




Merhaba dostlarım,bu makalemde sizlere "Makine öğrenmesi (ML), Derin öğrenme (DL), Bilgisayar bilimi (CS), Matematik, İstatistik, Mükendislik" gibi alanlarda karşımıza çıkan ve oldukça popüler olan "Gradient Descent" optimizasyon algoritmasını anlatacağım. Algoritma hakkında detaylı bilgi verdikten sonra, kullanılan formüllere ve bunlara karşılık gelen "Python3" örneklerine bakacağız. Foruma katkısı ve bu alanda çalışacak arkadaşlara faydalı olması dileğiyle diyerek başlamak istiyorum.
İyi okumalar.
|
|
v
Algoritma nedir?
Kısa tanımı ile algoritma; belirli bir problemin ya da sorunun çözümü için ihtiyaç duyulan tüm işlemlerin sıralı ve mantıksal olarak ifade edilme şeklidir.İyi okumalar.
|
|
v
Algoritma nedir?
Kapsamlı tanımı ile algoritma, Matematik ve bilgisayar biliminde belirli bir problem sınıfını çözmek veya bir hesaplama gerçekleştirmek için kullanılan, iyi tanımlanmış talimatların sonlu bir dizisidir. Algoritmalar, hesaplamalar yapmak ve veri işlemek için spesifikasyonlar olarak kullanılır. Algoritmalar, yapay zekayı kullanarak otomatik kesintiler yapabilmek ve kodu çeşitli yollardan yönlendirmek için matematiksel ve mantıksal testlerde kullanılabilir.
Buluşsal yöntem; özellikle iyi tanımlanmış doğru veya optimal sonucun olmadığı problem alanlarında, tam olarak belirlenemeyen, doğru veya optimal sonuçları garanti etmeyebilecek bir problem çözme yaklaşımıdır.
Etkili bir yöntem olarak bir algoritma, bir fonksiyonu hesaplamak için sınırlı bir uzay ve zaman miktarı içinde ve iyi tanımlanmış bir biçimsel dilde ifade edilebilir. Bir ilk durumdan ve ilk girdiden başlayarak komutlar yürütüldüğünde, sonlu sayıda iyi tanımlanmış ardışık durum boyunca ilerleyen ve sonunda "output(çıktı)" üreten bir hesaplama tanımlanır.
Nihai bir bitiş durumunda sona erer. Bir durumdan diğerine geçiş mutlaka deterministik değildir; rastgele algoritmalar olarak bilinen bazı algoritmalar, rastgele girdi içerebilir.
Optimizasyon nedir?
Matematik, bilgisayar bilimi, ekonomi veya yönetim biliminde matematiksel optimizasyon, bazı mevcut alternatifler arasından en iyi öğenin seçilmesidir.
Diğer bir tanımla bir optimizasyon problemi, izin verilen bir küme içinden girdi değerlerini sistematik olarak seçerek ve fonksiyonun değerini hesaplayarak gerçek bir fonksiyonu en üst düzeye çıkarmak veya en aza indirmekten oluşur.
Kısaca optimizasyon, çeşitli farklı türde amaç işlevleri ve farklı etki alanları dahil olmak üzere, tanımlanmış bir alana verilen bazı amaç fonksiyonlarının "mevcut en iyi" değerlerini bulmayı içerir.
Peki "Algoritma" ve "Optimizasyon" kavramlarına değindiğimize göre, bu makalenin konusu olan “Gradient Descent optimizasyon algoritması” başlığına geçebiliriz.

Gradient Descent Optimizasyon Algoritması nedir?

Gradient Descent; makine öğrenimi modellerini, derin öğrenme modellerini ve sinir ağlarını eğitmek için yaygın olarak kullanılan, "Augustin-Louis Cauchy" tarafından 18.yüzyılda keşfedilen bir optimizasyon algoritmasıdır. Sektörde bir başka kullanılan tanımı ise “Steepest Descent” yani “En dik iniş” şeklindedir. Gradient Descent, optimizasyon için ML ve DL alanlarında kullanılan en meşhur algoritmadır.
Gradient Descent (GD) algoritmasının amacı, belirli bir fonksiyonun yerel “minimum/maksimum” değerini bulmaktır. Algoritma, bir “maliyet/kayıp” işlevini en aza indirmek için (örneğin doğrusal bir regresyonda) makine öğreniminde (ML) ve derin öğrenmede (DL) oldukça sık kullanılır . Önem derecesi ve uygulama kolaylığı nedeniyle, bu algoritmaya genellikle hemen hemen tüm makine öğrenmesi derslerinin giriş bölümlerinde yer verilir.
Maksimum ve minimum kavramlarından bahsetmiştik. Peki nedir bu yerel minimum/maksisum?
Negatif bir eğime doğru hareket edilirse veya mevcut noktada fonksiyonun eğiminden uzaklaşılırsa, o fonksiyonun yerel minimumu bulunabilir.
Diğer yandan,
Pozitif bir eğime doğru veya mevcut noktada fonksiyonun eğimine doğru hareket edilirse, o fonksiyonun yerel maksimumu bulunabilir.
Test verileri, modellerin zaman içinde öğrenmesine yardımcı olacaktır ve Gradiient Descent içindeki maliyet işlevi, parametre güncellemelerinin her yinelemesinde doğruluğunu ölçecektir. Fonksiyon sıfıra yakın veya eşit olana kadar model, parametrelerini mümkün olan en küçük hatayı verecek şekilde ayarlamaya devam edecektir.
Makine öğrenimi (ML) modelleri doğruluk için optimize edildiğinde, yapay zeka (AI) ve bilgisayar bilimi uygulamaları için güçlü araçlar olabilirler.
Çalışma mantığı nedir?
Oldukça basit bir şekilde adım adım çalışma mantığından bahsedecek olursak;
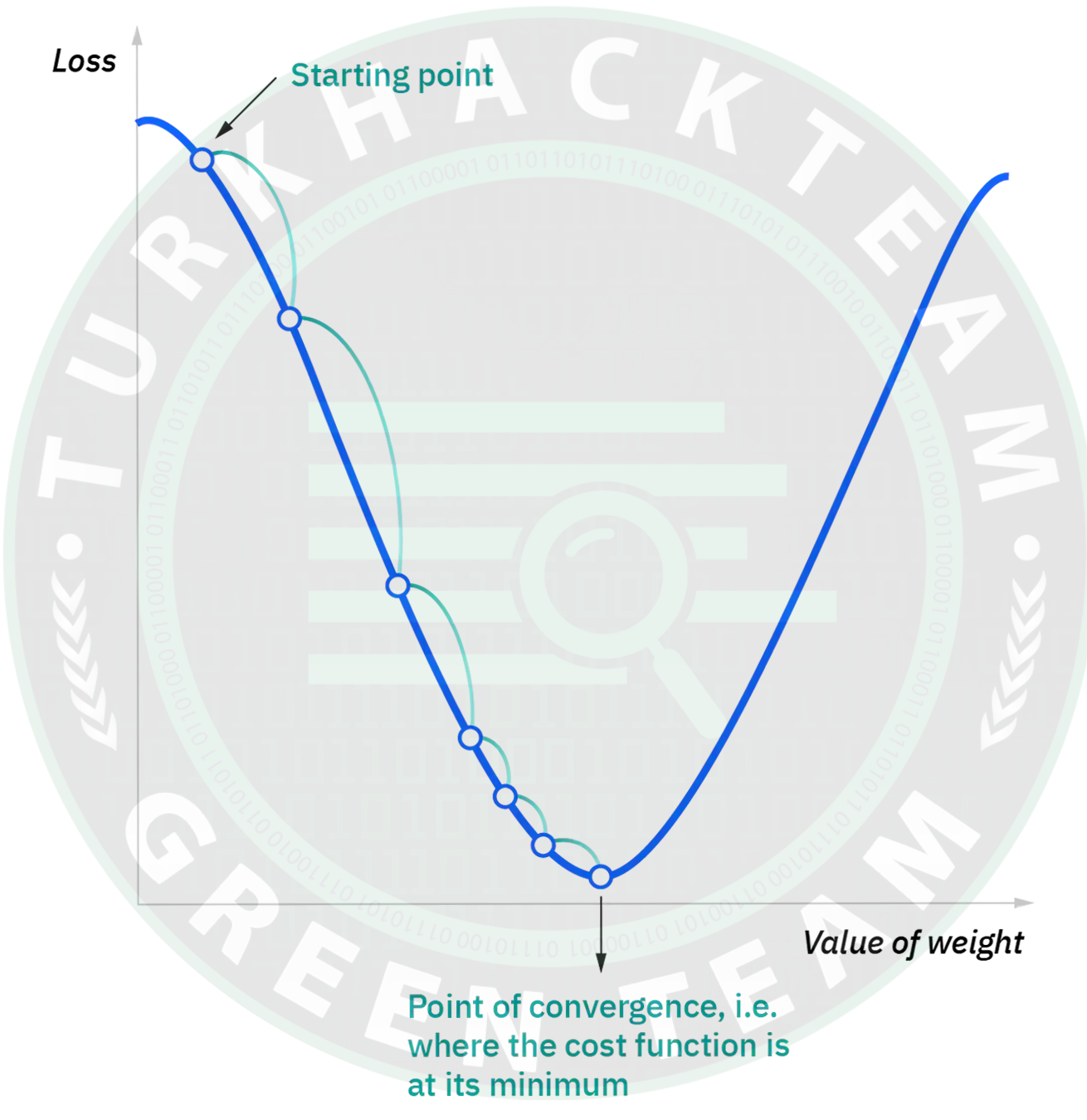
Amacımızın, en düşük maliyeti veren değeri bulmak olduğunu varsayalım.
1.)Öncelikle verilere uygun fonksiyona karar verilir.
2.)Fonksiyonda yer alan parametreler için (a,b) vektörü oluşturulur.
3.)Gradient Descent algoritmasının amacı, bu vektörleri en uygun hale getirmektir.
4.)Vektörü için başlangıç değeri atanır.
5.)Değerleri için Cost Function hesaplanır.
6.)Bu değer her adımda hesaplanır ve minimum değere indirgenmeye çalışılır.
7.)Algoritma "Gradient Descent" yani "eğim azaltma" adını bu iterative indirgemeden alır.
8.)Yeni değerler hesaplanır.
9.)5. adım yeniden uygulanır. Maliyet fonksiyonu azalmaya başlarsa iterasyon sonlandırılır.

Verilere uygun fonksiyon dedik. Peki bu fonksiyonlar nedir, ne iş yapar?
Başlıca fonksiyonlar şunlardır;
Learning rate, The Cost/Loss Function, Hypothesis, Error Function
Daha yakından bakalım…
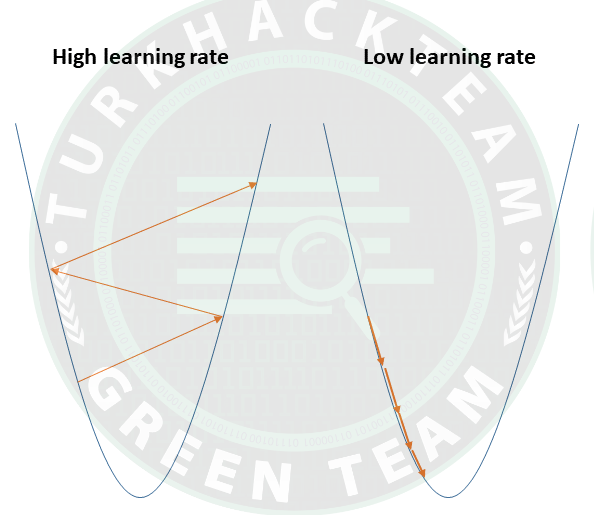
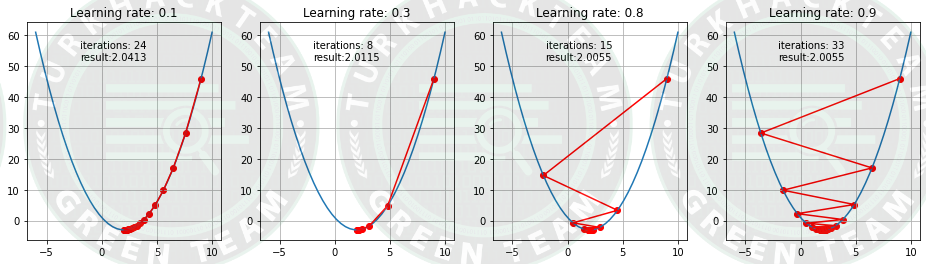
Learning rate:
Öğrenme oranı, minimuma veya en düşük noktaya ulaşmak için atılan adım boyutu olarak tanımlanabilir. Bu, genellikle maliyet fonksiyonunun davranışına göre değerlendirilen ve güncellenen küçük bir değerdir. Öğrenme oranı yüksekse, daha büyük adımlarla sonuçlanır, ancak aynı zamanda minimumu aşma risklerine de yol açar. Aynı zamanda, düşük bir öğrenme oranı, genel verimliliği tehlikeye atan ancak daha fazla hassasiyet avantajı sağlayan küçük adım boyutlarını gösterir.
The Cost/Loss Function:
Maliyet/Kayıp fonksiyonu, bulunduğu konumda “gerçek y” ile “tahmin edilen y” arasındaki farkı/hatayı ölçer. Bu foknsiyon; hatayı en aza indirgemek, yerel veya küresel minimumu bulmak, parametreleri ayarlayabilmek için modele geri bildirim sağlayar ve makine öğrenimi (ML) modelinin faaliyetini artırır. Maliyet fonksiyonu sıfıra yakın veya sıfır olana kadar “en dik iniş” (veya negatif eğim) yönünde hareket ederek devamlı olarak yinelenir. Bu noktada model öğrenimi durduracaktır. Ek olarak, maliyet fonksiyonu ve kayıp fonksiyonu terimleri eş anlamlı kabul edilse de aralarında küçük bir fark vardır. Bir kayıp fonksiyonunun bir eğitim örneğindeki hatayı ifade ederken, bir maliyet fonksiyonunun tüm eğitim setindeki ortalama hatayı hesapladığını belirtmekte fayda var dostlarım.

Hypothesis:
Hipotez fonksiyonu,her girdi değerine karşılık bir tahmin değeri çıktısı verir. Bu fonksiyonun amacı sürekli algoritma tarafından yeniden hesaplanan maliyet fonksiyonu içinde kullanılacak olan “teta değerlerini” belirlemektir.
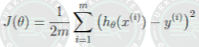
Error Function:
Hipotez fonksiyonu, girdi değerlerine ait sütun ile girdi değerleri çarpılır ardından “tahmin edilen y” değeri elde edilir. Elde edilen bu sonuç, y çıktı değerlerinden çıkarılınca hatanın değeri elde edilir. Bu hata değerinin karesini ise fonksiyonun içerisinde kullanılır.
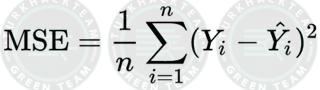
Ufak ufak, adım adım küçülerek sonuca gitmeyi gelin basit bir "Python3" kodu ile görelim.
Kod;
Python:
# Gerekli kütüphanenin içeri alınması
import numpy as np
def gradient_descent(start, gradient, learn_rate, max_iter, tol=0.01):
steps = [start] # geçmiş izleme
x = start
for _ in range(max_iter):
diff = learn_rate*gradient(x)
if np.abs(diff)<tol:
break
x = x - diff
steps.append(x) # geçmiş izleme
return steps, x
def func1(x):
return x ** 2 - 4 * x + 1
def gradient_func1(x):
return 2 * x - 4
history, result = gradient_descent(9, gradient_func1, 0.1, 100)
print(history)
print("")
print(result)Çıktı ise şu şekildedir;
Kod:
[9, 7.6, 6.4799999999999995, 5.584, 4.8671999999999995, 4.29376, 3.8350079999999998, 3.4680063999999997, 3.17440512, 2.939524096, 2.7516192768, 2.60129542144, 2.481036337152, 2.3848290697216, 2.30786325577728, 2.246290604621824, 2.197032483697459, 2.1576259869579673, 2.1261007895663737, 2.100880631653099, 2.080704505322479, 2.064563604257983, 2.0516508834063862, 2.041320706725109]
2.041320706725109Kısa bir ilişkilendirme örneği
Gradient Descent algoritmasını anlamlandırabilmek için gerçek hayat ile bir ilişkilendirme yapmak istiyorum.
Bir dağ yürüyüşü yaptığınızı hayal edin. Yüksek bir dağın neredeyse en yüksek yerine gelmişsiniz. Ancak hava kararmış ve sabahı beklemeye vaktiniz yok. Bir an önce dağdan inmeniz gerekiyor.
Etraf karanlık ve tam seçilemediği için ilk önce küçük adımlar ile iniş yapmaya çalışırsınız değil mi? Sonuçta orası bir dağ ve zemin düz değil.
Kısa ve küçük adımlar ile belli bir mesafe gittiğinizde artık kendinize olan güveniniz gelmiş ve zemini az çok tahmin edebiliyorsunuzdur. Bu aşamadan sonra daha büyük adımlar atarak daha çok mesafe gitmeye çalışırsınız.
Dağdan aşağı indikçe zeminin de düzleşmesi ile artık büyük adımlar atıp mesafeyi bir an önce bitirmek istersiniz.
İşte burada olan, küçük adımlar ile sağlamacı ancak daha sonra büyük adımlar ile iş bitirici bir yaklaşım, bu algoritmaya güzel bir örnek olabilir.
Örnekte ki adım sayısı "iterasyon sayısı", adımların büyüklüğü ve küçüklüğü "öğrenme oranı" kavramlarına denk gelmektedir.
Bazılarınızın içinden "Arap atı işte ya, sonradan açılıyor" dediğini duyar gibiyim
")
Gradient Descent türleri nelerdir?

Eğim azaltma algoritmasının 3 türü bulunmaktadır.
Bunlar;
Batch GD, Mini-Batch GD, Stochastic GD
Daha yakından bakalım…

Batch Gradient Descent (Yığın eğim azaltma), test veri kümesindeki her örnek için hatayı hesaplar, ancak model yalnızca tüm eğitim örnekleri değerlendirildikten sonra güncellenir. Tüm bu süreç bir döngü gibidir ve buna “Eğitim dönemi” denir.
Yığın dereceli azaltmanın bazı avantajları, hesaplama açısından verimli olmasıdır. Kararlı bir hata eğimi ve kararlı bir yakınsama üretir. Bazı dezavantajlar, kararlı hata eğiminin bazen modelin ulaşabileceği en iyi olmayan bir yakınsama durumuyla sonuçlanabilmesidir. Ayrıca, tüm eğitim veri kümesinin bellekte olmasını ve algoritma için kullanılabilir olmasını gerektirir.
Yığın eğim azaltmanın avantajları:
Diğer eğimli azaltmalara kıyasla daha az gürültü üretir.
Kararlı eğim azaltma yakınsaması üretir.
Tüm kaynaklar, bütün eğitim örnekleri için kullanıldığından hesaplama açısından verimlidir.
Formül;
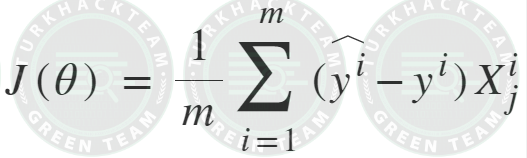
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
from sklearn.datasets import make_regression
import pylab
def gradient_descent(alpha, x, y, numIterations):
m = x.shape[0] # örnek sayısı
theta = np.ones(2)
x_transpose = x.transpose()
for iter in range(0, numIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y
J = np.sum(loss ** 2) / (2 * m) # maliyet
print("iter %s | J: %.3f" % (iter, J))
gradient = np.dot(x_transpose, loss) / m
theta = theta - alpha * gradient # güncelleme
return theta
if __name__ == '__main__':
x, y = make_regression(n_samples=100, n_features=1, n_informative=1,
random_state=0, noise=35)
m, n = np.shape(x)
x = np.c_[ np.ones(m), x] # sütun ekle
alpha = 0.01 # öğrenme oranı
theta = gradient_descent(alpha, x, y, 1000)
# plot ile çizim
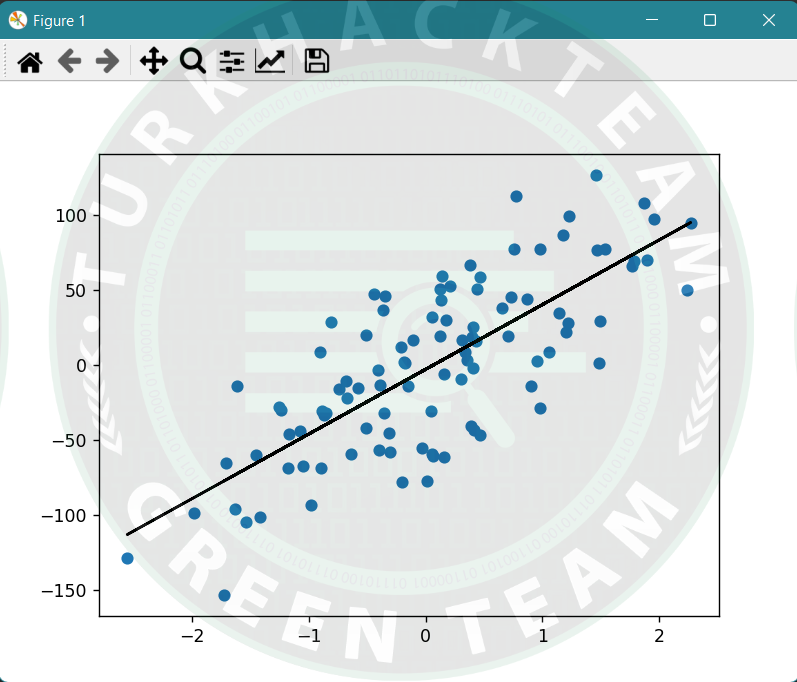
for i in range(x.shape[1]):
y_predict = theta[0] + theta[1]*x
pylab.plot(x[:,1],y,'o')
pylab.plot(x,y_predict,'k-')
pylab.show()
print("Done!")Çıktı;

SGD, veri kümesi içindeki her örnek için bir eğitim dönemi çalıştırır ve her eğitim örneğinin parametrelerini birer birer günceller. Yalnızca bir eğitim örneğini tutmanız gerektiğinden, bunları bellekte saklamak daha kolaydır. Bu sık güncellemeler daha fazla ayrıntı ve hız sunabilse de, toplu gradyan düşüşüne kıyasla hesaplama verimliliğinde kayıplara neden olabilir. Sık güncellemeleri gürültülü eğimlere neden olabilir, ancak bu aynı zamanda yerel minimumdan kaçmada ve küresel olanı bulmada yardımcı olabilir.
SGD bazı avantajları;
İstenen bellekte tahsis etmek daha kolaydır.
Yığın eğim azaltmaya göre hesaplanması nispeten hızlıdır.
Büyük veri kümeleri için daha verimlidir.
Formül;
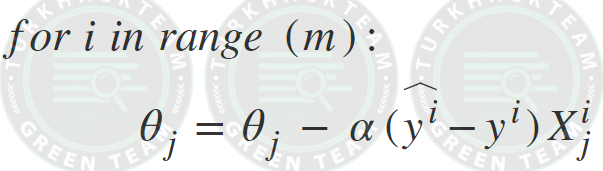
Python3 örneği;
Python:
# import the necessary packages
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
import argparse
def sigmoid_activation(x):
# belirli bir giriş için sigmoid aktivasyon değerini hesaplamak
return 1.0 / (1 + np.exp(-x))
def sigmoid_deriv(x):
return x * (1 - x)
def predict(X, W):
# özellikleri ve ağırlık matrisi arasındaki nokta çarpımını almak
preds = sigmoid_activation(X.dot(W))
preds[preds <= 0.5] = 0
preds[preds > 0] = 1
return preds
def next_batch(X, y, batchSize):
for i in np.arange(0, X.shape[0], batchSize):
yield (X[i:i + batchSize], y[i:i + batchSize])
# argümanı inşa etmek ve ayrıştırmak
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--epochs", type=float, default=100,
help="# of epochs")
ap.add_argument("-a", "--alpha", type=float, default=0.01,
help="learning rate")
ap.add_argument("-b", "--batch-size", type=int, default=32,
help="size of SGD mini-batches")
args = vars(ap.parse_args())
# Her veri noktasının bir 2B özellik vektörü olduğu 1.000 veri noktasıyla 2 sınıflı bir sınıflandırma problemi oluşturmak
(X, y) = make_blobs(n_samples=1000, n_features=2, centers=2,
cluster_std=1.5, random_state=1)
y = y.reshape((y.shape[0], 1))
X = np.c_[X, np.ones((X.shape[0]))]
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.5, random_state=42)
# ağırlık matrisini ve kayıp listesini başlatmak
print("[INFO] training...")
W = np.random.randn(X.shape[1], 1)
losses = []
for epoch in np.arange(0, args["epochs"]):
# toplam kayıp
epochLoss = []
for (batchX, batchY) in next_batch(trainX, trainY, args["batch_size"]):
preds = sigmoid_activation(batchX.dot(W))
error = preds - batchY
epochLoss.append(np.sum(error ** 2))
d = error * sigmoid_deriv(preds)
gradient = batchX.T.dot(d)
W += -args["alpha"] * gradient
# tüm gruplardaki ortalama kaybı alarak kayıp geçmişini güncelleme
loss = np.average(epochLoss)
losses.append(loss)
# bir güncellemenin görüntülenmesi gerekip gerekmediğini kontrol etme
if epoch == 0 or (epoch + 1) % 5 == 0:
print("[INFO] epoch={}, loss={:.7f}".format(int(epoch + 1),
loss))
# modeli değerlendirme
print("[INFO] evaluating...")
preds = predict(testX, W)
print(classification_report(testY, preds))
# (test) sınıflandırma verilerinin çizimi
plt.style.use("ggplot")
plt.figure()
plt.title("Data")
plt.scatter(testX[:, 0], testX[:, 1], marker="o", c=testY[:, 0], s=30)
# zaman içindeki kaybı gösterme
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, args["epochs"]), losses)
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.show()Çıktı;
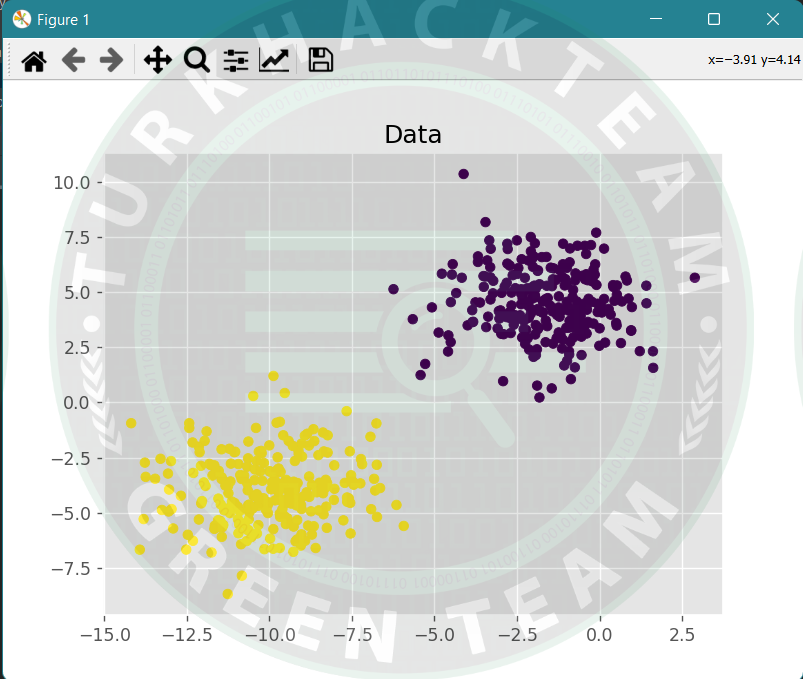
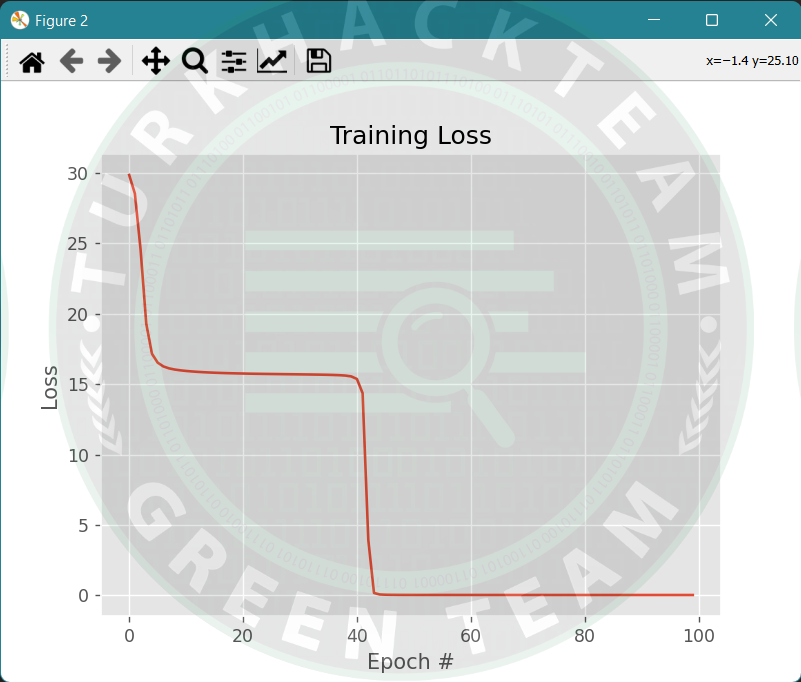

Mini Yığın eğim azaltma, SGD ve Yığın eğim azaltma kavramlarının bir kombinasyonu olduğu için tercih edilen yöntemdir. Eğitim veri setini küçük gruplara böler ve bu grupların her biri için bir güncelleme gerçekleştirir. Bu, SGD’nin sağlamlığı ile BatchGD’nin verimliliği arasında bir denge oluşturur.
Genel mini parti boyutları 50 ile 256 arasında değişir, ancak diğer tüm makine öğrenimi tekniklerinde olduğu gibi, farklı uygulamalar için değişiklik gösterdiğinden net bir kural yoktur. Bu, bir sinir ağını eğitirken tercih edilen algoritmadır ve derin öğrenmede en yaygın eğim azaltma türüdür.
Mini eğim azaltmanın avantajları:
Ayrılan belleğe sığdırmak daha kolaydır.
Hesaplama açısından verimlidir.
Kararlı eğim azaltma yakınsaması üretir.
Formül;
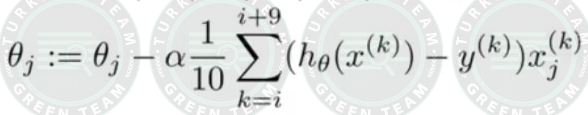
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import matplotlib.pyplot as plt
# data oluşturmak
mean = np.array([5.0, 6.0])
cov = np.array([[1.0, 0.95], [0.95, 1.2]])
data = np.random.multivariate_normal(mean, cov, 8000)
# verileri görselleştirme
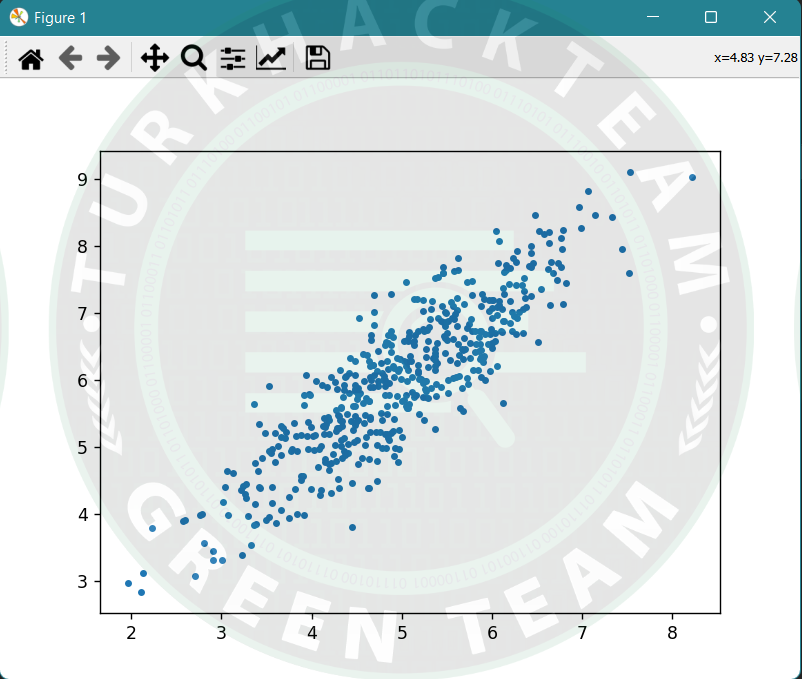
plt.scatter(data[:500, 0], data[:500, 1], marker = '.')
plt.show()
# eğitim-test-ayrım
data = np.hstack((np.ones((data.shape[0], 1)), data))
split_factor = 0.90
split = int(split_factor * data.shape[0])
X_train = data[:split, :-1]
y_train = data[:split, -1].reshape((-1, 1))
X_test = data[split:, :-1]
y_test = data[split:, -1].reshape((-1, 1))
print("Number of examples in training set = % d"%(X_train.shape[0]))
print("Number of examples in testing set = % d"%(X_test.shape[0]))
# "mini batch" kullanarak doğrusal regresyon
# hipotezi / tahminleri hesaplama
def hypothesis(X, theta):
return np.dot(X, theta)
# hata eğimi hesaplama işlevi w.r.t. teta
def gradient(X, y, theta):
h = hypothesis(X, theta)
grad = np.dot(X.transpose(), (h - y))
return grad
# teta'nın mevcut değerleri için hatayı hesaplama
def cost(X, y, theta):
h = hypothesis(X, theta)
J = np.dot((h - y).transpose(), (h - y))
J /= 2
return J[0]
# mini partiler içeren bir liste oluşturma
def create_mini_batches(X, y, batch_size):
mini_batches = []
data = np.hstack((X, y))
np.random.shuffle(data)
n_minibatches = data.shape[0] // batch_size
i = 0
for i in range(n_minibatches + 1):
mini_batch = data[i * batch_size:(i + 1)*batch_size, :]
X_mini = mini_batch[:, :-1]
Y_mini = mini_batch[:, -1].reshape((-1, 1))
mini_batches.append((X_mini, Y_mini))
if data.shape[0] % batch_size != 0:
mini_batch = data[i * batch_size:data.shape[0]]
X_mini = mini_batch[:, :-1]
Y_mini = mini_batch[:, -1].reshape((-1, 1))
mini_batches.append((X_mini, Y_mini))
return mini_batches
# mini batch gerçekleştirme işlevi
def gradientDescent(X, y, learning_rate = 0.001, batch_size = 32):
theta = np.zeros((X.shape[1], 1))
error_list = []
max_iters = 3
for itr in range(max_iters):
mini_batches = create_mini_batches(X, y, batch_size)
for mini_batch in mini_batches:
X_mini, y_mini = mini_batch
theta = theta - learning_rate * gradient(X_mini, y_mini, theta)
error_list.append(cost(X_mini, y_mini, theta))
return theta, error_list
theta, error_list = gradientDescent(X_train, y_train)
print("Bias = ", theta[0])
print("Coefficients = ", theta[1:])
# gradient descent çizimi
plt.plot(error_list)
plt.xlabel("Number of iterations")
plt.ylabel("Cost")
plt.show()
# X_test için çıktıyı tahmin etme
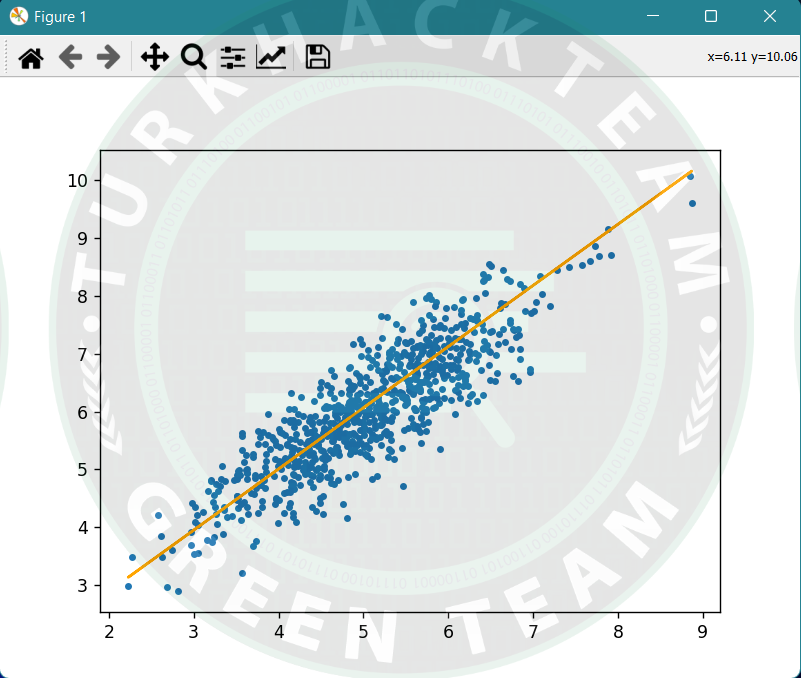
y_pred = hypothesis(X_test, theta)
plt.scatter(X_test[:, 1], y_test[:, ], marker = '.')
plt.plot(X_test[:, 1], y_pred, color = 'orange')
plt.show()
# tahminlerde hesaplama hatası
error = np.sum(np.abs(y_test - y_pred) / y_test.shape[0])
print("Mean absolute error = ", error)Çıktı;
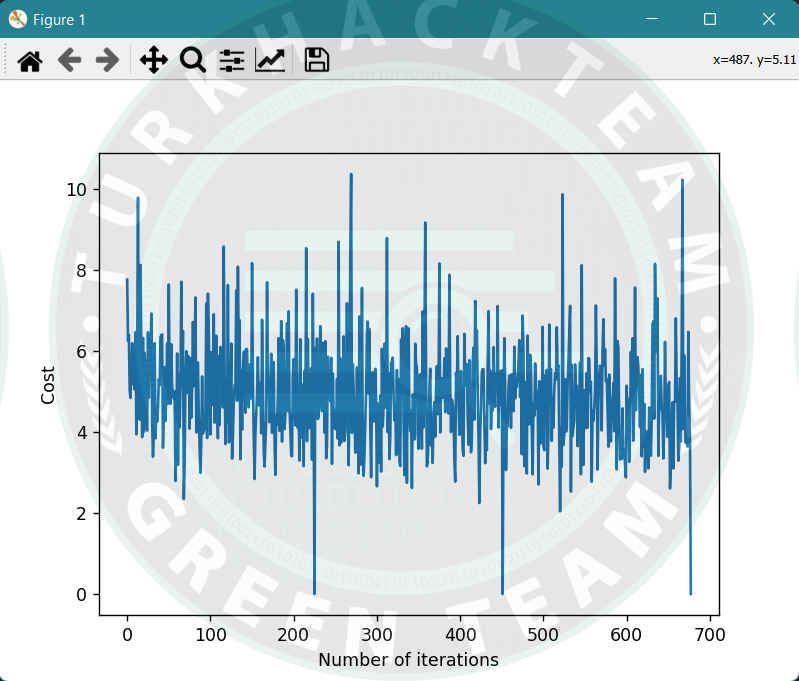
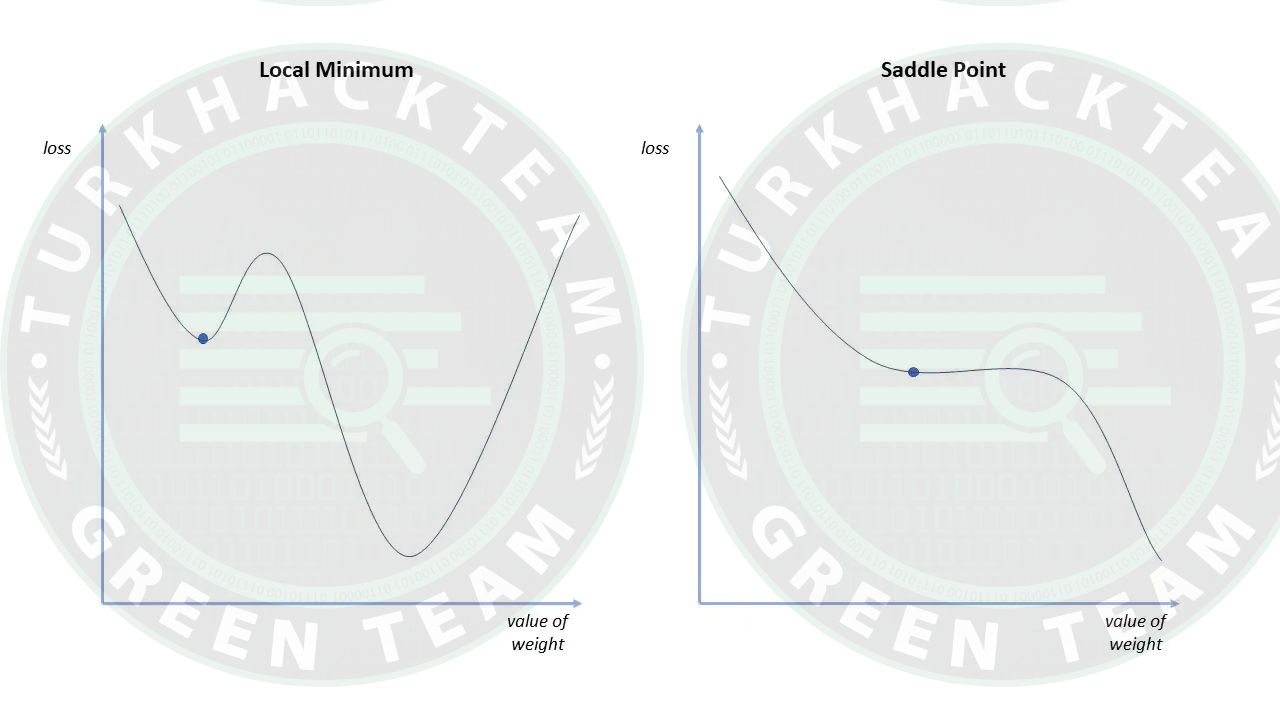
Challanges
Local Minima and Saddle Point:
Gradient Descent; dışbükey problemlerde küresel minimumu kolaylıkla bulabilirken, dışbükey olmayan problemlerin çözümünde zorluklar ile karşılaşabilmektedir.
Cost Function eğimi sıfır veya sıfıra yakın olduğunda modelin programı sonlandırdığını söylemiştim.
Yerel minimum, maliyet fonksiyonunun eğiminin mevcut noktanın her iki tarafında arttığı küresel minimum şeklini taklit eder. Öte yandan “Eyer(Saddle)” noktalarında, negatif eğim noktanısının yalnızca bir tarafında bulunur. Bir tarafta yerel maksimuma ulaşırken diğer tarafta yerel minimuma ulaşır.
Gürültülü gradyanlar, gradyanın yerel minimumlardan ve eyer noktalarından kaçmasına yardımcı olabilir.
Vanishing and Exploding Gradients:
Daha derin ve tekrarlayan sinir ağlarında model, eğim azaltma ve geri yayılım ile eğitildiğinde başka iki problemle de karşılaşabilir.
Vanishing gradients: Bu, eğim çok küçük olduğunda meydana gelir. Geri yayılım sırasında geriye doğru hareket ettikçe, eğim küçülmeye devam eder ve ağdaki önceki katmanların sonraki katmanlardan daha yavaş öğrenmesine neden olur. Bu olduğunda, ağırlık parametreleri önemsiz hale gelene kadar güncellenir.
Exploding gradients: Bu, eğim çok büyük olduğunda olur ve kararsız bir model oluşturur. Bu durumda, model ağırlıkları çok büyüyecek ve sonunda “NaN” olarak temsil edilecektir. Bu soruna bir çözüm olarak, model içindeki karmaşıklığı en aza indirmeye yardımcı olabilecek bir boyutluluk azaltma tekniğinden yararlanılabilir.
^
|
|
|
|
v
|
|
|
|
v
Değerli dostlarım, güzel kardeşlerim;
Bu makalemde "Gradient Descent optimizasyon algoritması" konusuna değindik.
Hem teknik bilgi sahibi olduk hem de pratik yaptık.
Kaynak niteliğinde bu forumda kalması temennisi ile diyerek sözlerimi bitiriyorum.
Sağlıcakla kalın.

Son düzenleme:
")

