


Merhaba dostlarım, bu makalemde sizlere "Yapay zeka", "Makine öğrenmesi" gibi alanlarda karşımıza çıkan ve oldukça popüler olan
"Karar (Decision) Ağacı"
konusunda bilgi vereceğim.
Makalede "Karar Ağaçları" hakkında detaylı bilgiler edinebileceksiniz, farklı algoritmalar ile karşılaşacaksınız, çeşitli formüller göreceksiniz.
Ayrıca yine makalede bazı algoritmalara "Python3" kullanarak örnekler vereceğim ve bu kodları inceleyeceğiz.
Foruma katkısı ve bu alanda çalışacak arkadaşlara faydalı olması dileğiyle diyerek başlamak istiyorum.
İyi okumalar.
|
|
v

Karar (Decision) Ağacı

Karar Ağaçları (Decision Trees); parametrik olmayan, regresyon ve sınıflandırma işlemleri için kullanılmakta olan bir “Denetimli öğrenme” yöntemidir. Bu yöntem, mevcut sorudan önceki soruların nasıl cevaplandığına bağlı olarak işlemi kategorize eder veya tahminde bulunur.
Karar Ağacı yöntemi, kategorize etme ve tahmin etme için kullanılan hem çok güçlü hem de en popüler yöntemlerden biridir. Ağaç; her düğümünün bir testi, her dalın testin bir sonucunu, her yaprağın (terminal düğümü) bir sınıfı temsil ettiği bir akış şematiğidir diyebiliriz.
Bu yöntemin amacı ise, verilerden çıkarılacak basit karar kurallarını öğrenmek ve hedefteki bir değişkenin değerini tahmin edebilmektir. Yöntem, istenilen kategorizasyon işlemi için bir dizi veri üzerinde önce eğitilir sonra test edilir.
Karar Ağaçları’nın verdiği cevap veya kararlar her zaman için net olmayabilir. Bu durumlarda veri bilimci için düzgün kararlar verebilmesi adına bir takım seçenekler sunabilir. Bu yöntem bir nevi insan çıkarımlarını taklit ettiğinden dolayı, veri bilimcinin sonuçlar için yorum yapabilmesi kolay olur.
Karar analizinde ise bir karar ağacı, alternatifi olan rakiplerin beklenen faydasının veya değerlerinin hesaplandığı hem görsel hem analitik olan bir karar-destek aracı pozisyonunda kullanılır.
Bir karar ağacında 3 tür düğüm bulunur:
Decition Node (Karar düğüm) -> Genelde “Kare” şekli ile temsil gösterilir,
Chance Node (Şans düğüm) -> Genelde “Daire” şekli ile temsil gösterilir,
End Node (Uç düğüm) -> Genelde “Üçgen” şekli ile temsil gösterilir.
Yöneylem araştırmaları ve operasyon yönetimi gibi durumlarda yaygın olarak kullanılan Karar Ağaçları, koşullu olasılıkların hesaplanmasında oldukça açıklayıcı olabilmektedir. Ayrıca Karar Ağaçları işletme, sağlık, ekonomi, askeri, araştırma, planlama gibi birçok alanda başvurulan bir mekanizmadır.
Bir Karar Analiz adımları şu maddelerden oluşur:
Karar verme işlemi için sorun alanının tanımlanması.
Olası tüm çözümleri ve bunların sonuçlarını içeren bir Karar Ağacı çizimi.
Değişkenlerin, ilgili olasılık değerleri ile girilmesi.
Olası her sonuç için getirilerin belirlenmesi ve tahsis edilmesi.
Çözümlerden hangisinin en çok değer sağlaması hususunun beklendiğini belirlemek adına tüm şans düğümleri için beklenen parasal değerin hesaplanması.
Karar Ağacı nasıl çalışır?

“Karar Ağacı nasıl çalışır?” konusuna girmeden önce, karşılaşacağımız terimlere bir bakalım:
Root Node (Kök düğüm): Karar ağacının temel düğümüdür.
Splitting (Bölme): Herhangi bir düğümü bir veya birden çok alt düğüme bölmek anlamına gelir.
Decision Node (Karar düğüm): Bir alt düğümün daha fazla alt düğümlere bölündüğünün belirtecidir.
Leaf / Terminal Node (Yaprak düğüm): Bir alt düğüm daha fazla alt düğümlere bölünmediği zaman olası sonuçların belirtecidir.
Pruning (Budama): Karar ağacındaki alt düğümlerin kaldırılmasını belirtir.
Branch (Dal): Karar ağacında bulunan alt bölümlerin her biri.
Karar Ağacı, tıpkı bir ağaç gibidir. Ağacın köklerine Kök Düğüm diyebiliriz. Kök düğümden ise Karar Düğümleri iletilir. Karar düğümlerinde, alınan kararların sonuçları diyebileceğimiz Yaprak Düğümler vardır. Yani, her Karar Düğümü bir bölünme noktasını veya bir soruyu temsil ederken Yaprak Düğümler ise olası cevapları temsil eder.
Bu anlattıklarımı bir örnek ile pekiştirelim.
Bir halısaha maçımız olsun. Takımın golcüsü de biz olalım. İstikrarlı bir oyuncuyuz ve her maç 3 ile 5 arasında gol atıyoruz. Peki, ilk bakışta bu akşam oyanaycağımız maçta da aynı şekilde 3-5 gol atarız diye düşünebilirsiniz. Ancak burada skorumuzu etkileyecek birkaç farklı durum (sapma) olabilir. Bunlar; yorgunluk durumu, halısahaya kadar yürüyerek mi yoksa araba ile mi gidildiği, herhangi bir rahatsızlığın olup olmaması, aç veya tok olma durumu gibi durumlar olabilir. İşte Karar Ağacı, bu gibi durumlara verilen cevaplar ile o akşam yapacağımız maçta kaç gol atacağımızı tahmin etmek için bize yardımcı olur.
Bir görsel ile anlatmak icap edebilir.
Buyrun;
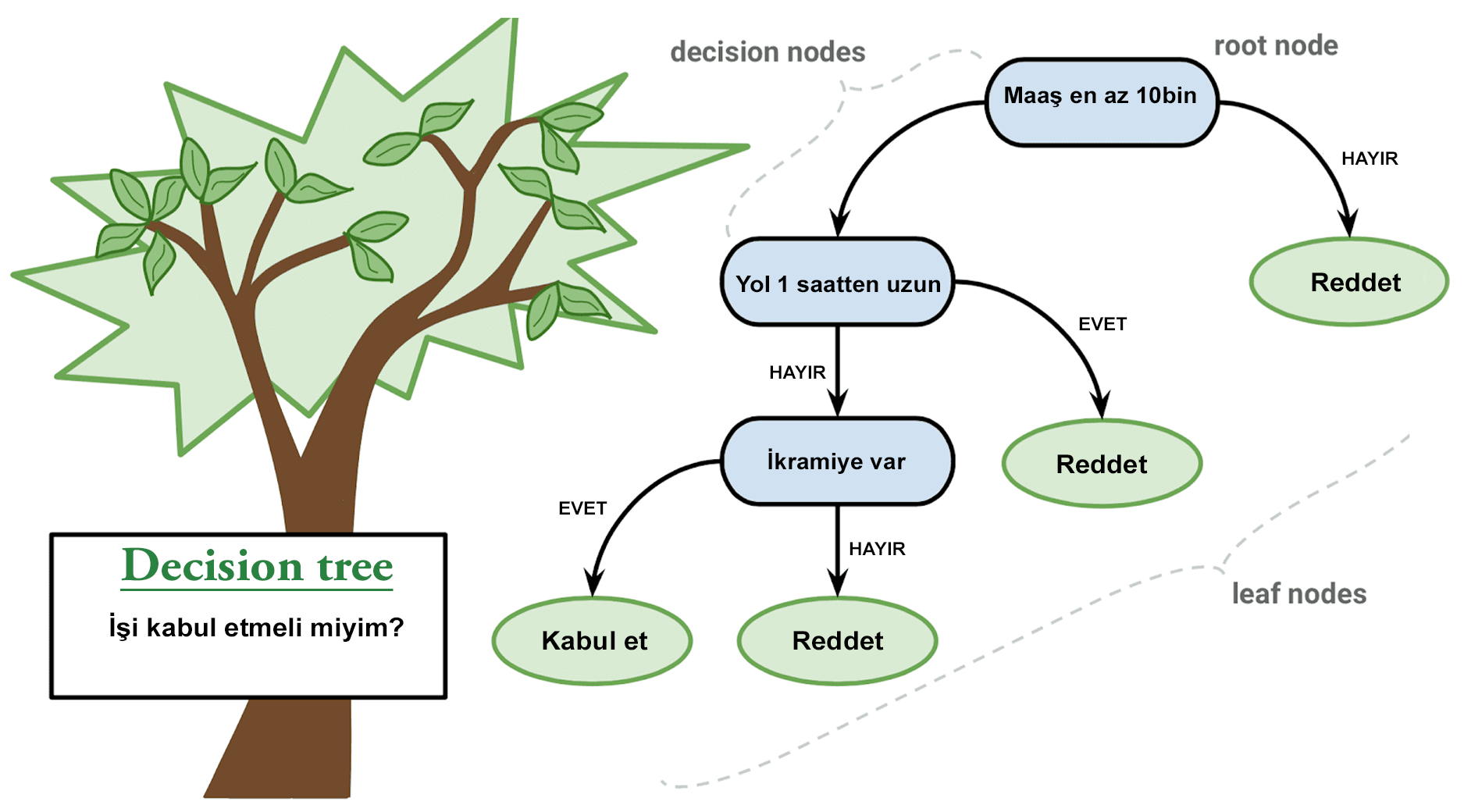
Görselde anlattığım durumda, işi kabul etmemiz için tüm istekler yerine getirilmeliydi.
Peki, birden fazla kabul durumu nasıl olur?
Buyrun;
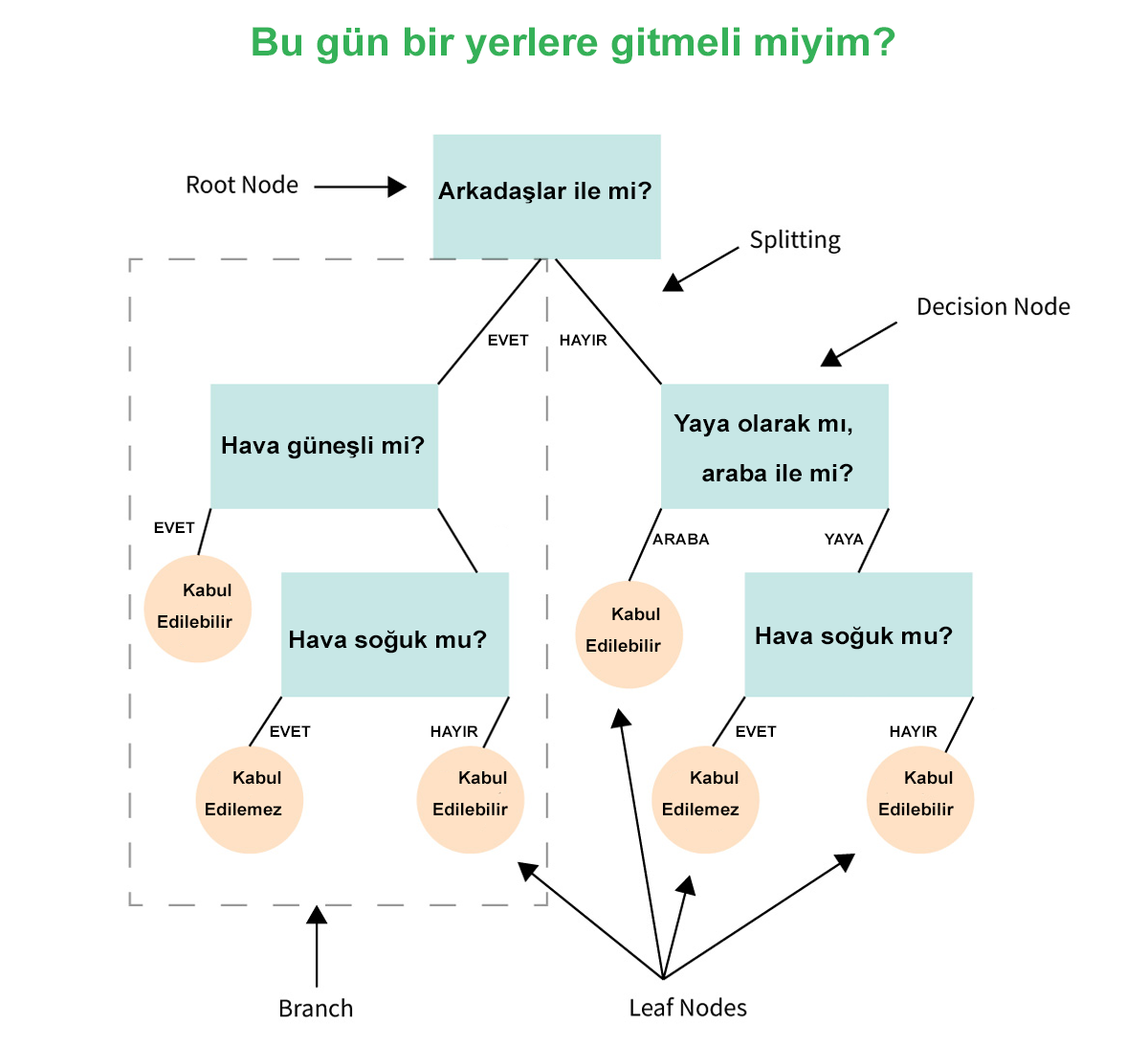
Bu görselde anlattığım üzere, birden çok kabul etme durumu yaşanabilir.
Karar ağaçları, var olan verilerde bulunan hedef değişkenin türüne bağlı olarak iki farklı türde olabilir:
Kategorik değişken Karar Ağacı; kategorik bir hedef değişkene sahiptir.
Sürekli değişken Karar Ağacı; sürekli bir hedef değişkene sahiptir.
Bunların ayrıntılarını sizlere bırakıyorum canlar. Ben hızlıca algoritmalara geçeceğim.
Algoritmalar
Bir düğümün iki veya daha fazla alt düğüme bölünmesi husus için birden çok algoritma kullanılmaktadır. Bu durum, hedef değişkene bağlı düğüm saflığını, homojenliğini arttırır. Karar Ağacı, düğümleri var olan tüm değişkenlere böler, daha sonra en homojen bölmeyi seçer.
Hedef değişkenin türüne göre algoritma seçimi yapılır. Karar Ağaçları’nda kullanılan birkaç algoritmaya göz atalım:
ID3 (D3 uzantısı)
C4.5 (ID3’ün halefi)
CART (Sınıflandırma ve Regresyon Ağacı)
CHAID (Chi-square Sınıflandırma Ağaçları hesaplanırken yüksek seviyeli bölmeler gerçekleştirir)
MARS (Çok değişkenli ve uyarlanabilir regresyon eğrileri)
Peki, bu algoritmaların bazıları hakkında biraz daha bilgi sahibi olalım.
ID3 (Yinelemeli Dichotomiser), “Ross Quinlan” tarafından 1986 yılında geliştirilmiştir. Bu algoritma; her bir düğüm için, kategorize hedeflere en fazla bilgi kazancını sağlayacak özelliği bularak bir ağaç oluşturur. Oluşturulan bu ağaçlar maksimum boyuta ulaştırılır, hemen ardından bir budama işlemi uygulanır.
C4.5; ID3 algoritmasının, sürekli öznitelik değerini ayrık bir aralık kümesine bölen ayrık bir öznitelik tanımlayarak, kategorik özellik kuralını kaldırır. Algoritma, eğitim süreci bitmiş ağaçları (burada ID3 çıktısı) “if - then” kural kümelerine dönüştürür. Her kuralın bu dönüşümü, uygulanması gereken sıralamayı belirtmek için kullanılır. Budama işlemi, kural onsuz yapılandırılabilirse kuralın ön koşulu kaldırıldıktan sonra uygulanır.
CART (Sınıflandırma ve Regresyon Ağacı); C4.5 algoritmasına oldukça benzemektedir. Kendisini ayrıran başlıca özelliği sayısal hedef değişkenlerini desteklemesidir. Algoritma, her düğümde en yüksek kazancı sağlayan özelliği ve eşiği kullanır ve ikili ağaçlar oluşturur.
NOT: “scikit-learn”, CART algoritmasının optimize edilmiş sürümünü kullanır. Ancak ne yazık ki kategorik değişkenleri desteklemez.
Nitelik Seçim Ölçüleri
Elimizde bulunan veri setimiz N sayıda özniteliğe sahipse, bunların hangisinin köke veya ağacın farklı seviyelerine düğümler olarak konumlandırılacağına karar vermek karmaşık olacaktır. Bunun yanısıra rastgele bir tavır izlersek, bu sefer de doğruluk payı düşük sonuçlar elde edeceğiz.
Bu problemi çözmek için bazı kriterler kullanılması öneriliyor.
Bunlar;
Entropy (Entropi),
Information Gain (Bilgi kazanımı),
Gini Index (Gini indeksi),
Gain Ratio (Kazanç oranı),
Reduction in Variance (Varyans azaltmak),
Chi-Square
Sıraladığım kriterler her bir özellik için değer hesaplaması yapacaktır. En yüksek değere sahip öznitelik köke yerleştirilecektir.
Peki, sizlere bu kriterler hakkında daha detaylı bilgiler vereyim.
Entropy (Entropi); gözlemde bulunan bir dizi saf olmayan veya belirsiz durumunu ölçen bilgi teorisi metriğidir.
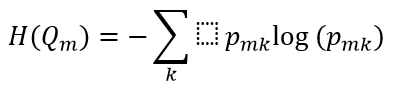
Gini Index (Gini indexi); her bir sınıfın olasılıklarının kareleri toplamı 1’den çıkarılarak hesaplanır. Uygulaması kolaydır ve daha büyük bölümlerde tercih edilir. Bu bölme için daha küçük bir Gini indeksine sahip özellik seçilir.
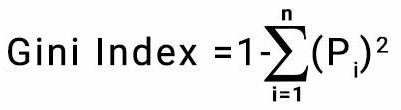
Python:
# Gerekli kütüphanelerin yüklenmesi
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
# Veri Kümesini içe aktarma fonksiyonu
def importdata():
balance_data = pd.read_csv(
'https://archive.ics.uci.edu/ml/machine-learning-' +
'databases/balance-scale/balance-scale.data',
sep=',', header=None)
# Datasetin şeklini yazdırma işlemi
print("Dataset Length: ", len(balance_data))
print("Dataset Shape: ", balance_data.shape)
# Veri kümesi gözlemlerini yazdırma işlemi
print("Dataset: ", balance_data.head())
return balance_data
# Veri kümesini bölme fonksiyonu
def splitdataset(balance_data):
# Hedef değişkeni ayırma işlemi
X = balance_data.values[:, 1:5]
Y = balance_data.values[:, 0]
# Veri kümesini eğitim ve test olarak bölme işlemi
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.3, random_state=100)
return X, Y, X_train, X_test, y_train, y_test
# Gini index'i ile eğitim gerçekleştirme fonksiyonu
def train_using_gini(X_train, X_test, y_train):
# Sınıflandırıcı nesneyi oluşturma işlemi
clf_gini = DecisionTreeClassifier(criterion="gini",
random_state=100, max_depth=3, min_samples_leaf=5)
# Eğitim işlemi
clf_gini.fit(X_train, y_train)
return clf_gini
# Entropi ile eğitim gerçekleştirme fonksiyonu
def tarin_using_entropy(X_train, X_test, y_train):
# Entropili karar ağacı işlemi
clf_entropy = DecisionTreeClassifier(
criterion="entropy", random_state=100,
max_depth=3, min_samples_leaf=5)
# Eğitim işlemi
clf_entropy.fit(X_train, y_train)
return clf_entropy
# Tahmin yapma fonksiyonu
def prediction(X_test, clf_object):
# Predicton on test with giniIndex
y_pred = clf_object.predict(X_test)
print("Predicted values:")
print(y_pred)
return y_pred
# Doğruluğu hesaplama fonksiyonu
def cal_accuracy(y_test, y_pred):
print("Confusion Matrix: ",
confusion_matrix(y_test, y_pred))
print("Accuracy : ",
accuracy_score(y_test, y_pred) * 100)
print("Report : ",
classification_report(y_test, y_pred))
# Driver code
def main():
# işlemleri inşa etme aşaması
data = importdata()
X, Y, X_train, X_test, y_train, y_test = splitdataset(data)
clf_gini = train_using_gini(X_train, X_test, y_train)
clf_entropy = tarin_using_entropy(X_train, X_test, y_train)
print("Results Using Gini Index:")
# gini kullanarak tahmin yapmak
y_pred_gini = prediction(X_test, clf_gini)
cal_accuracy(y_test, y_pred_gini)
print("Results Using Entropy:")
# entropi kullanılarak tahmin yapmak
y_pred_entropy = prediction(X_test, clf_entropy)
cal_accuracy(y_test, y_pred_entropy)
# ana fonksiyon çağırılır
if __name__ == "__main__":
main()Gain Ratio (Kazanç oranı); bilgi kazancının içsel bilgiye olan oranı olarak tanımlanır. Öznitelik seçilirken dalların sayısı ve boyutu dikkate alınarak yüksek değerli öznitelikler için oluşturulan önyargıları hafifletmek için Karar Ağaçları oluşturucusu olan “Ross Quinlan” tarafından önerildi.

Information Gain (Bilgi kazanımı); mevcut bir veri kümesini dönüştürerek sürprizdeki azalmayı veya entropiyi temsil eder. Genellikle Karar Ağaçları’nın eğitiminde kullanılır. Bir dönüşümden önce ve sonra oluşan veri kümesinin entropisini karşılaştırarak hesaplanır.

Python:
# gerekli kütüphanenin yüklenmesi
from math import log2
# veri kümesindeki bölünme için entropiyi hesaplama fonksiyonu
def entropy(class0, class1):
return -(class0 * log2(class0) + class1 * log2(class1))
# ana veri kümesinin bölünmesi işlemi
class0 = 13 / 20
class1 = 7 / 20
# değişiklikten önceki entropiyi hesapla
s_entropy = entropy(class0, class1)
print('Dataset Entropy: %.3f bits' % s_entropy)
# bölme 1 (değer1 ile bölme)
s1_class0 = 7 / 8
s1_class1 = 1 / 8
# ilk grubun entropisini hesaplama işlemi
s1_entropy = entropy(s1_class0, s1_class1)
print('Group1 Entropy: %.3f bits' % s1_entropy)
# bölme 2 (değer2 ile bölme)
s2_class0 = 6 / 12
s2_class1 = 6 / 12
# ikinci grubun entropisini hesaplama işlemi
s2_entropy = entropy(s2_class0, s2_class1)
print('Group2 Entropy: %.3f bits' % s2_entropy)
# bilgi kazancını hesaplamak
gain = s_entropy - (8/20 * s1_entropy + 12/20 * s2_entropy)
print('Information Gain: %.3f bits' % gain)Reduction in Variance (Varyans azaltmak); hedef değişkenin sürekli olduğu durumlarda regresyon problemlerinde bulunan düğümü bölmek için kullanılan bir yöntemdir. Herhangi bir düğümün homojenliğini hesaplamakta kullanılır.
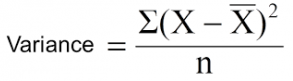
Chi-Square; ağaçta bulunan alt düğümler ile onların üst düğümleri arasındaki farkların istatistiksel önemini ölçmek için kullanılır. Her bir düğüm için hedef değişkenin gözlemlenen frekanslarının arasındaki kare, standartlaştırılmış farkların toplamıdır.

Python:
# gerekli kütüphanelerin yüklenmesi
from scipy.stats import chi2_contingency
from scipy.stats import chi2
# olasılık tablosu işlemi
table = [ [10, 20, 30],
[6, 9, 17]]
print(table)
stat, p, dof, expected = chi2_contingency(table)
print('dof=%d' % dof)
print(expected)
# test istatistiğini yorumlama işlemi
prob = 0.95
critical = chi2.ppf(prob, dof)
print('probability=%.3f, critical=%.3f, stat=%.3f' % (prob, critical, stat))
if abs(stat) >= critical:
print('Dependent (reject H0)')
else:
print('Independent (fail to reject H0)')
# p-değerini yorumla işlemi
alpha = 1.0 - prob
print('significance=%.3f, p=%.3f' % (alpha, p))
if p <= alpha:
print('Dependent (reject H0)')
else:
print('Independent (fail to reject H0)')Bu güzel örnekler için Teşekkür ederiz.
Bu algoritmaların çıktılarına baktığımız zaman ise;
Entropi ve Gini index için;
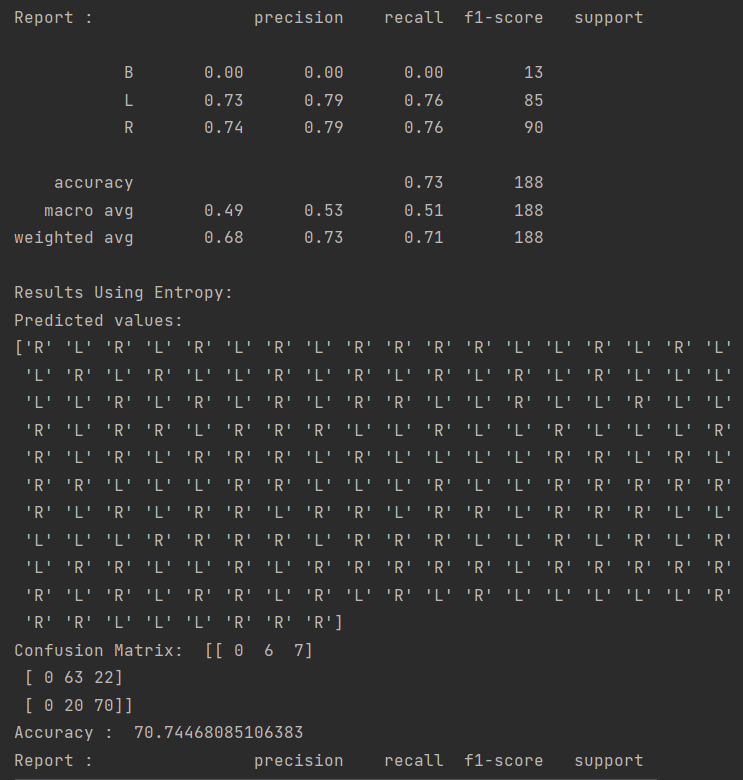
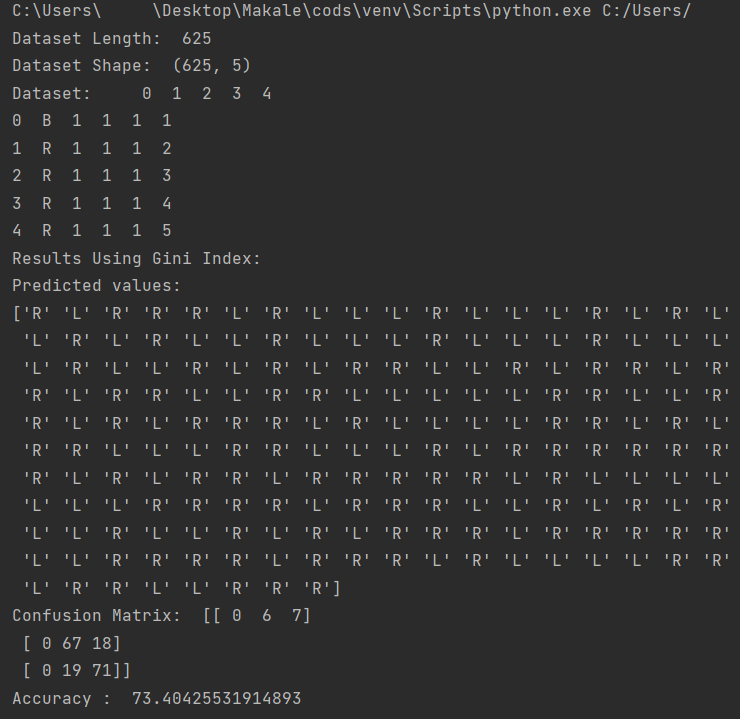
İnformatin gain ve Chi-square için ise;
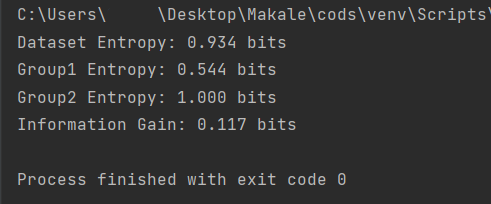
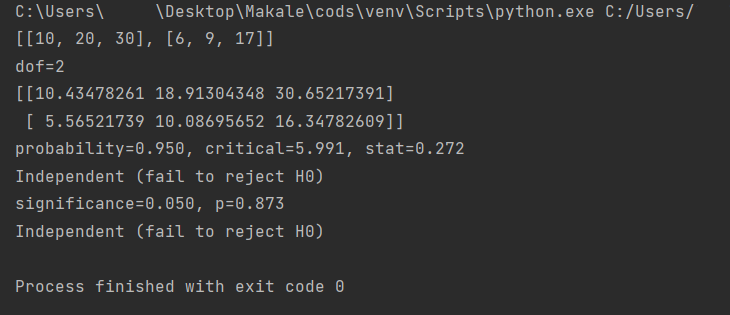
çıktılarını alıyoruz.
Kodları denemeden önce gerekli kütüphaneleri indirmeniz gerekmektedir.
Bunun için;
pip install -U scikit-learnpip install pandaspip install numpyadımlarını uygulayabilirsiniz.
Karar Ağacı Parametreleri
Kısa bir bölümde de bu Karar Ağaçları oluşturulurkan kullanılan parametrelere bir bakalım.
Max_Depth (Maksimum derinlik); bir karar ağacındaki en fazla olabilecek derinliği temsil eder. Ağacın derinliği daha fazla bilgi toplamasını ve dolayısıyla daha doğru yorumların yapılmasını sağlar. Ancak fazla derin bir ağaç aşırı uyumaya sebep olabilir. Bu durumda ise eğitimde veriler üzerine genelleme yapılacağı ancak test evresinde performansın düşeceğini anlamak gerekir.
Min_samples_split (Minimum örnek bölümü); bir düğüm bölümü için gerekli minimum örnek sayısını temsil eder.
Min_samples_leaf (Minimum yaprak verisi); herhangi bir düğümü yaprak düğüm olarak sınıflandırabilmek için gerekli olan minimum örnek sayısını temsil eder.
Criterion (Kriter, ölçüt); Herhangi bir düğümün bölünmeyi gerçekleştirmeye çalışırken ki etki düzeyini değerlendirmek için Gini ve Entropi kriterlerinin kullanılmasını temsil eder.
Class_weight (Sınıf ağırlığı); kriter, dengesiz veri bulunması halinde kullanılır. Bu paramete ağırlıkları farklı sınıflara uygularken büyük ölçekte rol oynar.
Avantaj / Dezavantaj
Bazı avantajlar şunlar olabilir;
Görselleştirilebilir, anlaması ve çıkarımda bulunulması kolaydır.
Veri hazırlığı süreci kısadır.
Kullanım maliyeti (veri tahmini), ağacın öğreniminde kullanılan veri noktalarının sayısında logaritmiktir.
Hem kategorik hem de sayısal veriler işlenebilir.
Çoklu çıkış problemlerini çözer.
Bir Beyaz kutu modeli kolayca açıklanabilir. Kara kutu modelinde sonuçlar daha zor yorumlanablilir.
Bir modeli doğrulamada istatistiksel testler kullanılabilir. Bu durum, model güvenliğini hesaba katmayı sağlar.
Performans olarak iyidir.
Bazı dezavantajlar şunlar olabilir;
Karar Ağacı konusunda acemi olanlar, aşırı karmaşık ağaçlar oluşturabilir. Bu duruma “Aşırı takma” denir. Bu sorundan uzak durmak için budama işlemi, yaprak düğümlerinin minimum numune sayılarının ayarlanması, ağacın maksimum derinliğinin ayarlanması gibi kontroller uygulanabilir.
Verilerdeki küçük değişiklikler tamamen farklı bir Karar Ağacı üretebilir. Bu durumda Karar Ağaçları kararsız olur.
Ekstrapolasyon konusunda iyi değillerdir. Bir Karar Ağacı’nın tahminleri ne sürekli ne de düzgündür.
Global olarak en uygun Karar Ağacı’nın döndürülmesi garanti edilmez.
Karar Ağaçları’nın kolay ifade edemediği (XOR, multiplexer veya parite gibi) kavramlar vardır.
Karar Ağacı konusunda acemi olanlar, bazı sınıfların baskın olması durumunda önyargılı ağaçlar oluşturabilirler. Bu duruma düşmemek için işlemden önce veri setinin dengelenmesi yapılmalıdır.
^
|
|
|
|
Değerli dostlarım, güzel kardeşlerim;
Bu makalemde kısaca "Karar Ağaçları nedir?" sorusuna cevap bulduk.
Ardından "Karar ağaçlarında kullanılan bazı algoritmalar" konusunda birkaç örnek yaptık.
Kaynak niteliğinde bu forumda kalması temennisi ile diyerek sözlerimi bitiriyorum.
Sağlıcakla kalın.

Son düzenleme:
")


