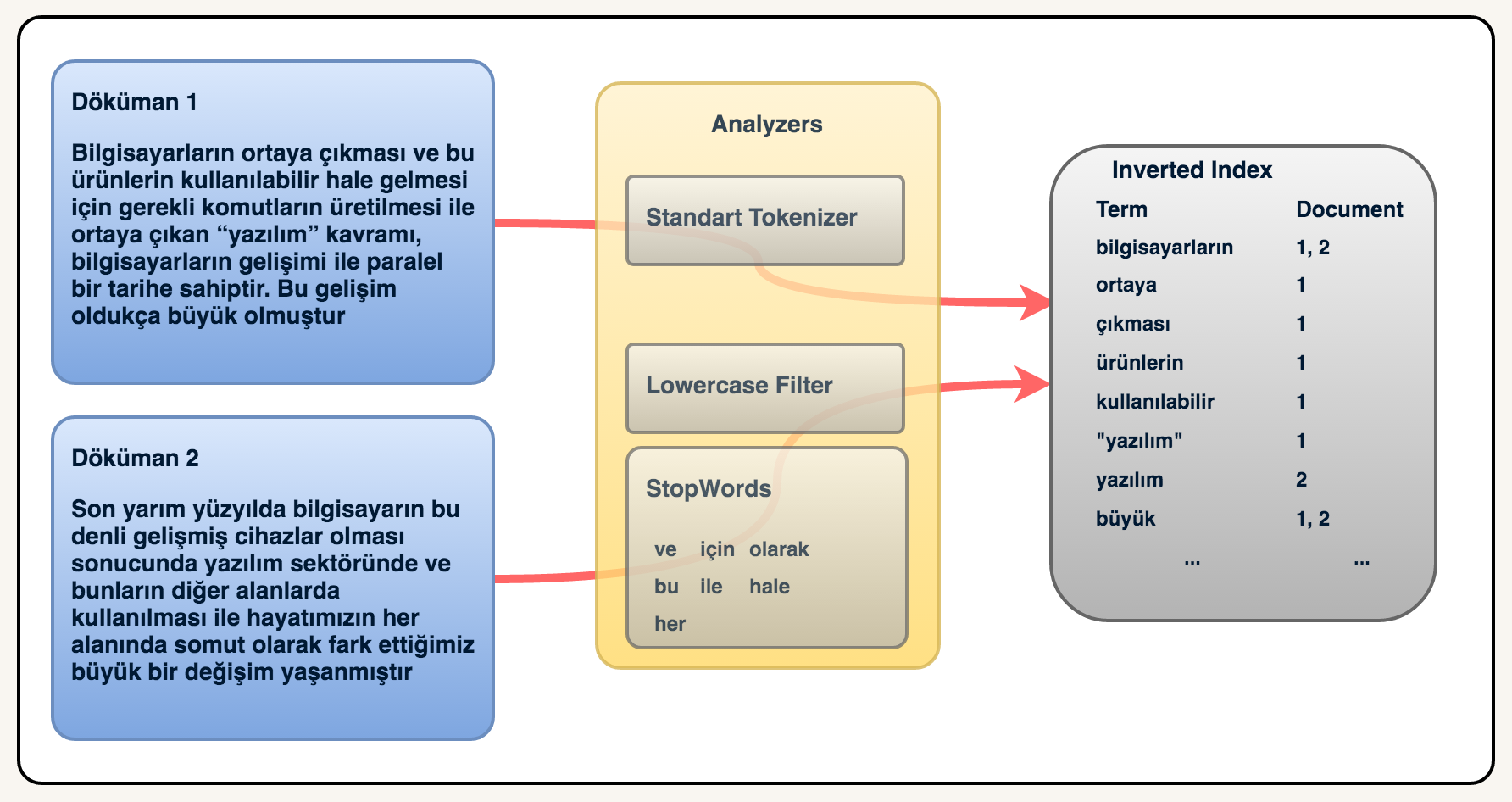
Inverted-Indexte önemli noktalardan bir tanesi ise analyzerlardır. Çeşitli tokenizer ve filterlar üzerinden geçtikten sonra inverted indexe kayıt edilir.
Örnek olarak; standart tokenizer burada texti split etti aslında, lowercase filter ise hepsini küçük harfe çevirdi ve stopwords ise bazı kelimeleri çıkarttı. En sonun da en sağdaki gibi bir inverted-index oluştu, bu örnekte bir dökümanda birden fazla yerde aynı kelimenin geçme durumuda ele alınarak(bilgisayarın {1:1,1:14} gibi)
Yukarıdaki görsel elastic mimarisindeki hiyerarşiyi anlamanızda biraz daha yardımcı olacaktır. Cluster içerisinde nodelar, ve onların içerisinde ise shardlar bulunmaktadır. Shardlar nodelara dağıtılırken primary ve secondary shardlar farklı makinelere dağıtılarak olası problemleri minimize etmek gerekmektedir. Shardların da içerisinde segmentler bulunmaktadır.
Segment Nedir?
Her shard birden fazla segmente sahiptir ve her segment bir inverted indextir. Bir shard üzerinde yapılan arama sırasıyla her bir segmentte aranacaktır ve sonra elde edilen bu sonuçlar shard bazında oluşan, sonuçlar kümesinde toplanacaktır.
Bir dökümanı indexlerken, elasticsearch onları öncelikle transaction loga yazacak(data kaybı olmaması için) ve memoryde(diske göre daha performanslı olması için) toplayacaktır. Daha sonra ise index. d ocument_interval süresinde(default 1sn) bir diskte yeni bir segment oluşturarak veriyi segment içerisinde search edilebilir hale getirir ve re fresh eder. Şu an veri arama yapılabilir(searchable) haldedir. Ancak yeni oluşan bu segment henüz fsync(flush) edilmemiş haldedir, yani halen kaybolma riskine sahiptir. Elasticsearch sık sık flush işlemini gerçekleştirir, ve bu işlem sonrasında veri artık işlenmiştir(indexlenmiştir) ve sonrasında transaction logdan silinir.
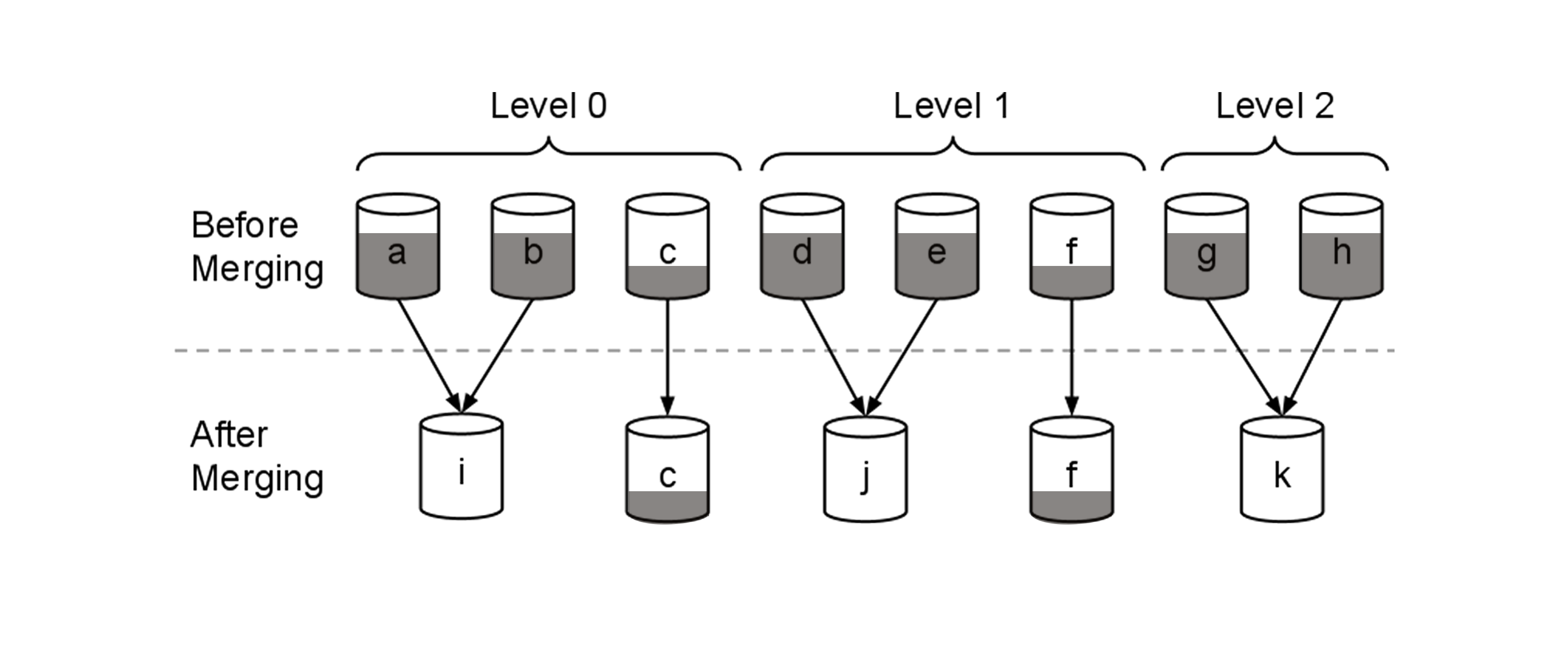
Segment sayısı optimize olmalıdır, çünkü fazla segment olması daha performanslı olması anlamına gelmez. Ne kadar çok segment olur ise aramalar o kadar uzun sürer, çünkü segmentlerden dönen arama sonuçları shardda toplanırken merge maliyeti devreye girer.
Peki sürekli segment oluşturuyoruz o zaman nasıl optimize etmeliyiz derseniz, elasticsearch arkaplanda gerçekleştirdiği merge processsler sayesinde benzer büyüklükteki segmentleri birleştirerek daha büyük segmentler elde eder ve bunu diske yazdıktan sonra eskilerini siler. Merge operasyonları için ise birden fazla policy bulunmaktadır (Policy Tipleri, Örnekler).
Changing Bits: Visualizing Lucene's segment merges
Segmentler immutabledır(değişmezler), döküman update edildiğinde ise eski döküman silindi olarak işaretlenir ve yeni bir döküman ekleniyormuş gibi işlem yapılır.
Yapılan merge processler esnasında ayrıyetten silindi olarak işaretlenen dökümanlarda çıkartılır. Daha fazla döküman eklenmesi herzaman index sizeının artması anlamına gelmez. Nasıl derseniz; silindi olarak işaretlenenler merge processte silindiği için böyle bir durumla karşılaşılma ihtimalide bulunmaktadır.
Concurrent merge scheduling; merge işlemleri ayrı threadlerde gerçekleşir, maximum thread counta gelindiğinde ise available olana dek bekler ve daha sonra devam eder. Lucene 2.3 versiyonundan önce her döküman ekleme işleminde tiny segmentler oluşturuluyordu, ancak artık d ocuments writer ile döküman topluluğu (batch of d ocuments) in-memory segmentlerde tutulur. Ayrıca lucene versiyon 4'ten sonra bu işlemlerin her biri bir threadde de gerçekleşebilir, böylece conurrent flushing yaparak indexing performansının artışını sağlar, daha eski versiyonlarda ise; indexing flushın bitmesini bekler.
Indexing throughput oldukça önemli bir faktör, reindexing yaparken; küçük segmentleri flushing ve merging yapmak pek efektif değildir. Bu yüzden bu esnada geçici olarak re fresh intervalı arttırmak yada re freshingi kapatmak iyi bir yol olabilir.
Referanslar:
Changing Bits: Visualizing Lucene's segment merges
https://elasticsearch.kulekci.net/
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
(orj makale: https://medium.com/hashtech/https-medium-com-hltsydmr-elasticsearch-es101-4b852dcb9763)
Son düzenleme:
") :
: 
