



Kafka 101

2011 yılında LinkedIn'de geliştirilen Apache Kafka, en popüler açık kaynak Apache projelerinden biri olarak öne çıkmaktadır. Şu ana kadar toplamda 24 önemli sürüm yayınlanmış olup, en dikkat çekici olanı, her bir sürümde kod tabanının ortalama %24 oranında büyümesidir.
Kafka, internetin gerçek zamanlı veri akışı için fiili standardı olarak hizmet veren dağıtık bir akış platformudur.
Gelişimi, LinkedIn'in o dönemde karşılaştığı sorunlara bağlı olarak şekillenmiştir. Büyük ölçekli dağıtımlı sistemlerle (distributed systems ) ilgili sorunları yaşayan ilk şirketlerden biri olarak, kontrolsüz mikro hizmet çoğalması sorununu fark ettiler.

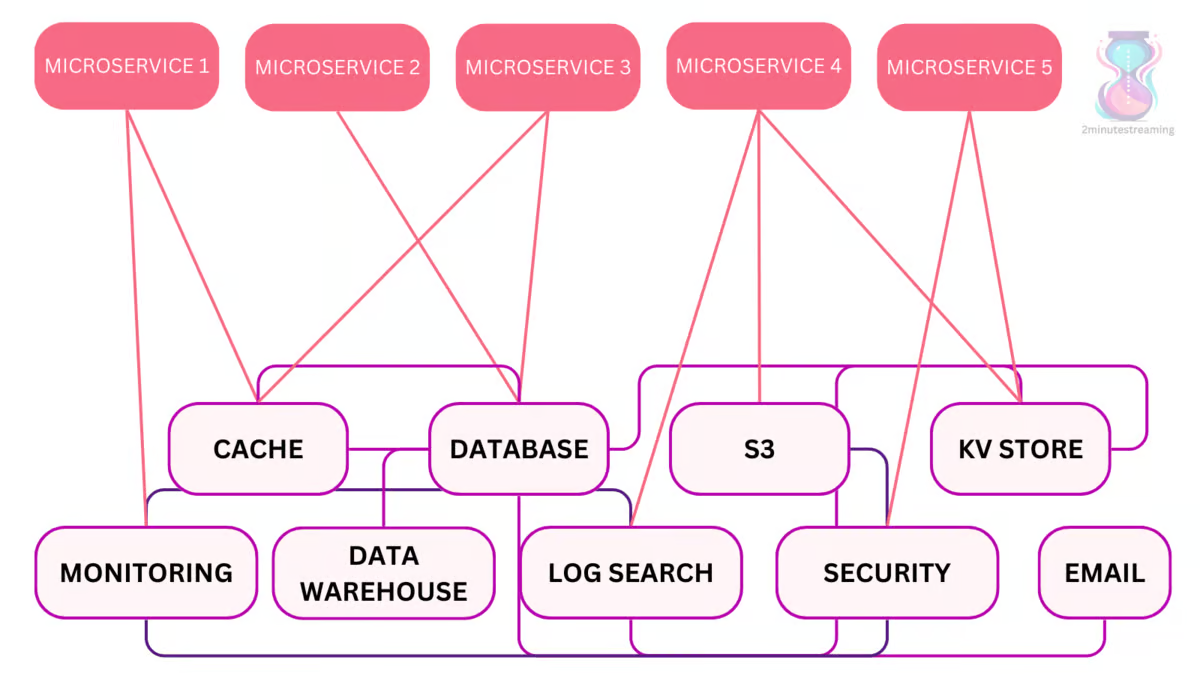
Hizmetler arası ve kalıcı depolama yapılandırmalarının artan karmaşıklığını çözmek için, doğruluk kaynağı olarak hizmet edebilecek tek bir platform geliştirmeye karar verdiler.
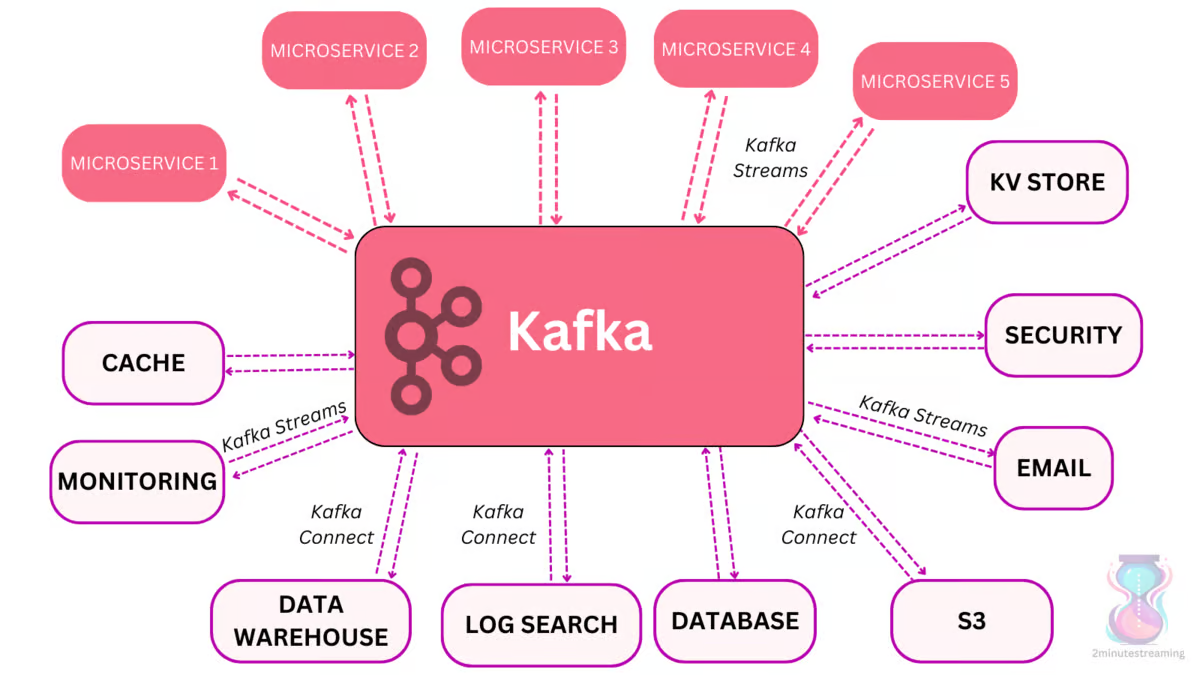
Apache Kafka, hizmet koordinasyonu sorununu çözmek amacıyla tasarlanmış bir dağıtım sistemidir. Vizyonu, bir şirketin içinde merkezi bir sinir sistemi olarak kullanılmasıdır. Verilerin aktığı, işlendiği/dönüştürüldüğü ve diğer alt sistemler (veri depoları, dizinler, mikro hizmetler (microservices) vb.) tarafından tüketildiği bir yer olarak tasarlanmıştır.
Bu nedenle, yüksek veri akışını (saniyede milyonlarca mesaj) karşılayacak şekilde optimize edilmiştir ve çok miktarda veriyi (terabaytlarca) depolayabilme kapasitesine sahiptir.
Log (Kayıt Defteri)
Sistemdeki veriler, konular (topics) olarak adlandırılan kategorilerde saklanır. Bir konunun temel yapı taşı ise log (kayıt defteri) olarak bilinen, kayıtları sıralı bir şekilde depolayan basit bir veri yapısıdır.
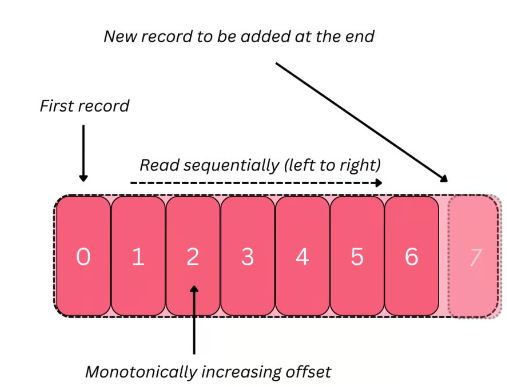
Log, değişmez (immutable) bir yapıdır ve O(1) yazma ve okuma sürelerine sahiptir (bu işlemler log’un sonundan veya başından yapılırsa). Bu nedenle, log’un büyüklüğü arttıkça veriye erişim hızı bozulmaz ve değişmezliği sayesinde eşzamanlı okumalarda verimli bi hâl alır.
Ancak bu avantajlara rağmen, log’un önemli yararı ve belki de Kafka için seçilme nedeninin başlıca nedeni, HDD’ler (sabit diskler) için optimize edilmiş olmasıdır.
HDD’ler, doğrusal okuma ve yazma işlemlerinde oldukça verimlidir ve log’un yapısı nedeniyle, doğrusal okuma/yazma işlemleri log üzerinde yapılan temel işlemlerdir.
Performans
İyi optimize edilmiş bir yerel Kafka dağıtımı genellikle ağ üzerinde darboğaza uğrar, yani okuma ve yazma verimliliği saniyede birçok gigabayta kadar ölçeklenebilir.
Bu tür bir performansa nasıl ulaşılır? Birden fazla optimizasyon bulunmaktadır. Bazıları makro düzeyde, diğerleri ise mikro düzeydedir.
Disk Üzerinde Kalıcılık
Kafka, tüm kayıtlarını diskte saklar ve hiçbir şeyi açıkça bellek içinde tutmaz.
Kafka’nın protokolü, mesajları gruplar. Bu, ağ isteklerinin mesajları bir araya getirmesine ve ağ yükünü azaltmasına olanak tanır.
Sunucu ise, mesajları bir seferde büyük parçalar halinde saklar. Bu da, doğrusal bir HDD yazma işlemidir. Tüketiciler(kullanıcılar) de büyük doğrusal parçaları bir kerede alır.
Disk üzerinde doğrusal okuma/yazma işlemleri hızlı olabilir. HDD’ler genellikle yavaş olarak değerlendirilir çünkü birçok disk arama işlemi yapıldığında, diskin kafa hareketlerinin fiziksel sınırları nedeniyle darboğaza uğranır. Ancak, doğrusal okuma/yazma işlemlerinde bu sorun yaşanmaz,
Önceden Okuma Optimizasyonları büyük blokları talep edilmeden önce önceden okur ve bellek içinde saklar, bu da bir sonraki okumanın diske dokunmadan gerçekleştirilmesini sağlar.
Arka Plan Yazma Optimizasyonları küçük mantıksal yazmaları büyük fiziksel yazmalarda toplar. Kafka fsync kullanmaz, yazmalar diske asenkron olarak yazılır.
Pagecache
Modern işletim sistemleri diski serbest RAM'de önbelleğe alır. Buna pagecache (sayfa önbelleği) denir.
Kafka, mesajları üreticiden (producer) > aracıya (broker) > tüketiciye (consumer) kadar standart bir ikili formatta değiştirmeden sakladığı için, sıfır-kopya (zero-copy) optimizasyonundan faydalanabilir.
Sıfır-kopya, biraz yanıltıcı bir adlandırmadır; burada işletim sistemi veriyi doğrudan pagecache'den bir sokete (socket) kopyalar, böylece Kafka'nın JVM'ini tamamen geçer. Verilerin hala kopyaları yapılır, ancak bu kopyalar azaltılır. Bu, birkaç ekstra kopyayı ve kullanıcı ile çekirdek modu geçişlerini (user <-> kernel mode) azaltır.
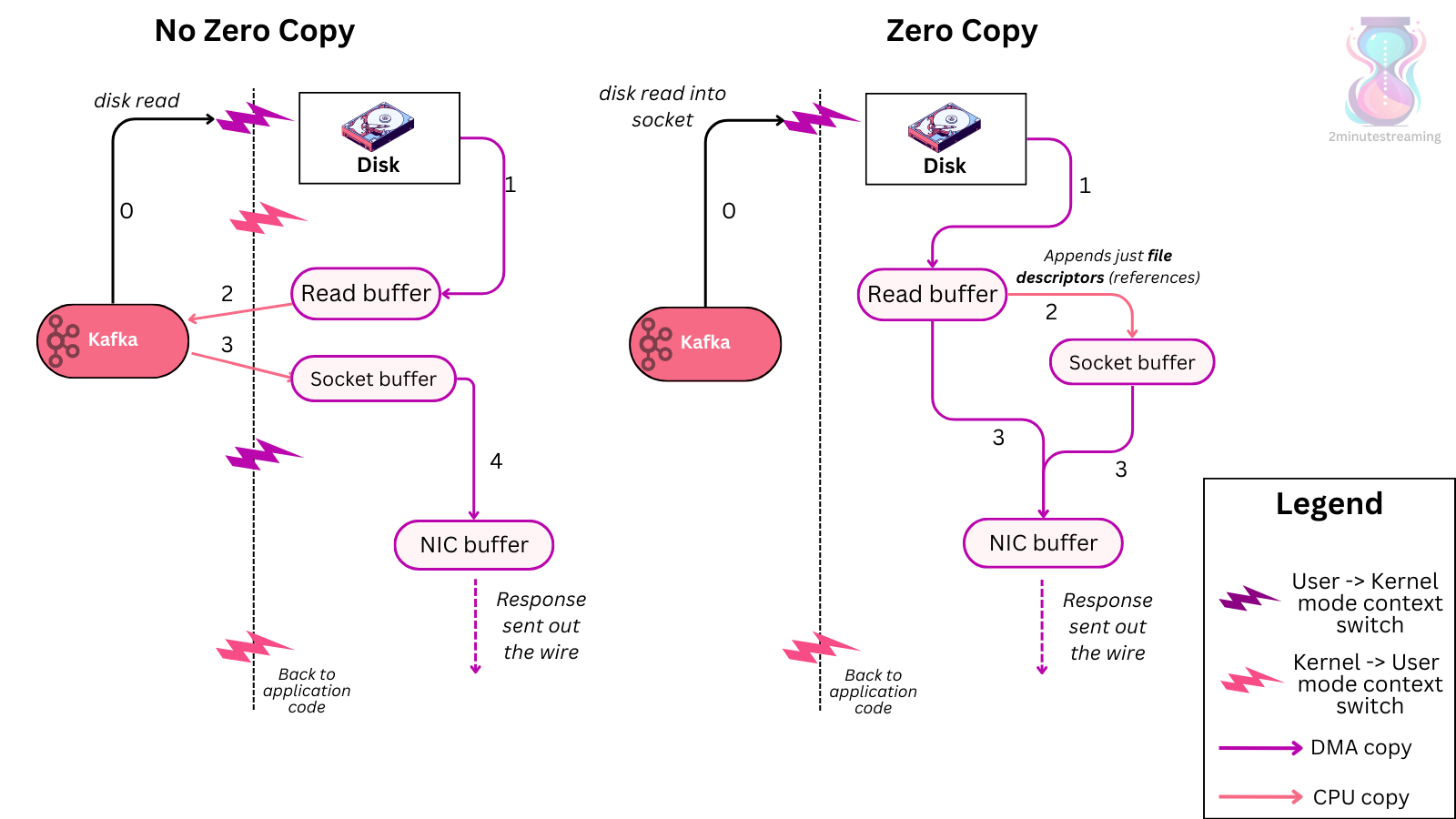
Bu kulağa hoş gelse de, sıfır-kopya (zero-copy) optimizasyonunun Kafka'yı büyük ölçüde optimize ettiği pek olası değildir; bunun iki ana nedeni vardır. İlk olarak, iyi optimize edilmiş Kafka dağıtımlarında CPU nadiren darboğaz oluşturur, bu nedenle bellek içindeki kopyaların eksikliği size fazla kaynak kazandırmaz.
İkincisi, şifreleme ve SSL/TLS (tüm üretim dağıtımları için zorunlu) mesajı yol boyunca değiştirdiğinden, Kafka'nın sıfır-kopya kullanmasını engeller. Buna rağmen, Kafka hala yüksek performans sergiler.
Temel Bilgiler
Dağıtılmış sistemdeki (distributed systems) düğümler broker olarak adlandırılır. Her konu (topic), parçalara (partitions) bölünür ve bu parçalar, dayanıklılık ve erişilebilirlik amacıyla N kez (çoğaltma faktörüne göre) kopyalanır.
Basit bir benzetme ile, bir işletim sistemindeki temel depolama birimi bir dosyaysa, Kafka'daki temel depolama birimi bir kopyadır (partition'ın bir kopyası).
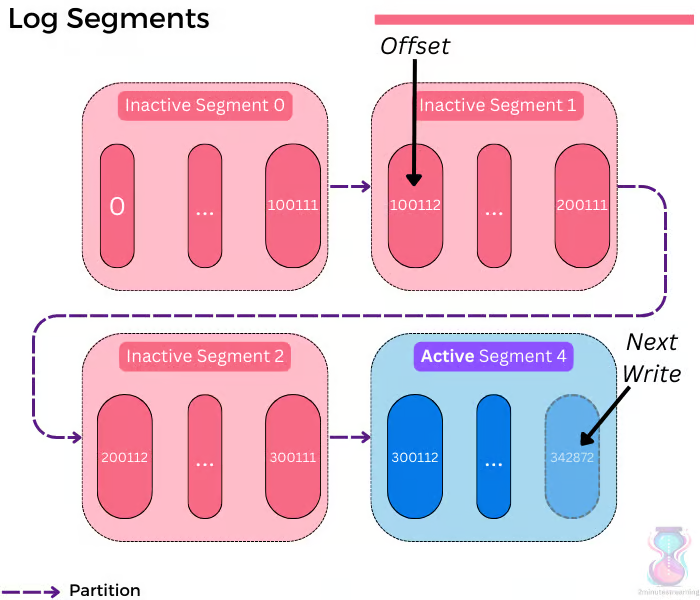
Her kopya, log veri yapısını barındıran ve sıralı bir şekilde daha büyük bir log oluşturan birkaç dosyadan ibarettir. Log'daki her kayıt, belirli bir offset ile belirtilir; bu, sadece monotonik olarak artan bir numaradır.
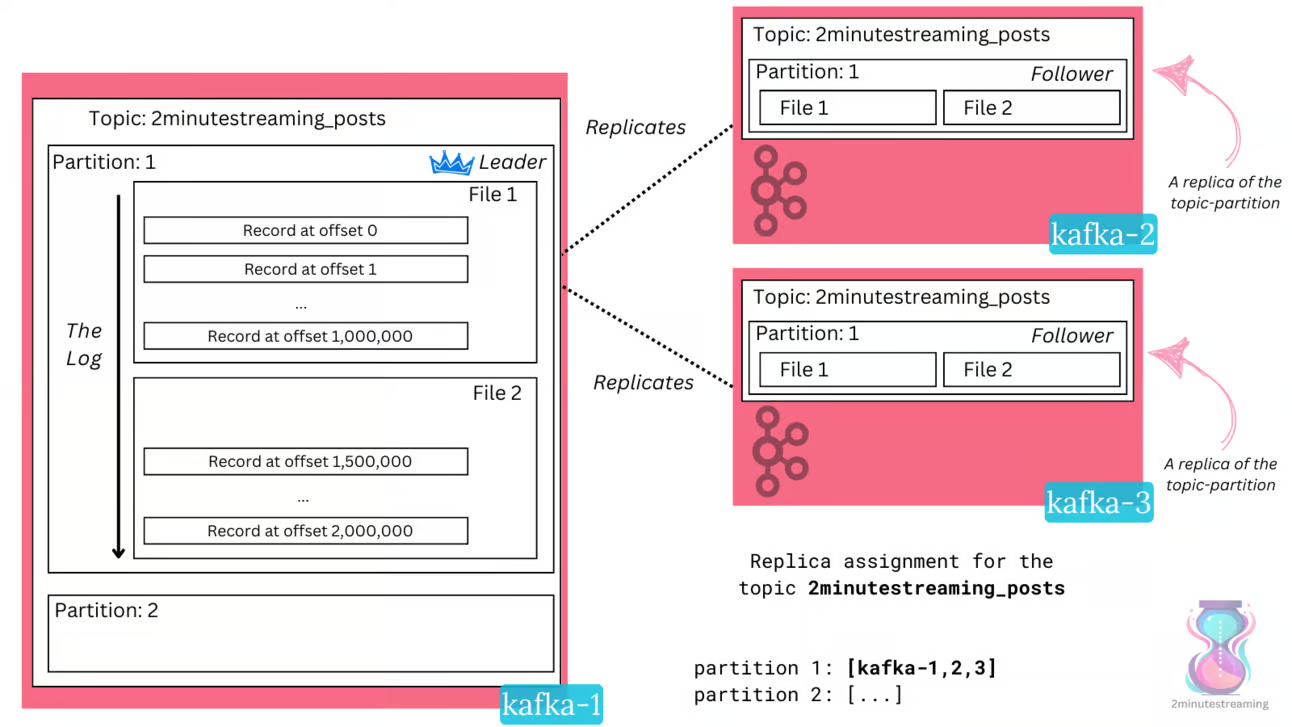
Çoğaltma, lider bazlıdır; yani, her seferinde yalnızca bir broker, belirli bir partition'ın lideri olur.
Her partition'ın bir kopya kümesi (replica set) vardır. Bir kopya iki durumda olabilir: senkron (in-sync) veya senkron olmayan (out-of-sync). İsimlerinden de anlaşılacağı gibi, senkron olmayan kopyalar, partition için en güncel veriye sahip olmayan kopyalardır.
Yazma İşlemleri
Yazma işlemleri, yalnızca lider broker'a yapılabilir, ardından lider veri N-1 takipçiye (follower) asenkron olarak kopyalar. Verileri yazan istemcilere üreticiler(producers) denir. Üreticiler, yazma işlemleri sırasında almak istedikleri dayanıklılık garantilerini “acks”özelliği aracılığıyla yapılandırabilir. Bu özellik, bir yazma işlemi tamamlandıktan sonra yanıtın istemciye dönebilmesi için kaç broker'ın onay vermesi gerektiğini belirtir:
- acks=0 - Üretici, broker'dan yanıt beklemeden yazmayı hemen başarılı olarak kabul eder.
- acks=1 - Lider broker kaydı onayladığında (diske kaydettiğinde) üreticiye bir yanıt gönderilir.
- acks=all (varsayılan) - Tüm senkron kopyalar kaydı kalıcı hale getirdiğinde üreticiye bir yanıt gönderilir.
acks=all özelliğini daha da kontrol etmek ve yalnızca bir senkron kopya olduğunda acks=1 özelliğine geri dönmesini engellemek için, `min.insync.replicas` ayarı, acks=all ile yapılandırılmış bir yazmanın onaylanması için gereken minimum senkron kopya sayısını belirtir.
Okuma İşlemleri
Verileri okuyan istemcilere tüketiciler(consumers) denir. Benzer şekilde, bu istemci uygulamaları Kafka kütüphanesini kullanarak verileri okur ve üzerinde işlem yapar.
Kafka tüketicileri, herhangi bir kopyadan okuma yapabilme yeteneğine sahiptir ve genellikle ağ topolojisindeki en yakın kopyadan okumak üzere yapılandırılır.
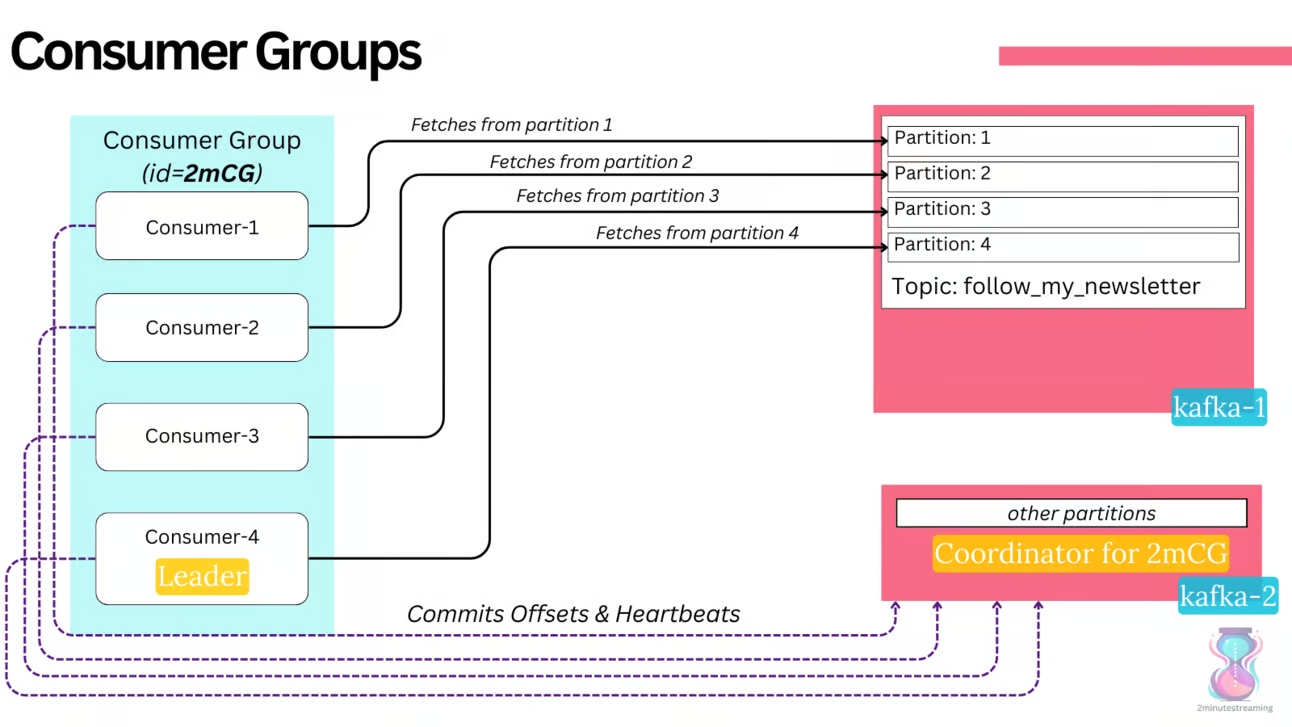
Tüketiciler, tüketici grupları (consumer groups) oluşturur; bunlar, mantıksal olarak gruplanmış ve senkronize edilmiş tüketicilerden oluşan topluluklardır. Birbirleriyle doğrudan bağlantılı olmadan, broker ile iletişim kurarak senkronize olurlar. İlerlemelerini (hangi ofsete kadar tükettiklerini) özel bir Kafka konusunun (`__consumer_offsets`) belirli bir partition'ında saklarlar. Partition'ın lideri olan broker, bu tüketici grubunun **Grup Koordinatörü** (Group Coordinator) olarak görev yapar ve bu Koordinatör, tüketici grubunun üyeliğini ve canlılığını sürdürmekten sorumludur.
Her partition'daki kayıtlar, içinde sıralıdır. Tüketiciler, bu kayıtları doğru sırayla okumayı garanti eder. Sıralamanın korunmasını sağlamak için, tüketici grubu protokolü, aynı tüketici grubundaki iki tüketicinin aynı partition'dan okumasını engeller.
Aynı konu (topic) üzerinde birçok farklı tüketici grubu olabilir.
Kafka'nın geleneksel mesajlaşma teknolojilerine göre üstün olmasının temel nedenlerinden biri, üretici ve tüketici istemcilerinin bu şekilde ayrıştırılmasıdır. Bazı sistemlerde mesajlar tüketildiği anda silinir ve bu durum sıkı bir bağlılık yaratır. Tüketiciler yavaşsa, sistem bellek tükenme riskiyle karşılaşabilir ve üreticileri etkileyebilir. Kafka bu sorundan muzdarip değildir çünkü verileri diskte kalıcı olarak saklar ve yukarıda belirtilen optimizasyonlar sayesinde performansını korur.
Protokol
İstemciler, Kafka protokolünü kullanarak broker'lara TCP üzerinden bağlanır. Üretici ve tüketici istemcileri, Kafka protokolünü uygulayan basit Java kütüphaneleridir. Diğer neredeyse tüm dillerde de uygulamaları mevcuttur.
Hata Toleransı
Bir Apache Kafka kümesi her zaman aktif bir Denetleyici (Controller) olan bir broker içerir. Denetleyici, tek bir doğruluk kaynağı gerektiren tüm idari işlemleri destekler; örneğin konuları oluşturma ve silme, konulara partition ekleme, partition kopyalarını yeniden atama gibi işlemleri gerçekleştirir.
En etkili sorumluluğu, her partition'ın liderlik seçimini yönetmektir. Küme hakkındaki merkezi metadata'nın tamamı Denetleyici tarafından işlendiği için, partition'ın liderliğinin kime geçeceğine ve ne zaman geçeceğine karar verir. Bu, bir lider broker’ın arızalanması veya kapanması durumunda özellikle belirgindir. Bu durumlarda, Denetleyici, partition liderliğini replica setindeki diğer bir brokera düzgün bir şekilde devreder.
Konsensüs (Consencus)
Her dağıtık sistem (disturbed system), konsensüs gerektirir. Belirli bir zamanda tam olarak bir broker’ı denetleyici olarak seçmek, temelde bir dağıtık konsensüs problemidir.
Kafka tarihsel olarak konsensüsü ZooKeeper’e devretmiştir. Küme başlatılırken, her broker `/controller` zNode’unu kaydetmek için yarışır ve bunu ilk başaran broker denetleyici olarak ilan edilirdi. Benzer şekilde, mevcut Denetleyici öldüğünde, zNode’u ilk kaydeden broker yeni denetleyici olurdu.
Kafka, ZooKeeper’de tüm türde metadata’yı, canlı broker seti, konu adları ve partition sayıları, partition atamaları gibi bilgileri saklardı. Ayrıca, ZooKeeper’in watch mekanizmasını yoğun bir şekilde kullanarak, belirli bir zNode değiştiğinde bir aboneye bildirim gönderilirdi.
Son birkaç yıldır, Kafka ZooKeeper’den kendi konsensüs mekanizması olan KRaft (“Kafka Raft”)’e geçiş yapmaktadır. KRaft, Raft’ın bir lehçesidir ve Kafka’nın mevcut çoğaltma protokolünden yoğun şekilde etkilenmiştir. Temelde, Kafka çoğaltma protokolünü bazı Raft ile ilgili özelliklerle genişletir.
Önemli bir farkındalık, kümenin metadata’sının, kümede meydana gelen olayların sıralı kayıtları aracılığıyla düzenli bir log’da kolayca ifade edilebileceğidir. Broker’lar bu olayları yeniden oynatarak sistemin en son durumunu oluşturabilirler.
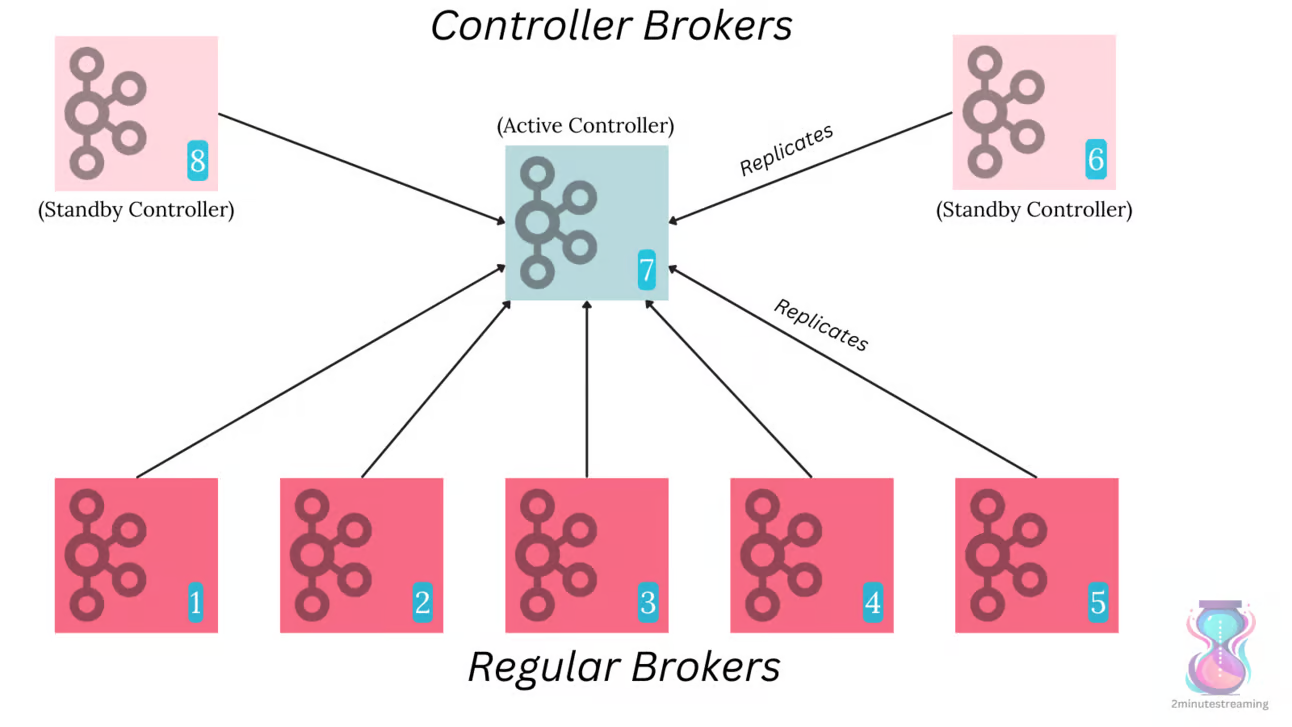
Bu yeni modelde, Kafka’nın N denetleyicili bir quorum’u (genellikle 3) vardır. Bu broker’lar, metadata konusu (“__cluster_metadata”) adında özel bir konu barındırır.
Bu konunun liderlik seçimi Raft tarafından yönetilir (diğer tüm konular için Denetleyici tarafından değil). Konunun lideri, mevcut aktif Denetleyici olur. Diğer denetleyiciler ise, en son metadata’yı bellek içinde saklayan sıcak yedekler olarak görev yapar.
Tüm düzenli broker'lar bu konuyu da çoğaltır. Denetleyici ile doğrudan iletişim kurmak yerine, konunun en son kayıtlarını takip ederek metadata’larını asenkron bir şekilde güncellerler.
KRaft, iki dağıtım modunu destekler: birleşik ve izole mod. Birleşik mod, ZooKeeper altında kullanılan modele benzer; burada bir broker, hem düzenli broker hem de denetleyici rolünü aynı anda üstlenebilir. İzole modda ise, denetleyiciler yalnızca denetleyici olarak dağıtılır ve başka bir işlevi yoktur.
Üretime hazır bir KRaft sürümünü içeren ilk Kafka sürümü, Ekim 2022'de çıkan Kafka 3.3'tür. ZooKeeper’in tamamen kaldırılması beklenen bir sonraki büyük Kafka sürümü olan 4.0’da (yaklaşık olarak 2024’ün üçüncü çeyreğinde) gerçekleşecektir.
Katmanlı Depolama ( Tiered Storage)
Daha önce belirtildiği gibi, Kafka'nın mimarisi maliyet etkin bir yerel dağıtım için optimize edilmiştir. Ancak, bulutun yaygınlaşması yazılım mimarilerini büyük ölçüde değiştirmiştir.
Kafka'nın büyümesiyle birlikte dikkat çeken mimari sorunlardan biri, depolamanın broker ile aynı yerde konumlandırılması kararının getirdiği zorluklardır. Broker'lar, tüm verileri yerel disklerinde barındırır, bu da ölçeklendirme ile birlikte birkaç zorluk yaratır.
İlk olarak, Kafka bir şirketin mimarisinin merkezi sinir sistemi olarak tasarlandığından, broker'ların üzerinde 3TB tarihsel veri saklaması istenebilir. Bu durumda, varsayılan çoğaltma faktörü olan 3 ile toplam 9TB veri elde edilir.
Bir broker yerel olarak 10TB'ye yakın veri barındırdığında, sorunlar baş göstermeye başlar.
Bir açık sorun, düzgün kapanmayan sistemlerin yönetilmesidir. Bir broker düzgün kapanmayan bir sistemden geri döndüğünde, tüm yerel log indeks dosyalarını yeniden oluşturması gerekir; bu süreç "log recovery" olarak adlandırılır. 10TB'lık bir disk ile bu, bazı durumlarda saatler hatta günler sürebilir.
Bir diğer sorun ise tarihsel okumalar ile ilgilidir. Kafka'nın performansı, tüketicilerin log'un sonundan okudukları varsayımına dayanır; bu pratikte, en son üretilmiş verilerin yer aldığı pagecache'den okumak anlamına gelir. Bir tüketici tarihsel veriler aldığında, bu genellikle Kafka broker'ının veriyi HDD'den okumasını gerektirir. HDD'ler tarihsel olarak 120 IOPS'ta kalmıştır; yani bu kaynağın tükenmesi oldukça kolaydır. Bu, tüketicilerin IOPS için üreticilerle rekabet ettiği ve bu kaynak tükendiğinde performansın düştüğü anlamına gelir.
IOPS problemi, ciddi arıza senaryolarında daha da kötüleşir. Bir broker’ın diski ciddi bir arıza yaşadığında, boş bir diskle başlar ve tüm 10TB veriyi sıfırdan çoğaltması gerekir. Bu süreç, serbest bant genişliğine bağlı olarak bir gün sürebilir ve bu süre zarfında söz konusu broker, diğer birçok broker'dan tarihsel veriler talep eder. Böyle bir arıza, birçok tarihsel okumayı artırır; eğer tüm bir erişilebilirlik bölgesi (availability zone) ciddi bir arıza yaşarsa, etki çok daha ciddi olabilir.
Veri miktarının sorun haline geldiği son durum, yeniden dengeleme senaryolarıdır. Kafka, herhangi bir partition'ın kopyalarını yeniden atamanıza izin verir ve bu, tüm verilerin taşınmasını içerir.
Örneğin, [0,1,2] broker'larından oluşan bir kopya setine sahip bir partition'ı ele alalım. Genellikle, ilk kopya liderdir; dolayısıyla broker 0 bu partition’ın lideridir. Yeni kopyalar eklemek isterseniz, bu kopyalar senkron olmayan kopya olarak başlar ve senkron bir kopya haline gelmeden önce lider 0'dan tüm partition verilerini okumak zorundadır.
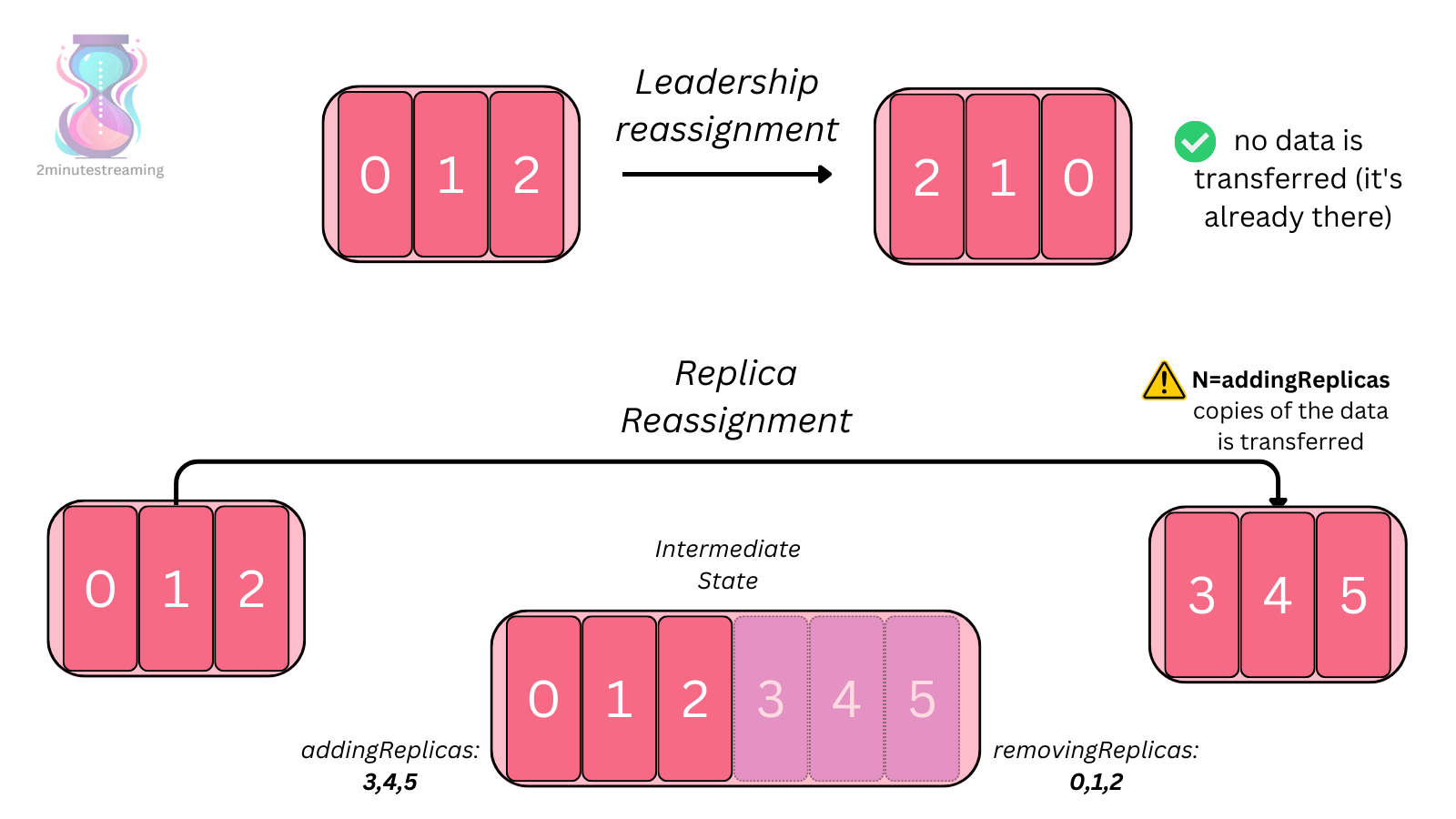
Kafka kümenize daha fazla düğüm (knot) eklediğinizde, örneğin bazı partition kopyalarını bu yeni broker'lara yeniden atamanız gerekir, aksi takdirde bu broker'lar boş kalır. Yeniden atama süreci, alıcı broker'ın verilen kopyalar için tüm veriyi kopyalamasını gerektirir. Bu, hem tarihsel doğası nedeniyle değerli IOPS'leri kullanabilir hem de çok uzun sürebilir.
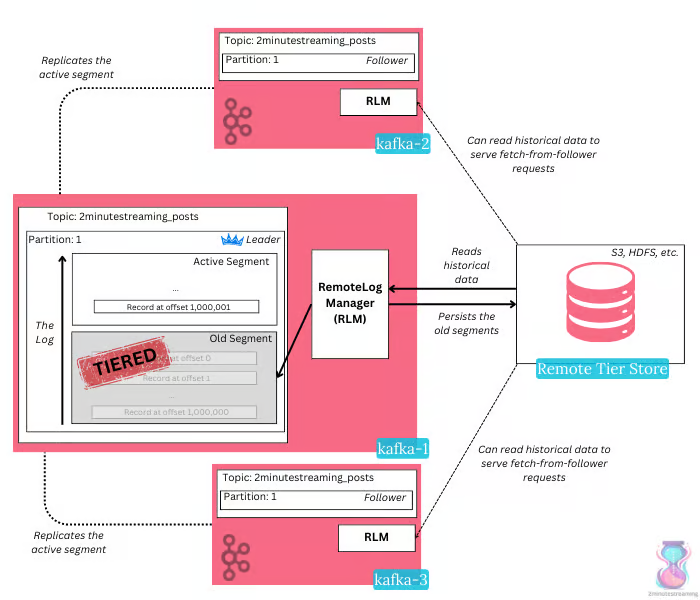
Apache Kafka, bu sorunları çözmek için Katmanlı Depolama (Tiered Storage) adlı bir özellik sunar - çoğu veriyi uzaktaki bir nesne deposunda (örneğin S3) saklama fikrini basitçe uygulayan bir yöntemdir. Henüz Erken Erişim aşamasında olmasına rağmen, Kafka artık iki depolama katmanına sahiptir - sıcak yerel depolama ve soğuk uzak depolama - her ikisi de sorunsuz bir şekilde soyutlanmıştır.
Bu yeni modda, lider broker'lar veriyi nesne deposuna katmanlandırmaktan sorumludur. Katmanlandıktan sonra, hem lider hem de takipçi broker'lar nesne deposundan tarihi verileri sunmak için okuyabilir.
Bu özellik, yukarıda bahsedilen tüm sorunları güzel bir şekilde çözer çünkü broker'lar artık büyük miktarda veriyi kopyalamak zorunda kalmaz ve geçmiş okumalar IOPS'leri tüketmez. Geliştirme testleri, tarihsel tüketiciler mevcut olduğunda üretici performansında %43'lük bir iyileşme gösterdi. Nesne deposuna bağlı olarak, replikasyon ve dayanıklılık garantilerini dış kaynak kullanarak sağladığınız için maliyet tasarrufu da sağlayabilir.
Yardımcı Sistemler (Auxiliary Systems)
Yeniden Dengeleme (Rebalancing)
Partition'ları yeniden atama, önemli bir kullanım gören herhangi bir Kafka kümesinde ana bir gerekliliktir.
Dağıtık bir sistem olarak, farklı istemci yükleriyle birlikte sistem, yaşam döngüsü boyunca sıcak noktalar veya verimsiz kaynak dağılımı geliştirebilir.
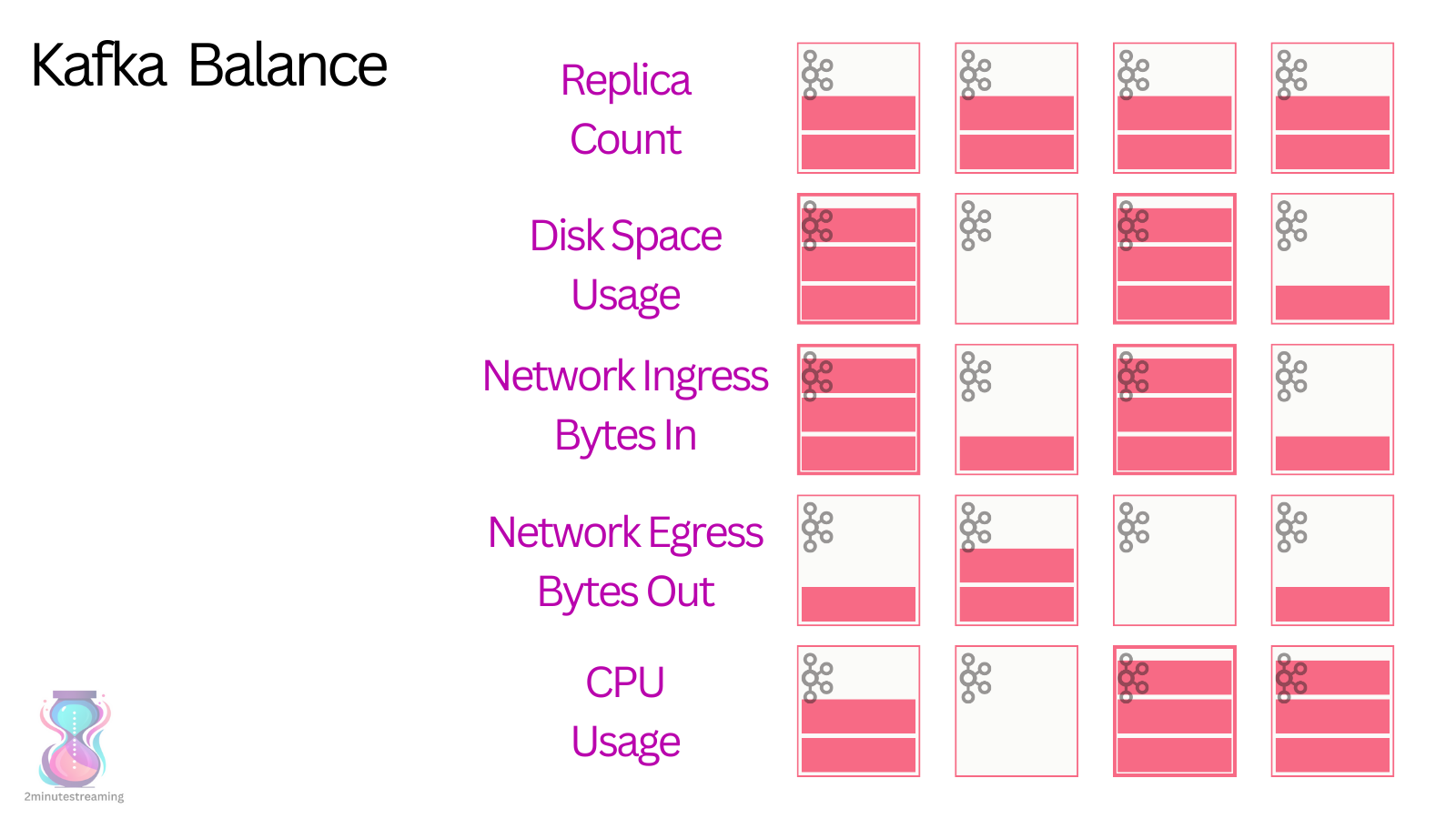
Bu sorunu hafifletmek (azaltmak) için Kafka, partition'ları yeniden atamanıza izin veren düşük seviyeli bir API sunar. İşlevselliği açığa çıkarmak kolaydır - asıl zor olan, neyi nereye taşıyacağını karar vermektir.
Temelde NP-zor Bin Packing problemi olan bu konu için topluluk birkaç araç geliştirmiştir ve hatta tam teşekküllü bir bileşen oluşturmuştur.
Cruise Control, başlangıçta LinkedIn’de de geliştirilmiş açık kaynaklı bir bileşendir. Tüm broker'ların metriklerini bir Kafka konusundan okuyarak, kümenin bellekte bir modelini oluşturur ve bu modeli, partition'ları yeniden atayarak optimize etmek için açgözlü bir heuristik bin-packing algoritması ile çalıştırır. Daha verimli bir model hesapladıktan sonra, düşük seviyeli Kafka yeniden atama API'sini kullanarak kümede kademeli olarak uygulamaya başlar.
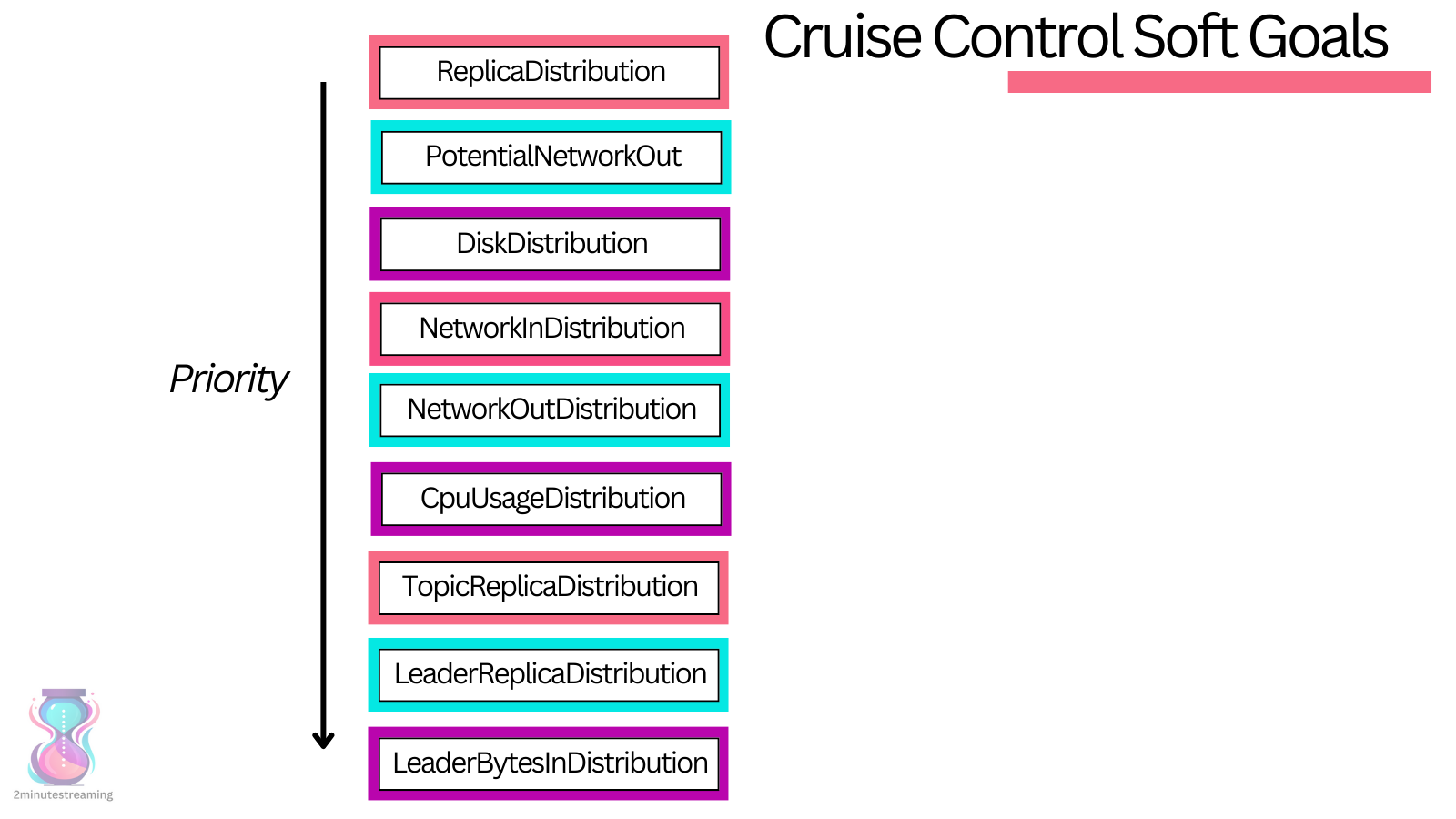
Detaylara fazla girmeden, Cruise Control, çeşitli `Goal`'lardan oluşan yapılandırılabilir bir yeniden dengeleme mantığı kümesi sunar. Her `Goal`, kendisine atanmış öncelik ile çalışır ve ilişkili kaynağı dengeler.
Cruise Control, kümenin metriklerini sürekli olarak izler ve metriklerin tanımlı kabul edilebilir eşiklerin dışına çıkmasını fark ettiğinde otomatik olarak yeniden dengeleme başlatır.
Önemli bir özellik olarak, Cruise Control, bir kümeye broker eklemek veya bir kümeden broker çıkarmak için API'ler de sunar. Kafka broker'ları durum bilgisi taşır (Tiered Storage ile bile), bu nedenle her iki işlem de bir operatörün kopyaları hareket ettirmesini gerektirir.
Kafka Connect
Eğer Kafka, olay güdümlü mimarinizin merkezi olacaksa, muhtemelen:
- Kafka'ya veri almak istediğiniz birçok sistem (kaynaklar) olacaktır.
- Kafka'dan veri almak istediğiniz birçok sistem (sink'ler) olacaktır.
Bu sistemlerin çoğunun popüler ve geniş çapta benimsenmiş sistemler olması olasıdır - ElasticSearch, Snowflake, PostgreSQL, BigQuery, MySQL gibi.
Apache açık kaynak projesinin bir parçası olan Kafka Connect, Kafka'yı diğer sistemlerle, topluluk tarafından yeniden kullanılabilir bir şekilde, tak-çalıştır (plug-and-play) bir biçimde entegre etmenizi sağlayan genel bir çerçevedir.
Kafka Connect çalışma zamanı iki modda dağıtılabilir:
- Standalone Mode — genellikle geliştirme, test veya küçük ölçekli veri yükleme için kullanılan tek bir düğüm.
- Distributed Mode — verileri alma yükünü paylaşmak için birlikte çalışan bir düğüm kümesi.
Connect içindeki her düğüm Connect Worker olarak adlandırılır. Bir worker, temelde eklenti kodunu çalıştıran bir konteynerdir.
Topluluk üyeleri, hata toleransı, tam olarak bir kez işleme, sıralama ve sıfırdan geliştirmek zor ve zaman alıcı olan diğer invariants'ı garanti eden savaş testli eklentiler geliştirir. Bu tür bir eklentinin adı Connectordır. Kafka konularına veri import etmek veya diğer dış sistemlere veri dışa aktarmak için bir Connect Worker üzerinde dağıtılan kullanıma hazır bir kütüphanedir.
Worker'lar, yapılandırmalarını, durumlarını ve ilerlemelerini (offset'leri) saklamak için iç Kafka konularını yoğun bir şekilde kullanır. Ayrıca, worker hatalarını yönetmek ve görev atamalarını yaymak için Kafka'nın mevcut Consumer Group protokolünü kullanırlar.
Kullanıcılar, worker'lara eklentileri kurar ve REST API'sini kullanarak yapılandırır/yönetirler. Bu tür bir eklenti, Connector olarak adlandırılır ve Kafka (bir Kafka konusu) ile bir dış sistem arasında bağlantı kurmak için kolayca dağıtılabilir ve yapılandırılabilir.
Connector kodu, veri alışverişinin tüm karmaşık ayrıntılarını yönetir, böylece kullanıcılar basit yapılandırma ve entegrasyona odaklanabilirler. Kod, verileri paralel olarak taşımak için her worker için görevler oluşturur. Bu Connectors iki çeşitte gelir:
- Source Connector — başka bir sistemden source (kaynak) veri alıp Kafka'ya yazmak için kullanılır.
- Sink Connector— Kafka'dan veri alıp başka bir sisteme (sink) yazmak için kullanılır.

Yukarıdaki diyagram da (şemada), her biri kendi worker'larına sahip iki ayrı Connect kümesinde çalışan iki Source connector'ü görmekteyiz. Bu connector'ler, MongoDB/PostgreSQL verilerini Kafka'ya alır.
Başka bir Connect kümesi ise Sink connector'leri çalıştırarak, Kafka'dan aldığı verileri Snowflake'e aktarır.
Kafka Streams
Bir akış işlemcisi genellikle, sürekli veri akışlarını giriş konularından okuyarak bu veriler üzerinde işlem yapar ve işlenmiş verileri çıkış konularına (veya dış hizmetlere, veritabanlarına vb.) üretir. Kafka'da basit işlemleri doğrudan normal üretici/tüketici API'leri ile yapmak mümkündür; ancak, daha karmaşık dönüşümler, örneğin akışları birleştirme gibi işlemler için Kafka, entegre bir Streams API kütüphanesi sunar.
Apache açık kaynak projesinin bir parçası olan Kafka Streams, verileri gerçek zamanlı olarak işlemek, dönüştürmek ve zenginleştirmek için yüksek seviyeli bir API sunan bir istemci kütüphanesidir.
Bu API, kendi kod tabanınız içinde kullanılmak üzere tasarlanmıştır. Broker üzerinde çalışmaz. Diğer akış işleme çerçevelerinin aksine, Kafka Streams Kafka'ya özgüdür ve bu nedenle ayrı bir karmaşık dağıtım stratejisi gerektirmez - genellikle uygulamanız içinde bir Kafka istemcisi olarak dağıtılır.
Tüketici API'sine benzer şekilde çalışır ve akış işleme işini birden çok uygulama arasında ölçeklendirmenize yardımcı olur (tüketici grupları gibi).
Özellikle, giriş ve çıkışın bir Kafka konusu olduğu durumlarda tam olarak bir kez işleme semantiğini destekler.
Optimizasyonlar / Gelecek Çalışmalar
Kafka, ilk kez 2011'de piyasaya sürülmüş olsa da, topluluk protokol üzerinde aktif bir şekilde yenilik yapmaktadır. Gelecekte, herkesin Kafka API'si üzerinde standartlaşacağı ve rekabetin altındaki uygulama üzerinde olacağı yönünde işaretler bulunmaktadır.
Bu alandaki mevcut lider, Kafka'nın orijinal yaratıcıları tarafından kurulan Confluent'tır. Confluent, Kora adında bulut-native bir Kafka motoru geliştirmiştir.
Dikkate değer rakipler arasında, Kafka'yı C++ dilinde yeniden yazan RedPanda ve S3'ü yoğun bir şekilde kullanarak replikasyonu ve broker durumunu tamamen ortadan kaldıran yeni bir mimari ile yenilik yapan WarpStream bulunmaktadır.
Satıcılar günümüzde büyük ölçüde bulutta rekabet etmektedir. Birçok firma, çeşitli destek seviyeleri sunan bir Kafka SaaS'ı sunmaktadır. Bazı satıcılar, sistemin birçok detayını soyutlayarak tam anlamıyla serverless bir SaaS deneyimi sunarken, diğerleri kullanıcıların sistemin detaylarını anlamasını ve bazı durumlarda büyük bir kısmını kendilerinin yönetmesini gerektirmektedir.
Özetle, Kafka, zengin bir özellik seti sunan olgun ve yaygın olarak benimsenmiş bir yazılımdır. Açık kaynaklıdır ve 13 yıl süren geliştirme sürecinin ardından daha güçlü bir şekilde yenilik yapmaya devam eden çok sağlıklı bir topluluğa sahiptir.

Çevirmen (CyberRulz06) notu: Üzerine uzun süre çalıştığım bu çeviriyi sonunda yayınlama şansını buluyorum. Büyük bir konu olduğundan dolayı hem Türkçe hem de İngilizce hatalar yapmış olabilirim. Fark ederseniz, konu altında veya özelden iletişime geçebilirisiniz.
CyberRulz06 tarafından çevirilmiştir. Asıl makalede bulunan bâzı uzun detayları traşlayıp asıl çözümleri öne taşımaya çalıştım. Anlam bütünlüğü korunması için bazı kelimeler Türkçe de farklı çevirilmiştir ve orijinal görseller kullanılmıştır. İyi okumalar ve iyi forumlar
Kozlovski, S. (2024, May 9) Kafka 101. Kafka 101

2011 yılında LinkedIn'de geliştirilen Apache Kafka, en popüler açık kaynak Apache projelerinden biri olarak öne çıkmaktadır. Şu ana kadar toplamda 24 önemli sürüm yayınlanmış olup, en dikkat çekici olanı, her bir sürümde kod tabanının ortalama %24 oranında büyümesidir.
Kafka, internetin gerçek zamanlı veri akışı için fiili standardı olarak hizmet veren dağıtık bir akış platformudur.
Gelişimi, LinkedIn'in o dönemde karşılaştığı sorunlara bağlı olarak şekillenmiştir. Büyük ölçekli dağıtımlı sistemlerle (distributed systems ) ilgili sorunları yaşayan ilk şirketlerden biri olarak, kontrolsüz mikro hizmet çoğalması sorununu fark ettiler.
Hizmetler arası ve kalıcı depolama yapılandırmalarının artan karmaşıklığını çözmek için, doğruluk kaynağı olarak hizmet edebilecek tek bir platform geliştirmeye karar verdiler.
Apache Kafka, hizmet koordinasyonu sorununu çözmek amacıyla tasarlanmış bir dağıtım sistemidir. Vizyonu, bir şirketin içinde merkezi bir sinir sistemi olarak kullanılmasıdır. Verilerin aktığı, işlendiği/dönüştürüldüğü ve diğer alt sistemler (veri depoları, dizinler, mikro hizmetler (microservices) vb.) tarafından tüketildiği bir yer olarak tasarlanmıştır.
Bu nedenle, yüksek veri akışını (saniyede milyonlarca mesaj) karşılayacak şekilde optimize edilmiştir ve çok miktarda veriyi (terabaytlarca) depolayabilme kapasitesine sahiptir.
Log (Kayıt Defteri)
Sistemdeki veriler, konular (topics) olarak adlandırılan kategorilerde saklanır. Bir konunun temel yapı taşı ise log (kayıt defteri) olarak bilinen, kayıtları sıralı bir şekilde depolayan basit bir veri yapısıdır.
Log, değişmez (immutable) bir yapıdır ve O(1) yazma ve okuma sürelerine sahiptir (bu işlemler log’un sonundan veya başından yapılırsa). Bu nedenle, log’un büyüklüğü arttıkça veriye erişim hızı bozulmaz ve değişmezliği sayesinde eşzamanlı okumalarda verimli bi hâl alır.
Ancak bu avantajlara rağmen, log’un önemli yararı ve belki de Kafka için seçilme nedeninin başlıca nedeni, HDD’ler (sabit diskler) için optimize edilmiş olmasıdır.
HDD’ler, doğrusal okuma ve yazma işlemlerinde oldukça verimlidir ve log’un yapısı nedeniyle, doğrusal okuma/yazma işlemleri log üzerinde yapılan temel işlemlerdir.
Performans
İyi optimize edilmiş bir yerel Kafka dağıtımı genellikle ağ üzerinde darboğaza uğrar, yani okuma ve yazma verimliliği saniyede birçok gigabayta kadar ölçeklenebilir.
Bu tür bir performansa nasıl ulaşılır? Birden fazla optimizasyon bulunmaktadır. Bazıları makro düzeyde, diğerleri ise mikro düzeydedir.
Disk Üzerinde Kalıcılık
Kafka, tüm kayıtlarını diskte saklar ve hiçbir şeyi açıkça bellek içinde tutmaz.
Kafka’nın protokolü, mesajları gruplar. Bu, ağ isteklerinin mesajları bir araya getirmesine ve ağ yükünü azaltmasına olanak tanır.
Sunucu ise, mesajları bir seferde büyük parçalar halinde saklar. Bu da, doğrusal bir HDD yazma işlemidir. Tüketiciler(kullanıcılar) de büyük doğrusal parçaları bir kerede alır.
Disk üzerinde doğrusal okuma/yazma işlemleri hızlı olabilir. HDD’ler genellikle yavaş olarak değerlendirilir çünkü birçok disk arama işlemi yapıldığında, diskin kafa hareketlerinin fiziksel sınırları nedeniyle darboğaza uğranır. Ancak, doğrusal okuma/yazma işlemlerinde bu sorun yaşanmaz,
Önceden Okuma Optimizasyonları büyük blokları talep edilmeden önce önceden okur ve bellek içinde saklar, bu da bir sonraki okumanın diske dokunmadan gerçekleştirilmesini sağlar.
Arka Plan Yazma Optimizasyonları küçük mantıksal yazmaları büyük fiziksel yazmalarda toplar. Kafka fsync kullanmaz, yazmalar diske asenkron olarak yazılır.
Pagecache
Modern işletim sistemleri diski serbest RAM'de önbelleğe alır. Buna pagecache (sayfa önbelleği) denir.
Kafka, mesajları üreticiden (producer) > aracıya (broker) > tüketiciye (consumer) kadar standart bir ikili formatta değiştirmeden sakladığı için, sıfır-kopya (zero-copy) optimizasyonundan faydalanabilir.
Sıfır-kopya, biraz yanıltıcı bir adlandırmadır; burada işletim sistemi veriyi doğrudan pagecache'den bir sokete (socket) kopyalar, böylece Kafka'nın JVM'ini tamamen geçer. Verilerin hala kopyaları yapılır, ancak bu kopyalar azaltılır. Bu, birkaç ekstra kopyayı ve kullanıcı ile çekirdek modu geçişlerini (user <-> kernel mode) azaltır.
Bu kulağa hoş gelse de, sıfır-kopya (zero-copy) optimizasyonunun Kafka'yı büyük ölçüde optimize ettiği pek olası değildir; bunun iki ana nedeni vardır. İlk olarak, iyi optimize edilmiş Kafka dağıtımlarında CPU nadiren darboğaz oluşturur, bu nedenle bellek içindeki kopyaların eksikliği size fazla kaynak kazandırmaz.
İkincisi, şifreleme ve SSL/TLS (tüm üretim dağıtımları için zorunlu) mesajı yol boyunca değiştirdiğinden, Kafka'nın sıfır-kopya kullanmasını engeller. Buna rağmen, Kafka hala yüksek performans sergiler.
Temel Bilgiler
Dağıtılmış sistemdeki (distributed systems) düğümler broker olarak adlandırılır. Her konu (topic), parçalara (partitions) bölünür ve bu parçalar, dayanıklılık ve erişilebilirlik amacıyla N kez (çoğaltma faktörüne göre) kopyalanır.
Basit bir benzetme ile, bir işletim sistemindeki temel depolama birimi bir dosyaysa, Kafka'daki temel depolama birimi bir kopyadır (partition'ın bir kopyası).
Her kopya, log veri yapısını barındıran ve sıralı bir şekilde daha büyük bir log oluşturan birkaç dosyadan ibarettir. Log'daki her kayıt, belirli bir offset ile belirtilir; bu, sadece monotonik olarak artan bir numaradır.
Çoğaltma, lider bazlıdır; yani, her seferinde yalnızca bir broker, belirli bir partition'ın lideri olur.
Her partition'ın bir kopya kümesi (replica set) vardır. Bir kopya iki durumda olabilir: senkron (in-sync) veya senkron olmayan (out-of-sync). İsimlerinden de anlaşılacağı gibi, senkron olmayan kopyalar, partition için en güncel veriye sahip olmayan kopyalardır.
Yazma İşlemleri
Yazma işlemleri, yalnızca lider broker'a yapılabilir, ardından lider veri N-1 takipçiye (follower) asenkron olarak kopyalar. Verileri yazan istemcilere üreticiler(producers) denir. Üreticiler, yazma işlemleri sırasında almak istedikleri dayanıklılık garantilerini “acks”özelliği aracılığıyla yapılandırabilir. Bu özellik, bir yazma işlemi tamamlandıktan sonra yanıtın istemciye dönebilmesi için kaç broker'ın onay vermesi gerektiğini belirtir:
- acks=0 - Üretici, broker'dan yanıt beklemeden yazmayı hemen başarılı olarak kabul eder.
- acks=1 - Lider broker kaydı onayladığında (diske kaydettiğinde) üreticiye bir yanıt gönderilir.
- acks=all (varsayılan) - Tüm senkron kopyalar kaydı kalıcı hale getirdiğinde üreticiye bir yanıt gönderilir.
acks=all özelliğini daha da kontrol etmek ve yalnızca bir senkron kopya olduğunda acks=1 özelliğine geri dönmesini engellemek için, `min.insync.replicas` ayarı, acks=all ile yapılandırılmış bir yazmanın onaylanması için gereken minimum senkron kopya sayısını belirtir.
Okuma İşlemleri
Verileri okuyan istemcilere tüketiciler(consumers) denir. Benzer şekilde, bu istemci uygulamaları Kafka kütüphanesini kullanarak verileri okur ve üzerinde işlem yapar.
Kafka tüketicileri, herhangi bir kopyadan okuma yapabilme yeteneğine sahiptir ve genellikle ağ topolojisindeki en yakın kopyadan okumak üzere yapılandırılır.
Tüketiciler, tüketici grupları (consumer groups) oluşturur; bunlar, mantıksal olarak gruplanmış ve senkronize edilmiş tüketicilerden oluşan topluluklardır. Birbirleriyle doğrudan bağlantılı olmadan, broker ile iletişim kurarak senkronize olurlar. İlerlemelerini (hangi ofsete kadar tükettiklerini) özel bir Kafka konusunun (`__consumer_offsets`) belirli bir partition'ında saklarlar. Partition'ın lideri olan broker, bu tüketici grubunun **Grup Koordinatörü** (Group Coordinator) olarak görev yapar ve bu Koordinatör, tüketici grubunun üyeliğini ve canlılığını sürdürmekten sorumludur.
Her partition'daki kayıtlar, içinde sıralıdır. Tüketiciler, bu kayıtları doğru sırayla okumayı garanti eder. Sıralamanın korunmasını sağlamak için, tüketici grubu protokolü, aynı tüketici grubundaki iki tüketicinin aynı partition'dan okumasını engeller.
Aynı konu (topic) üzerinde birçok farklı tüketici grubu olabilir.
Kafka'nın geleneksel mesajlaşma teknolojilerine göre üstün olmasının temel nedenlerinden biri, üretici ve tüketici istemcilerinin bu şekilde ayrıştırılmasıdır. Bazı sistemlerde mesajlar tüketildiği anda silinir ve bu durum sıkı bir bağlılık yaratır. Tüketiciler yavaşsa, sistem bellek tükenme riskiyle karşılaşabilir ve üreticileri etkileyebilir. Kafka bu sorundan muzdarip değildir çünkü verileri diskte kalıcı olarak saklar ve yukarıda belirtilen optimizasyonlar sayesinde performansını korur.
Protokol
İstemciler, Kafka protokolünü kullanarak broker'lara TCP üzerinden bağlanır. Üretici ve tüketici istemcileri, Kafka protokolünü uygulayan basit Java kütüphaneleridir. Diğer neredeyse tüm dillerde de uygulamaları mevcuttur.
Hata Toleransı
Bir Apache Kafka kümesi her zaman aktif bir Denetleyici (Controller) olan bir broker içerir. Denetleyici, tek bir doğruluk kaynağı gerektiren tüm idari işlemleri destekler; örneğin konuları oluşturma ve silme, konulara partition ekleme, partition kopyalarını yeniden atama gibi işlemleri gerçekleştirir.
En etkili sorumluluğu, her partition'ın liderlik seçimini yönetmektir. Küme hakkındaki merkezi metadata'nın tamamı Denetleyici tarafından işlendiği için, partition'ın liderliğinin kime geçeceğine ve ne zaman geçeceğine karar verir. Bu, bir lider broker’ın arızalanması veya kapanması durumunda özellikle belirgindir. Bu durumlarda, Denetleyici, partition liderliğini replica setindeki diğer bir brokera düzgün bir şekilde devreder.
Konsensüs (Consencus)
Her dağıtık sistem (disturbed system), konsensüs gerektirir. Belirli bir zamanda tam olarak bir broker’ı denetleyici olarak seçmek, temelde bir dağıtık konsensüs problemidir.
Kafka tarihsel olarak konsensüsü ZooKeeper’e devretmiştir. Küme başlatılırken, her broker `/controller` zNode’unu kaydetmek için yarışır ve bunu ilk başaran broker denetleyici olarak ilan edilirdi. Benzer şekilde, mevcut Denetleyici öldüğünde, zNode’u ilk kaydeden broker yeni denetleyici olurdu.
Kafka, ZooKeeper’de tüm türde metadata’yı, canlı broker seti, konu adları ve partition sayıları, partition atamaları gibi bilgileri saklardı. Ayrıca, ZooKeeper’in watch mekanizmasını yoğun bir şekilde kullanarak, belirli bir zNode değiştiğinde bir aboneye bildirim gönderilirdi.
Son birkaç yıldır, Kafka ZooKeeper’den kendi konsensüs mekanizması olan KRaft (“Kafka Raft”)’e geçiş yapmaktadır. KRaft, Raft’ın bir lehçesidir ve Kafka’nın mevcut çoğaltma protokolünden yoğun şekilde etkilenmiştir. Temelde, Kafka çoğaltma protokolünü bazı Raft ile ilgili özelliklerle genişletir.
Önemli bir farkındalık, kümenin metadata’sının, kümede meydana gelen olayların sıralı kayıtları aracılığıyla düzenli bir log’da kolayca ifade edilebileceğidir. Broker’lar bu olayları yeniden oynatarak sistemin en son durumunu oluşturabilirler.
Bu yeni modelde, Kafka’nın N denetleyicili bir quorum’u (genellikle 3) vardır. Bu broker’lar, metadata konusu (“__cluster_metadata”) adında özel bir konu barındırır.
Bu konunun liderlik seçimi Raft tarafından yönetilir (diğer tüm konular için Denetleyici tarafından değil). Konunun lideri, mevcut aktif Denetleyici olur. Diğer denetleyiciler ise, en son metadata’yı bellek içinde saklayan sıcak yedekler olarak görev yapar.
Tüm düzenli broker'lar bu konuyu da çoğaltır. Denetleyici ile doğrudan iletişim kurmak yerine, konunun en son kayıtlarını takip ederek metadata’larını asenkron bir şekilde güncellerler.
KRaft, iki dağıtım modunu destekler: birleşik ve izole mod. Birleşik mod, ZooKeeper altında kullanılan modele benzer; burada bir broker, hem düzenli broker hem de denetleyici rolünü aynı anda üstlenebilir. İzole modda ise, denetleyiciler yalnızca denetleyici olarak dağıtılır ve başka bir işlevi yoktur.
Üretime hazır bir KRaft sürümünü içeren ilk Kafka sürümü, Ekim 2022'de çıkan Kafka 3.3'tür. ZooKeeper’in tamamen kaldırılması beklenen bir sonraki büyük Kafka sürümü olan 4.0’da (yaklaşık olarak 2024’ün üçüncü çeyreğinde) gerçekleşecektir.
Katmanlı Depolama ( Tiered Storage)
Daha önce belirtildiği gibi, Kafka'nın mimarisi maliyet etkin bir yerel dağıtım için optimize edilmiştir. Ancak, bulutun yaygınlaşması yazılım mimarilerini büyük ölçüde değiştirmiştir.
Kafka'nın büyümesiyle birlikte dikkat çeken mimari sorunlardan biri, depolamanın broker ile aynı yerde konumlandırılması kararının getirdiği zorluklardır. Broker'lar, tüm verileri yerel disklerinde barındırır, bu da ölçeklendirme ile birlikte birkaç zorluk yaratır.
İlk olarak, Kafka bir şirketin mimarisinin merkezi sinir sistemi olarak tasarlandığından, broker'ların üzerinde 3TB tarihsel veri saklaması istenebilir. Bu durumda, varsayılan çoğaltma faktörü olan 3 ile toplam 9TB veri elde edilir.
Bir broker yerel olarak 10TB'ye yakın veri barındırdığında, sorunlar baş göstermeye başlar.
Bir açık sorun, düzgün kapanmayan sistemlerin yönetilmesidir. Bir broker düzgün kapanmayan bir sistemden geri döndüğünde, tüm yerel log indeks dosyalarını yeniden oluşturması gerekir; bu süreç "log recovery" olarak adlandırılır. 10TB'lık bir disk ile bu, bazı durumlarda saatler hatta günler sürebilir.
Bir diğer sorun ise tarihsel okumalar ile ilgilidir. Kafka'nın performansı, tüketicilerin log'un sonundan okudukları varsayımına dayanır; bu pratikte, en son üretilmiş verilerin yer aldığı pagecache'den okumak anlamına gelir. Bir tüketici tarihsel veriler aldığında, bu genellikle Kafka broker'ının veriyi HDD'den okumasını gerektirir. HDD'ler tarihsel olarak 120 IOPS'ta kalmıştır; yani bu kaynağın tükenmesi oldukça kolaydır. Bu, tüketicilerin IOPS için üreticilerle rekabet ettiği ve bu kaynak tükendiğinde performansın düştüğü anlamına gelir.
IOPS problemi, ciddi arıza senaryolarında daha da kötüleşir. Bir broker’ın diski ciddi bir arıza yaşadığında, boş bir diskle başlar ve tüm 10TB veriyi sıfırdan çoğaltması gerekir. Bu süreç, serbest bant genişliğine bağlı olarak bir gün sürebilir ve bu süre zarfında söz konusu broker, diğer birçok broker'dan tarihsel veriler talep eder. Böyle bir arıza, birçok tarihsel okumayı artırır; eğer tüm bir erişilebilirlik bölgesi (availability zone) ciddi bir arıza yaşarsa, etki çok daha ciddi olabilir.
Veri miktarının sorun haline geldiği son durum, yeniden dengeleme senaryolarıdır. Kafka, herhangi bir partition'ın kopyalarını yeniden atamanıza izin verir ve bu, tüm verilerin taşınmasını içerir.
Örneğin, [0,1,2] broker'larından oluşan bir kopya setine sahip bir partition'ı ele alalım. Genellikle, ilk kopya liderdir; dolayısıyla broker 0 bu partition’ın lideridir. Yeni kopyalar eklemek isterseniz, bu kopyalar senkron olmayan kopya olarak başlar ve senkron bir kopya haline gelmeden önce lider 0'dan tüm partition verilerini okumak zorundadır.
Kafka kümenize daha fazla düğüm (knot) eklediğinizde, örneğin bazı partition kopyalarını bu yeni broker'lara yeniden atamanız gerekir, aksi takdirde bu broker'lar boş kalır. Yeniden atama süreci, alıcı broker'ın verilen kopyalar için tüm veriyi kopyalamasını gerektirir. Bu, hem tarihsel doğası nedeniyle değerli IOPS'leri kullanabilir hem de çok uzun sürebilir.
Apache Kafka, bu sorunları çözmek için Katmanlı Depolama (Tiered Storage) adlı bir özellik sunar - çoğu veriyi uzaktaki bir nesne deposunda (örneğin S3) saklama fikrini basitçe uygulayan bir yöntemdir. Henüz Erken Erişim aşamasında olmasına rağmen, Kafka artık iki depolama katmanına sahiptir - sıcak yerel depolama ve soğuk uzak depolama - her ikisi de sorunsuz bir şekilde soyutlanmıştır.
Bu yeni modda, lider broker'lar veriyi nesne deposuna katmanlandırmaktan sorumludur. Katmanlandıktan sonra, hem lider hem de takipçi broker'lar nesne deposundan tarihi verileri sunmak için okuyabilir.
Bu özellik, yukarıda bahsedilen tüm sorunları güzel bir şekilde çözer çünkü broker'lar artık büyük miktarda veriyi kopyalamak zorunda kalmaz ve geçmiş okumalar IOPS'leri tüketmez. Geliştirme testleri, tarihsel tüketiciler mevcut olduğunda üretici performansında %43'lük bir iyileşme gösterdi. Nesne deposuna bağlı olarak, replikasyon ve dayanıklılık garantilerini dış kaynak kullanarak sağladığınız için maliyet tasarrufu da sağlayabilir.
Yardımcı Sistemler (Auxiliary Systems)
Yeniden Dengeleme (Rebalancing)
Partition'ları yeniden atama, önemli bir kullanım gören herhangi bir Kafka kümesinde ana bir gerekliliktir.
Dağıtık bir sistem olarak, farklı istemci yükleriyle birlikte sistem, yaşam döngüsü boyunca sıcak noktalar veya verimsiz kaynak dağılımı geliştirebilir.
Bu sorunu hafifletmek (azaltmak) için Kafka, partition'ları yeniden atamanıza izin veren düşük seviyeli bir API sunar. İşlevselliği açığa çıkarmak kolaydır - asıl zor olan, neyi nereye taşıyacağını karar vermektir.
Temelde NP-zor Bin Packing problemi olan bu konu için topluluk birkaç araç geliştirmiştir ve hatta tam teşekküllü bir bileşen oluşturmuştur.
Cruise Control, başlangıçta LinkedIn’de de geliştirilmiş açık kaynaklı bir bileşendir. Tüm broker'ların metriklerini bir Kafka konusundan okuyarak, kümenin bellekte bir modelini oluşturur ve bu modeli, partition'ları yeniden atayarak optimize etmek için açgözlü bir heuristik bin-packing algoritması ile çalıştırır. Daha verimli bir model hesapladıktan sonra, düşük seviyeli Kafka yeniden atama API'sini kullanarak kümede kademeli olarak uygulamaya başlar.
Detaylara fazla girmeden, Cruise Control, çeşitli `Goal`'lardan oluşan yapılandırılabilir bir yeniden dengeleme mantığı kümesi sunar. Her `Goal`, kendisine atanmış öncelik ile çalışır ve ilişkili kaynağı dengeler.
Cruise Control, kümenin metriklerini sürekli olarak izler ve metriklerin tanımlı kabul edilebilir eşiklerin dışına çıkmasını fark ettiğinde otomatik olarak yeniden dengeleme başlatır.
Önemli bir özellik olarak, Cruise Control, bir kümeye broker eklemek veya bir kümeden broker çıkarmak için API'ler de sunar. Kafka broker'ları durum bilgisi taşır (Tiered Storage ile bile), bu nedenle her iki işlem de bir operatörün kopyaları hareket ettirmesini gerektirir.
Kafka Connect
Eğer Kafka, olay güdümlü mimarinizin merkezi olacaksa, muhtemelen:
- Kafka'ya veri almak istediğiniz birçok sistem (kaynaklar) olacaktır.
- Kafka'dan veri almak istediğiniz birçok sistem (sink'ler) olacaktır.
Bu sistemlerin çoğunun popüler ve geniş çapta benimsenmiş sistemler olması olasıdır - ElasticSearch, Snowflake, PostgreSQL, BigQuery, MySQL gibi.
Apache açık kaynak projesinin bir parçası olan Kafka Connect, Kafka'yı diğer sistemlerle, topluluk tarafından yeniden kullanılabilir bir şekilde, tak-çalıştır (plug-and-play) bir biçimde entegre etmenizi sağlayan genel bir çerçevedir.
Kafka Connect çalışma zamanı iki modda dağıtılabilir:
- Standalone Mode — genellikle geliştirme, test veya küçük ölçekli veri yükleme için kullanılan tek bir düğüm.
- Distributed Mode — verileri alma yükünü paylaşmak için birlikte çalışan bir düğüm kümesi.
Connect içindeki her düğüm Connect Worker olarak adlandırılır. Bir worker, temelde eklenti kodunu çalıştıran bir konteynerdir.
Topluluk üyeleri, hata toleransı, tam olarak bir kez işleme, sıralama ve sıfırdan geliştirmek zor ve zaman alıcı olan diğer invariants'ı garanti eden savaş testli eklentiler geliştirir. Bu tür bir eklentinin adı Connectordır. Kafka konularına veri import etmek veya diğer dış sistemlere veri dışa aktarmak için bir Connect Worker üzerinde dağıtılan kullanıma hazır bir kütüphanedir.
Worker'lar, yapılandırmalarını, durumlarını ve ilerlemelerini (offset'leri) saklamak için iç Kafka konularını yoğun bir şekilde kullanır. Ayrıca, worker hatalarını yönetmek ve görev atamalarını yaymak için Kafka'nın mevcut Consumer Group protokolünü kullanırlar.
Kullanıcılar, worker'lara eklentileri kurar ve REST API'sini kullanarak yapılandırır/yönetirler. Bu tür bir eklenti, Connector olarak adlandırılır ve Kafka (bir Kafka konusu) ile bir dış sistem arasında bağlantı kurmak için kolayca dağıtılabilir ve yapılandırılabilir.
Connector kodu, veri alışverişinin tüm karmaşık ayrıntılarını yönetir, böylece kullanıcılar basit yapılandırma ve entegrasyona odaklanabilirler. Kod, verileri paralel olarak taşımak için her worker için görevler oluşturur. Bu Connectors iki çeşitte gelir:
- Source Connector — başka bir sistemden source (kaynak) veri alıp Kafka'ya yazmak için kullanılır.
- Sink Connector— Kafka'dan veri alıp başka bir sisteme (sink) yazmak için kullanılır.
Yukarıdaki diyagram da (şemada), her biri kendi worker'larına sahip iki ayrı Connect kümesinde çalışan iki Source connector'ü görmekteyiz. Bu connector'ler, MongoDB/PostgreSQL verilerini Kafka'ya alır.
Başka bir Connect kümesi ise Sink connector'leri çalıştırarak, Kafka'dan aldığı verileri Snowflake'e aktarır.
Kafka Streams
Bir akış işlemcisi genellikle, sürekli veri akışlarını giriş konularından okuyarak bu veriler üzerinde işlem yapar ve işlenmiş verileri çıkış konularına (veya dış hizmetlere, veritabanlarına vb.) üretir. Kafka'da basit işlemleri doğrudan normal üretici/tüketici API'leri ile yapmak mümkündür; ancak, daha karmaşık dönüşümler, örneğin akışları birleştirme gibi işlemler için Kafka, entegre bir Streams API kütüphanesi sunar.
Apache açık kaynak projesinin bir parçası olan Kafka Streams, verileri gerçek zamanlı olarak işlemek, dönüştürmek ve zenginleştirmek için yüksek seviyeli bir API sunan bir istemci kütüphanesidir.
Bu API, kendi kod tabanınız içinde kullanılmak üzere tasarlanmıştır. Broker üzerinde çalışmaz. Diğer akış işleme çerçevelerinin aksine, Kafka Streams Kafka'ya özgüdür ve bu nedenle ayrı bir karmaşık dağıtım stratejisi gerektirmez - genellikle uygulamanız içinde bir Kafka istemcisi olarak dağıtılır.
Tüketici API'sine benzer şekilde çalışır ve akış işleme işini birden çok uygulama arasında ölçeklendirmenize yardımcı olur (tüketici grupları gibi).
Özellikle, giriş ve çıkışın bir Kafka konusu olduğu durumlarda tam olarak bir kez işleme semantiğini destekler.
Optimizasyonlar / Gelecek Çalışmalar
Kafka, ilk kez 2011'de piyasaya sürülmüş olsa da, topluluk protokol üzerinde aktif bir şekilde yenilik yapmaktadır. Gelecekte, herkesin Kafka API'si üzerinde standartlaşacağı ve rekabetin altındaki uygulama üzerinde olacağı yönünde işaretler bulunmaktadır.
Bu alandaki mevcut lider, Kafka'nın orijinal yaratıcıları tarafından kurulan Confluent'tır. Confluent, Kora adında bulut-native bir Kafka motoru geliştirmiştir.
Dikkate değer rakipler arasında, Kafka'yı C++ dilinde yeniden yazan RedPanda ve S3'ü yoğun bir şekilde kullanarak replikasyonu ve broker durumunu tamamen ortadan kaldıran yeni bir mimari ile yenilik yapan WarpStream bulunmaktadır.
Satıcılar günümüzde büyük ölçüde bulutta rekabet etmektedir. Birçok firma, çeşitli destek seviyeleri sunan bir Kafka SaaS'ı sunmaktadır. Bazı satıcılar, sistemin birçok detayını soyutlayarak tam anlamıyla serverless bir SaaS deneyimi sunarken, diğerleri kullanıcıların sistemin detaylarını anlamasını ve bazı durumlarda büyük bir kısmını kendilerinin yönetmesini gerektirmektedir.
Özetle, Kafka, zengin bir özellik seti sunan olgun ve yaygın olarak benimsenmiş bir yazılımdır. Açık kaynaklıdır ve 13 yıl süren geliştirme sürecinin ardından daha güçlü bir şekilde yenilik yapmaya devam eden çok sağlıklı bir topluluğa sahiptir.
Çevirmen (CyberRulz06) notu: Üzerine uzun süre çalıştığım bu çeviriyi sonunda yayınlama şansını buluyorum. Büyük bir konu olduğundan dolayı hem Türkçe hem de İngilizce hatalar yapmış olabilirim. Fark ederseniz, konu altında veya özelden iletişime geçebilirisiniz.
CyberRulz06 tarafından çevirilmiştir. Asıl makalede bulunan bâzı uzun detayları traşlayıp asıl çözümleri öne taşımaya çalıştım. Anlam bütünlüğü korunması için bazı kelimeler Türkçe de farklı çevirilmiştir ve orijinal görseller kullanılmıştır. İyi okumalar ve iyi forumlar
Kozlovski, S. (2024, May 9) Kafka 101. Kafka 101


