

- 19 Şub 2016
- 1,029
- 4
Hadoop büyük veriler üzerinde paralel hesaplama yaparak çeşitli analizler yapmamızı sağlayan açık kaynaklı yazılım projesidir
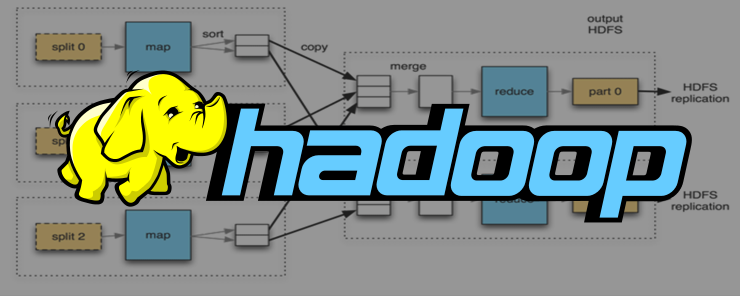
Hadoop veri analizi işlemlerini birbirinden farklı bilgisayarlarda yapabilir , böylece dağıtık veri işleme kavramını desteklemektedir
Büyük veri setlerini saklamak ve işlemek için bir altyapı yazılımı diyebiliriz.

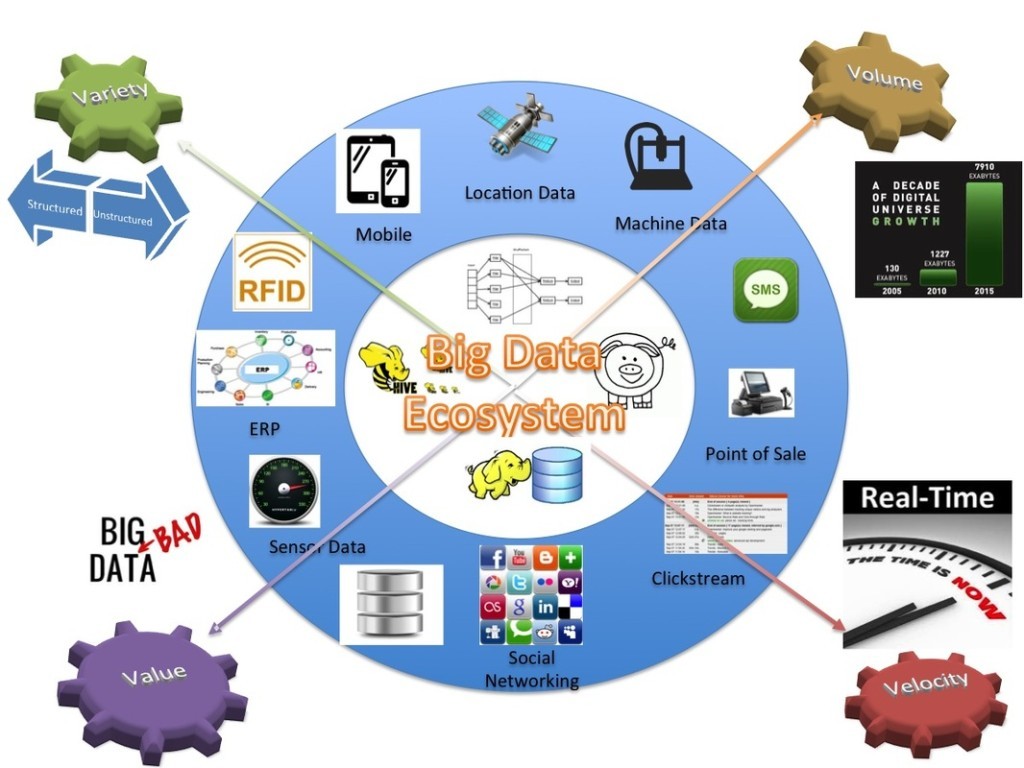
Big data temel olarak büyük veri olarak çevrilmiş olsa da aslında boyutsal bir büyüklüğü sembolize etmemektedir. Aslen programcılar tarafından dev veri olarak anılmaktadır. Burada ki büyük ve dev tabirleri klasik yöntemler kullanılarak işlenemeyen verileri tanımlıyor.
Peki bu kadar verinin nerede tutulduğunu hiç düşündünüz mü? Evimizde var olan disk sürücüleri terrabyte boyutlarında bazen bize yetmeyebiliyor. Büyük veri için bahsedeceğimiz boyutlar petabyte, exabyte ya da zettabyte düzeylerinde olabiliyor. Önümüzdeki 5 sene içinde dünya genelinde depolanan big data boyutunun 35 zettabyte düzeyinde olması bekleniyor.
Apache tarafından açık kaynak sunulmaktadır.
Nasıl sakladığını-storage'i şöyle özetleyebiliriz. normalde bilgisayarınız 1tb dosya tutabilecekken hadoop'un cluster yapısı ve hdfs yardımı ile 100 tb'ı dağıtık olarak sınırsız binlerce node'da saklayabilirsiniz.
Big Data Nedir?
Big data temel olarak büyük veri olarak çevrilmiş olsa da aslında boyutsal bir büyüklüğü sembolize etmemektedir. Aslen programcılar tarafından dev veri olarak anılmaktadır. Burada ki büyük ve dev tabirleri klasik yöntemler kullanılarak işlenemeyen verileri tanımlıyor.
Big data somut olarak bakıldığı zaman hayatımızın her alanını kapsayabiliyor. Örneğin bir otomobil firması sensörler sayesinde sürücülerin sürüş istatistiklerini toplamaya başladı. Bunun gibi medikal veriler, üretim verileri, teknolojik gelişmeler toplandığında big data oluşuyor.
Peki bu kadar verinin nerede tutulduğunu hiç düşündünüz mü? Evimizde var olan disk sürücüleri terrabyte boyutlarında bazen bize yetmeyebiliyor. Büyük veri için bahsedeceğimiz boyutlar petabyte, exabyte ya da zettabyte düzeylerinde olabiliyor. Önümüzdeki 5 sene içinde dünya genelinde depolanan big data boyutunun 35 zettabyte düzeyinde olması bekleniyor.
Zannedildiği üzere terabayt seviyesinden küçük datasetlerde yavaş çalışmamaktadır. eğer datasetin boyutu 64 megabytetan küçük ise elbetteki gereksiz olacaktır. bunun sebebi ise hdfs'de kullanılan data block size 64 megabytetır.
Apache tarafından açık kaynak sunulmaktadır.
Nasıl sakladığını-storage'i şöyle özetleyebiliriz. normalde bilgisayarınız 1tb dosya tutabilecekken hadoop'un cluster yapısı ve hdfs yardımı ile 100 tb'ı dağıtık olarak sınırsız binlerce node'da saklayabilirsiniz.

