


Merhaba dostlarım,bu makalemde sizlere "Makine öğrenmesi (ML)" alanında karşımıza çıkan ve oldukça popüler olan modelleri,algoritmaları anlatacağım. Bu makale bir devam makalesi olduğundan, konuyu daha iyi anlayabilmek için bir önceki makalem olan "Supervised ML" makalesini incelemenizi tavsiye ediyorum. Bu bakalede ise "Unsupervised ML" kavramına değineceğiz. Ayrıca yine makaledeki algoritmalara "Python3" kullanarak örnekler vereceğim ve bu kodları inceleyeceğiz. Foruma katkısı ve bu alanda çalışacak arkadaşlara faydalı olması dileğiyle diyerek başlamak istiyorum.
İyi okumalar.
|
|
v
Makine öğrenmesi (ML) nedir? | Önemi | Çalışma mantığı | Denetimli öğrenme | Avantaj&Dezavantaj
||
V
Machine Learning Models #1

Denetimsiz (Unsupervised) öğrenme nedir?
|
v
Makine öğrenmesi (ML) nedir? | Önemi | Çalışma mantığı | Denetimli öğrenme | Avantaj&Dezavantaj
||
V
Machine Learning Models #1
Denetimsiz (Unsupervised) öğrenme nedir?
Denetimsiz (Unsupervised) öğrenme ; etkilenmemiş veya ilk defa karşılaşılan veri kümeleri kullanılarak modellerin eğitildiği ve bir denetlemeye tabi tutulmadan veriler üzerinde işlem yapılabildiği makine öğrenimi (ML) tekniğidir.
Burada modelin görevi, daha öncesinden herhangi bir eğitim sürecinde bulunmadan benzerliklere, kalıplara ve farklılıklara göre sıralanmamış verileri etiketlemek veya gruplamaktır. Model; bir AI sistemi, hiçbir kategori sağlanmasa bile sıralanmamış bilgileri benzerliklere, kalıplara ve farklılıklara göre gruplama işlemini tamamlayacaktır.
Denetimsiz öğrenmede, Denetimli öğrenmenin aksine öğretmen sağlanmaz. Bu durum ise modele eğitim verilmeyeceği anlamına gelir. Bu nedenle model, etiketlenmemiş verilerdeki gizli yapıyı kendi kendine bulmakla yükümlüdür.
Denetimsiz öğrenme (Unsupervised), bir sınıflandırma veya regresyon problemine direkt olarak uygulanamaz. Nedeni ise; bu durumlarda (Denetimli öğrenmenin aksine) girdi (Input) verilerinin elde bulunması ancak bunlara karşılık gelecek çıktı (Output) verilerinin elde bulunmamasıdır.
Örnek verecek olursak;
Hayvanlar ile ilgili bir veri setinin elimizde olduğunu varsayalım. Burada farklı cinste kedi ve köpekler bulunuyor olsun. Denetimsiz öğrenme algoritması hiçbir zaman veri setinin üzerinde eğitilmediğinden, algoritmanın veri seti özelliklerinden haberinin olmadığını söyleyebiliriz. Burada algoritmanın görevi, görüntü özelliklerinin kendi başına tanımlayarak, görüntüler arasındaki benzerliklere göre verileri gruplamaktır.

Denetimsiz öğrenme algoritmaları, denetimli öğrenme algoritmalarından daha karmaşık işleme görevleri gerçekleştirebilir. Ek olarak, bir sistemi denetimsiz öğrenmeye tabi tutmak, yapay zekayı test etmenin bir yoludur. Ancak bunun yanı sıra Denetimsiz öğrenme, diğer doğal öğrenme yöntemlerine kıyasla daha öngörülemez de olabilir.
Bu duruma örnek verecek olursak; Denetimsiz bir öğrenme modeli, kedileri ve köpekleri birbirinden nasıl ayıracağını kendi başına çözebilirken, sıra dışı/nadir türlerle başa çıkmak için öngörülemeyen ve istenmeyen kategoriler ekleyerek düzen yerine dağınıklık yaratabilir.
Neden kullanılır?

Denetimsiz (Unsupervised) öğrenmenin kullanılmasının başlıca nedneleri şunlar olabilir;
Denetimsiz makine öğrenimi, verilerde her türlü bilinmeyen modeli bulur.
Denetimsiz yöntemler, sınıflandırma için yararlı olabilecek özellikleri bulmanıza yardımcı olur.
Denetimsiz öğrenme, bir insanın kendi deneyimleriyle düşünmeyi öğrenmesine çok benzer, bu da onu gerçek yapay zekaya daha yakın hale getirir.
Denetimsiz öğrenme, denetimsiz öğrenmeyi daha önemli hale getiren etiketlenmemiş ve kategorize edilmemiş veriler üzerinde çalışır.
Gerçek zamanlı olarak gerçekleşir, bu nedenle tüm girdi verileri öğrencilerin huzurunda analiz edilir ve etiketlenir.
Bir bilgisayardan etiketlenmemiş verileri almak, manuel müdahale gerektiren etiketli verilere göre daha kolaydır.
Gerçek dünyada, her zaman karşılık gelen çıktıya sahip girdi verisine sahip olunadığından, bu tür durumları çözmek için denetimsiz öğrenmeye ihtiyaç vardır.
Örnek
Denetimsiz (Unsupervised) öğrenmenin işleyişine aşağıdaki şema yardımı ile bir bakalım;
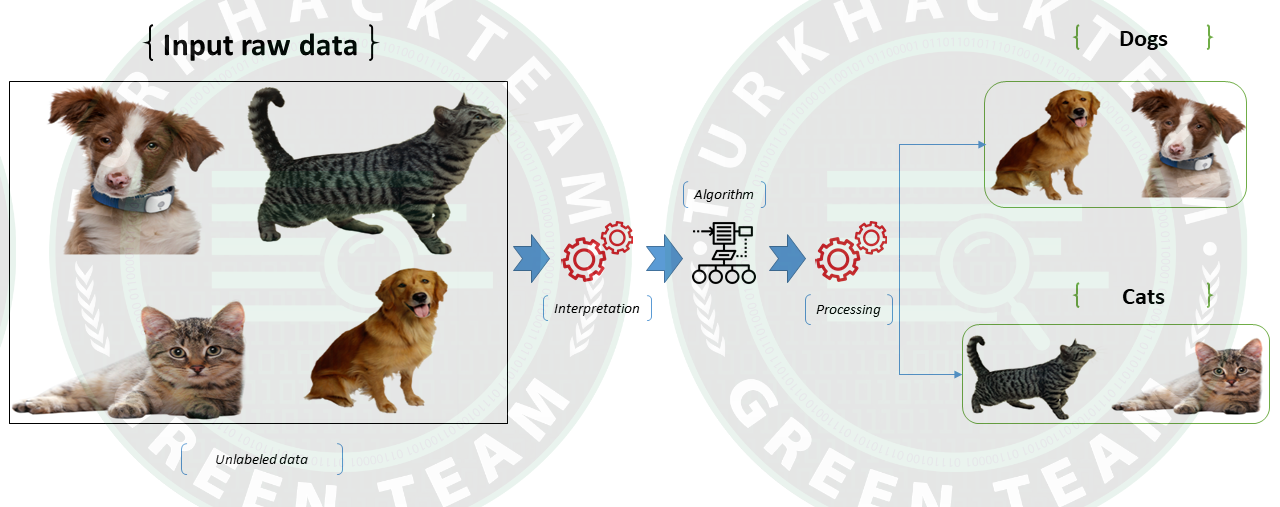
Burada etiketlenmemiş bir girdi verisi bulunuyor. Yani kategorize edilmemiş ve karşılık gelen çıktılar da verilmemiş durumda. İlk önce, bu etiketlenmemiş giriş verileri, onu eğitmek için makine öğrenme modeline verilir. Daha sonra, verilerden gizli kalıpları bulmak için ham verileri yorumlanır ve ardından K-Means Clustering, Hierarchical Clustering vb. gibi uygun algoritmalar uygulanır.
Uygun algoritmayı uyguladıktan sonra, algoritma veri nesnelerini nesneler arasındaki benzerlik ve farklılıklara göre gruplara ayırır.
Denetimsiz (Unsupervised) öğrenme teknikleri
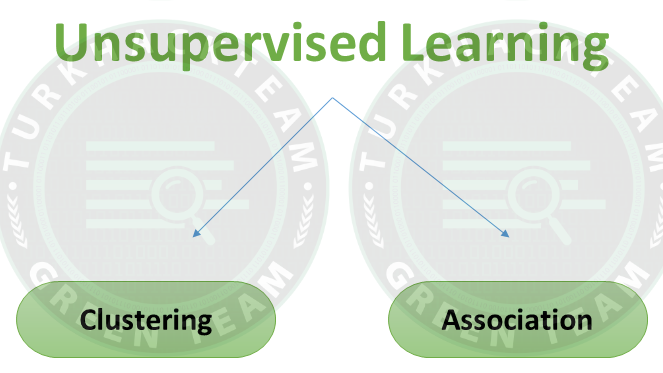
Kümeleme (Clustering): Denetimsiz öğrenme söz konusu olduğunda önemli bir kavramdır. Esas olarak, kategorize edilmemiş bir veri koleksiyonunda bir yapı veya örüntü bulmakla ilgilenir.
Kümeleme, en çok benzerliğe sahip nesnelerin bir grupta kalacağı ve başka bir grubun nesneleriyle daha az benzerliği olacak veya hiç benzerliği olmayacak şekilde nesneleri kümeler halinde gruplandırma yöntemidir.
Kümeleme analizi, veri nesneleri arasındaki ortak noktaları bulur ve bunları bu ortak noktaların varlığına ve yokluğuna göre sınıflandırır.
İlişkilendirme (Association): Birliktelik kuralları, büyük veritabanlarındaki veri nesneleri arasında ilişkilendirmeler oluşturmanıza olanak tanır. Veri kümesinde birlikte oluşan öğelerin kümesini belirler. Bu denetimsiz teknik, büyük veritabanlarındaki değişkenler arasındaki ilginç ilişkileri keşfetmekle ilgilidir.
İlişkilendirme kuralı, pazarlama stratejisini daha etkili hale getirebilmektedir. Örnek verecek olursak; Tıraş bıçağı ürününü alan kişiler Tıraş köpüğü veya losyon ürünlerini de satın alma eğilimindedir. İlişkilendirme kuralının tipik bir örneği “Market Basket Analysis”dır.

Kümeleme (Clusterin) türleri:
1. Exclusive (partitioning)
2. Agglomerative
3. Overlapping
4. Probabilistic
Exclusive (partitioning); Bu kümeleme yönteminde Veriler, bir veri yalnızca bir kümeye ait olabilecek şekilde gruplandırılır.
Örnek: K-araçları
Agglomerative; Bu kümeleme tekniğinde her veri bir kümedir. En yakın iki küme arasındaki yinelemeli birleşimler küme sayısını azaltır.
Örnek: Hiyerarşik kümeleme
Overlapping; Bu teknikte, verileri kümelemek için bulanık kümeler kullanılır. Her nokta, farklı üyelik derecelerine sahip iki veya daha fazla kümeye ait olabilir.
Burada veriler uygun bir üyelik değeri ile ilişkilendirilecektir.
Örnek: Bulanık C-Ortalamalar
Probabilistic; Bu teknik, kümeleri oluşturmak için olasılık dağılımını kullanır.
Örneğin: Aşağıdaki anahtar kelimeler
"Siyah ceket"
"Beyaz ceket"
"Siyah etek"
"Beyaz etek"
“ceket” ve “etek” veya “siyah” ve “beyaz” olmak üzere iki kategoriye ayrılabilir.
Clusterin ve Association kavramlarına baktık. Şimdi bunların kullandığı algoritmalara bakış atacağız. İlk olarak Kümeleme (Clustering) ile başlayacağız. Algoritmaların ne olduğuna kısa bir değindikten sonra formül ve Python3 örneğine bakacağız.

Clustering Algoritmaları:
- Hierarchical clustering
- K-means clustering
- Principal Component Analysis
- Singular Value Decomposition
- Independent Component Analysis
Dilerseniz sıra ile başlayalım...

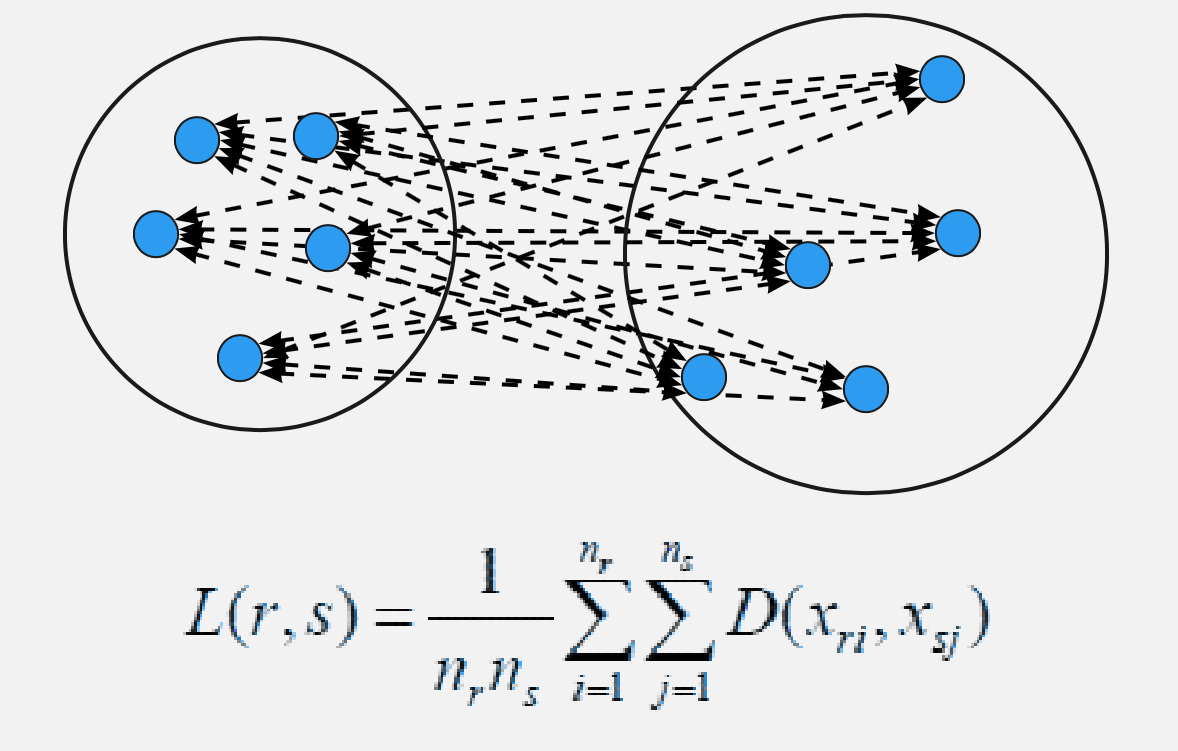
Hierarchical clustering; Hiyerarşik kümeleme analizi olarak da bilinen hiyerarşik kümeleme, benzer nesneleri küme adı verilen gruplara ayıran bir algoritmadır. HCA olarak da adlandırılır. Yukarıdan aşağıya baskın sıralamaya sahip kümeler oluşturmayı hedefler.
Örneğin: Cihazımızın dosya yönetiminde, tüm dosya ve klasörler bir hiyerarşi içerisinde oluşturulmuştur.
Algoritma, benzer nesneleri küme adı verilen gruplara ayırır. Uç nokta, her kümenin birbirinden farklı olduğu ve her kümedeki nesnelerin büyük ölçüde birbirine benzediği bir kümeler veya gruplar kümesidir.
Bu kümeleme tekniği iki türe ayrılır:
Aglomeratif Hiyerarşik Kümeleme
Bölücü Hiyerarşik Kümeleme
Formül;
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import scipy.cluster.hierarchy as sch
from sklearn.cluster import AgglomerativeClustering
# Dataset ayarı
ourData = pd.read_csv('customer_data.csv')
#ourData.head()
newData = ourData.iloc[:, [3, 4]].values
# Dendrogram kullanarak en uygun küme sayısını bulma
#dendrogram = sch.dendrogram(sch.linkage(newData,method = 'ward'))
#plt.title('Dendrogram')
#plt.xlabel('Customers')
#plt.ylabel('Euclidean distances')
#plt.show()
# Agglomerative_clustering yapımı
Agg_hc = AgglomerativeClustering(n_clusters = 5, affinity = 'euclidean', linkage = 'ward')
y_hc = Agg_hc.fit_predict(newData)
plt.scatter(newData[y_hc == 0, 0], newData[y_hc == 0, 1], s = 100, c = 'red', label = 'Cluster 1') # plotting cluster 2
plt.scatter(newData[y_hc == 1, 0], newData[y_hc == 1, 1], s = 100, c = 'blue', label = 'Cluster 2') # plotting cluster 3
plt.scatter(newData[y_hc == 2, 0], newData[y_hc == 2, 1], s = 100, c = 'green', label = 'Cluster 3') # plotting cluster 4
plt.scatter(newData[y_hc == 3, 0], newData[y_hc == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4') # plotting cluster 5
plt.scatter(newData[y_hc == 4, 0], newData[y_hc == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()Çıktı;
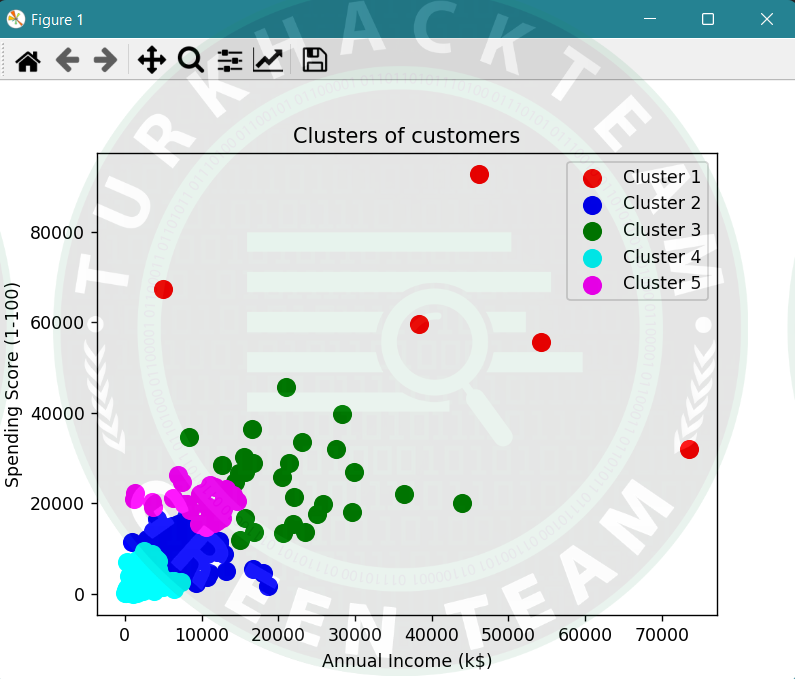

K-Means; K-Means Kümeleme algoritması, en yaygın olarak bilinen kümeleme algoritmasıdır ve her küme içindeki varyansı en aza indirmek için kümelere örnekler atamayı içerir.
Küme içi veri noktalarını mümkün olduğunca benzer hale getirmeye çalışırken, kümeleri mümkün olduğunca farklı (uzak) tutmaya çalışır. Veri noktaları ile kümenin ağırlık merkezi (o kümeye ait tüm veri noktalarının aritmetik ortalaması alınarak bulunur) arasındaki kare uzaklığın toplamı minimum olacak şekilde veri noktalarını bir kümeye atar. Kümeler içinde ne kadar az varyasyona sahipsek, aynı küme içindeki veri noktaları o kadar homojen (benzer) olur.
Formül;
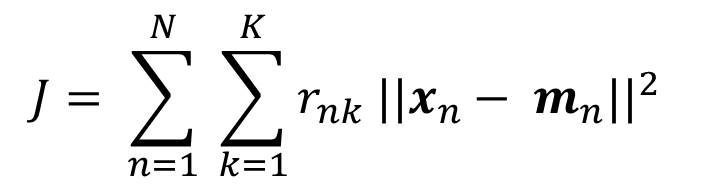
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# Dataset ayarı
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# Model tanımlama
model = KMeans(n_clusters=2)
model.fit(X)
# her örneğe bir küme atama
yhat = model.predict(X)
# benzersiz kümeleri alma
clusters = unique(yhat)
# her kümeden örnekler için dağılım grafiği oluşturma
for cluster in clusters:
# örnekler için satır dizinleri alma
row_ix = where(yhat == cluster)
# örneklerin dağılımını oluşturma
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
pyplot.show()Çıktı;
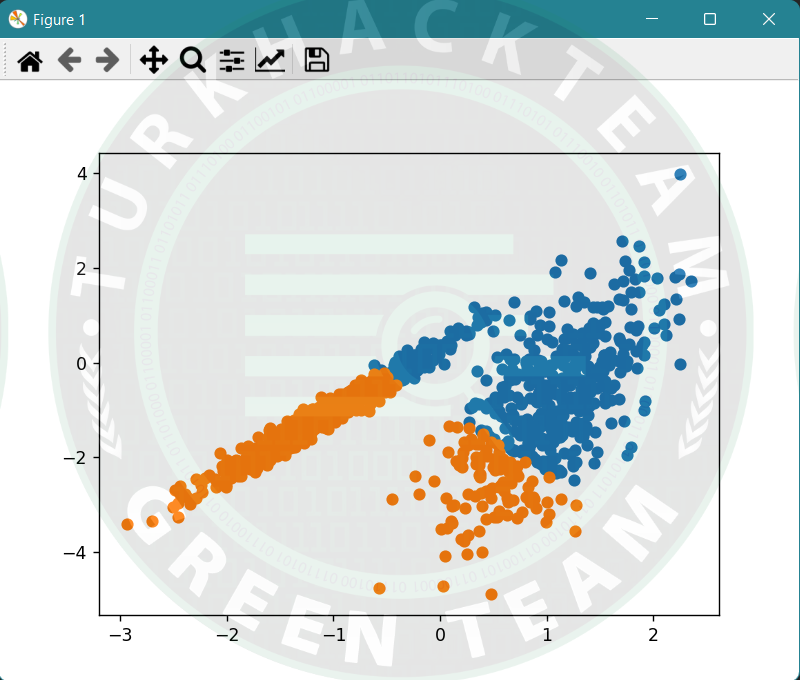

PCA; Temel olarak, kuvvetle muhtemel ilişkili değişkenlerin bir dizi gözlemini, doğrusal olarak ilişkisiz değişkenlerin bir dizi değerine dönüştürmek için istatistiksel bir analizdir.
Temel bileşenlerin her biri, büyük bir bölümü mevcut olan varyansı tanımlayacak şekilde seçilir. Aynı zamanda tüm bu temel bileşenler birbirine dik olmalıdır. Tüm ana bileşenlerde, birinci ana bileşen maksimum varyansa sahiptir.
PCA'nın Kullanım Alanları:
Verilerdeki değişkenler arasında bulunan ilişkileri belirlemek için kullanılabilir.
Verileri yorumlamak ve görselleştirmek için kullanılabilir.
Değişkenlerin sayısı azalacağından, analiz yapmayı kolaylaştırabilir.
Genellikle popülasyonlar arasındaki genetik mesafeyi ve akrabalığı görselleştirmek için kullanılır.
Bunlar temel olarak kare simetrik bir matris üzerinde gerçekleştirilir. Kareler ve çapraz çarpım matrislerinin saf toplamı veya Kovaryans matrisi veya Korelasyon matrisi olabilir. Bireysel varyans çok farklıysa bir korelasyon matrisi kullanılır.
Formül;
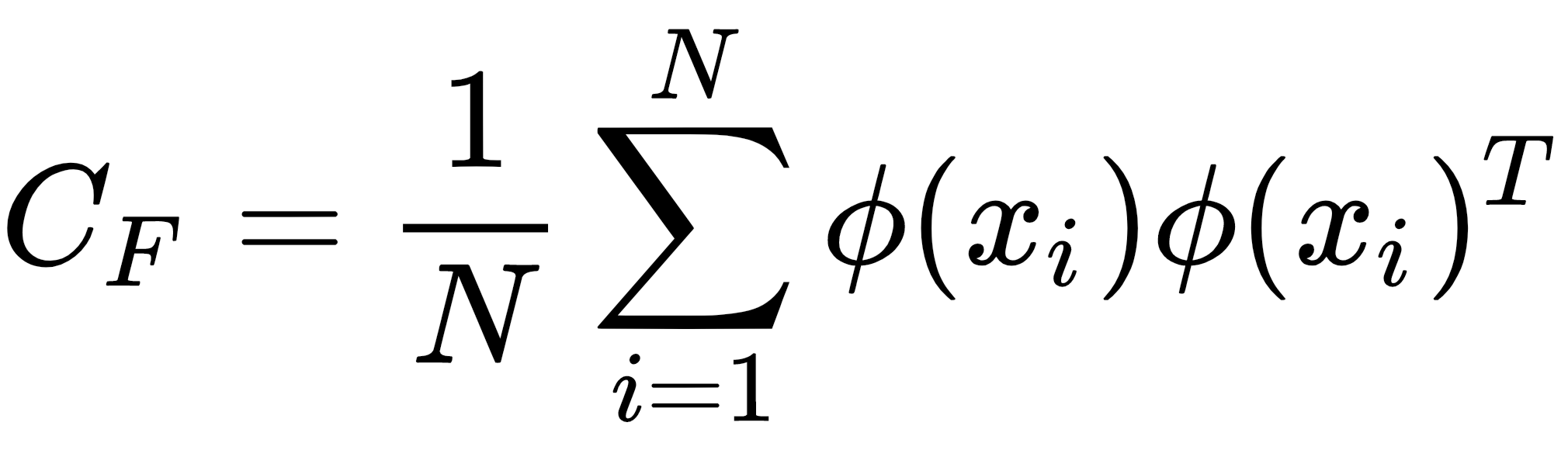
Pyhon3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
#Datast ayarı
dataset = pd.read_csv('wine.csv')
# veri kümesini X ve Y olmak üzere iki bileşene dağıtmak
X = dataset.iloc[:, 0:13].values
y = dataset.iloc[:, 13].values
# Eğitim seti ve Test seti
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Ön işleme parçasının gerçekleştirilmesi
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Eğitimde PCA işlevini uygulama
pca = PCA(n_components = 2)
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
explained_variance = pca.explained_variance_ratio_
# Lojistik Regresyonu Eğitim Setine Sığdırma
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Confusion matris oluşturma
cm = confusion_matrix(y_test, y_pred)
# PyPlot aracılığı ile test seti sonuçlarını görselleştirme
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),
X2.ravel()]).T).reshape(X1.shape), alpha = 0.75,
cmap = ListedColormap(('yellow', 'white', 'aquamarine')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
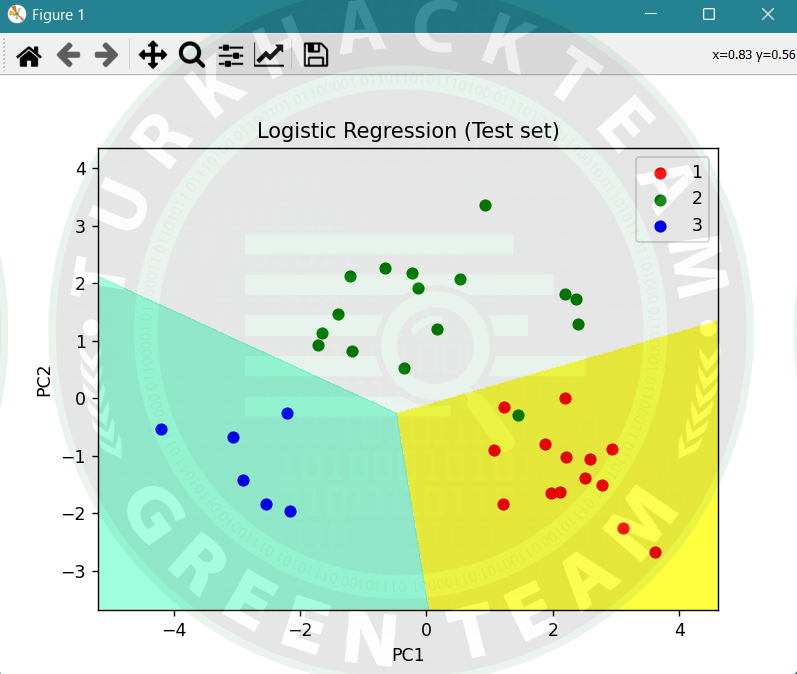
plt.title('Logistic Regression (Test set)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()Çıktı;

SVD; Tekil Değer Ayrışımı veya kısaca SVD, belirli bir adımda bulunan sonraki matris hesaplamalarını daha basit hale dönüştürmek için bir matrisi oluşturan ve bunu parçalarına indirgeyen bir matris ayrıştırma yöntemidir.
Basitlik durumunda, gerçek değerli matrisler için SVD'ye odaklanılır ve karmaşık sayılar için durumu görmezden gelinir.
A = U. Sigma . V^T
“A”, ayrıştırmak istediğimiz gerçek “m x n” matrisi olduğunda, “U” bir “m x m” matrisidir, “Sigma”, bir “m x n” köşegen matrisidir ve “V^T”, T'nin olduğu bir “n x n” matrisinin devrik halidir.
Formül;
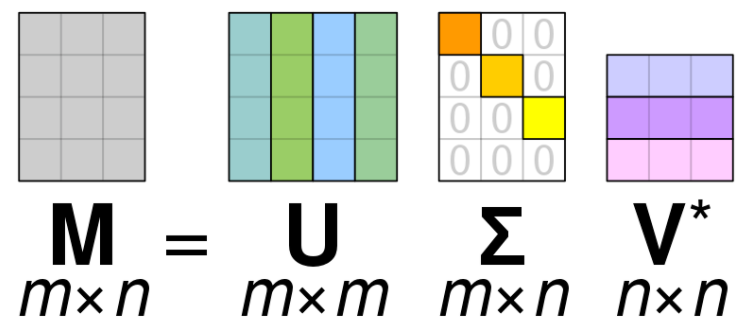
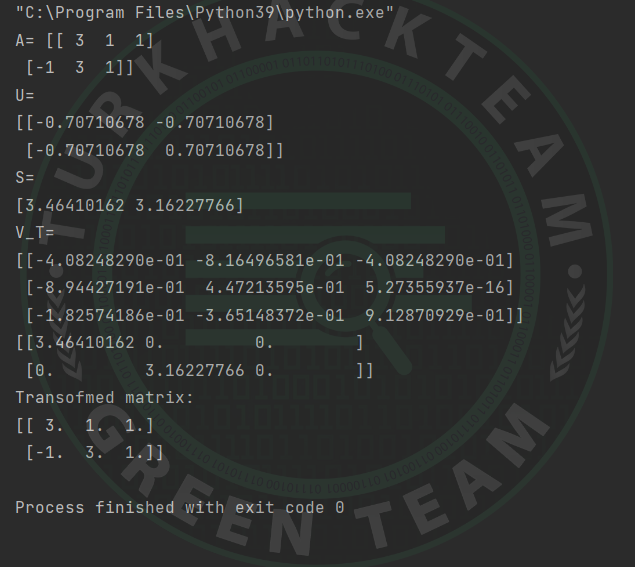
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
from numpy import array
from scipy.linalg import svd
# Matris ayarlama
A = array([[3, 1, 1], [-1, 3, 1]])
print("A=",A)
# SVD
U, S, V_T = svd(A)
print("U=")
print(U)
print("S=")
print(S)
print("V_T=")
print(V_T)
S_diag = array([[3.46410162, 0, 0], [0, 3.16227766, 0]])
print(S_diag)
# Değiştirilmiş matris
B = U.dot(S_diag.dot(V_T))
print("Transofmed matrix:")
print(B)Çıktı;

ICA; Bağımsız bileşen analizi (ICA), rastgele değişken, ölçüm veya sinyal kümelerinin altında yatan gizli faktörleri ortaya çıkarmak için istatistiksel, hesaplamalı bir anazildir.
ICA, gözlemlenen çok değişkenli veriler için tipik olarak geniş bir örnek veritabanı olarak verilen üretici bir model tanımlar. Modelde, veri değişkenlerinin bazı bilinmeyen gizli değişkenlerin doğrusal karışımları olduğu varsayılır ve karıştırma sistemi de bilinmemektedir. Gizli değişkenlerin “gaussyen” olmadığı ve karşılıklı olarak bağımsız olduğu varsayılır ve bunlara gözlemlenen verilerin bağımsız bileşenleri denir. Kaynaklar veya faktörler olarak da adlandırılan bu bağımsız bileşenler, ICA tarafından bulunabilir.
Formül;
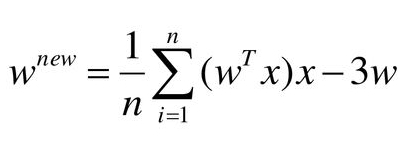
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import pandas as pd
import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
# Tekrarlanabilirlik için rasgele sayı üreteci ayarlaması
np.random.seed(23)
ns = np.linspace(0, 200, 1000)
# Kaynak matris
S = np.array([np.sin(ns * 1),
signal.sawtooth(ns * 1.9),
np.random.random(len(ns))]).T
# Karışık matris
A = np.array([[0.5, 1, 0.2],
[1, 0.5, 0.4],
[0.5, 0.8, 1]])
# Karışık sinyal matrisi
X = S.dot(A).T
# Çizim, kaynak ve sinyal
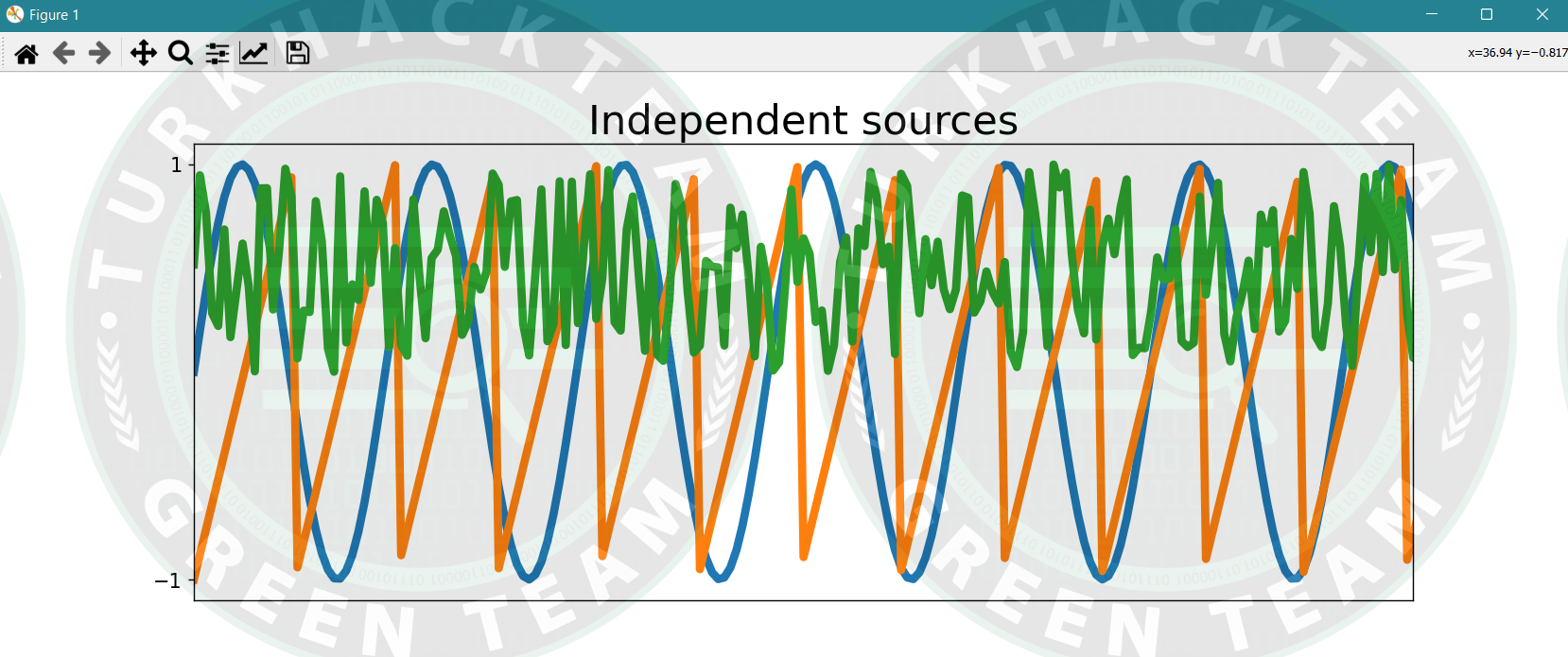
fig, ax = plt.subplots(1, 1, figsize=[18, 5])
ax.plot(ns, S, lw=5)
ax.set_xticks([])
ax.set_yticks([-1, 1])
ax.set_xlim(ns[0], ns[200])
ax.tick_params(labelsize=12)
ax.set_title('Independent sources', fontsize=25)
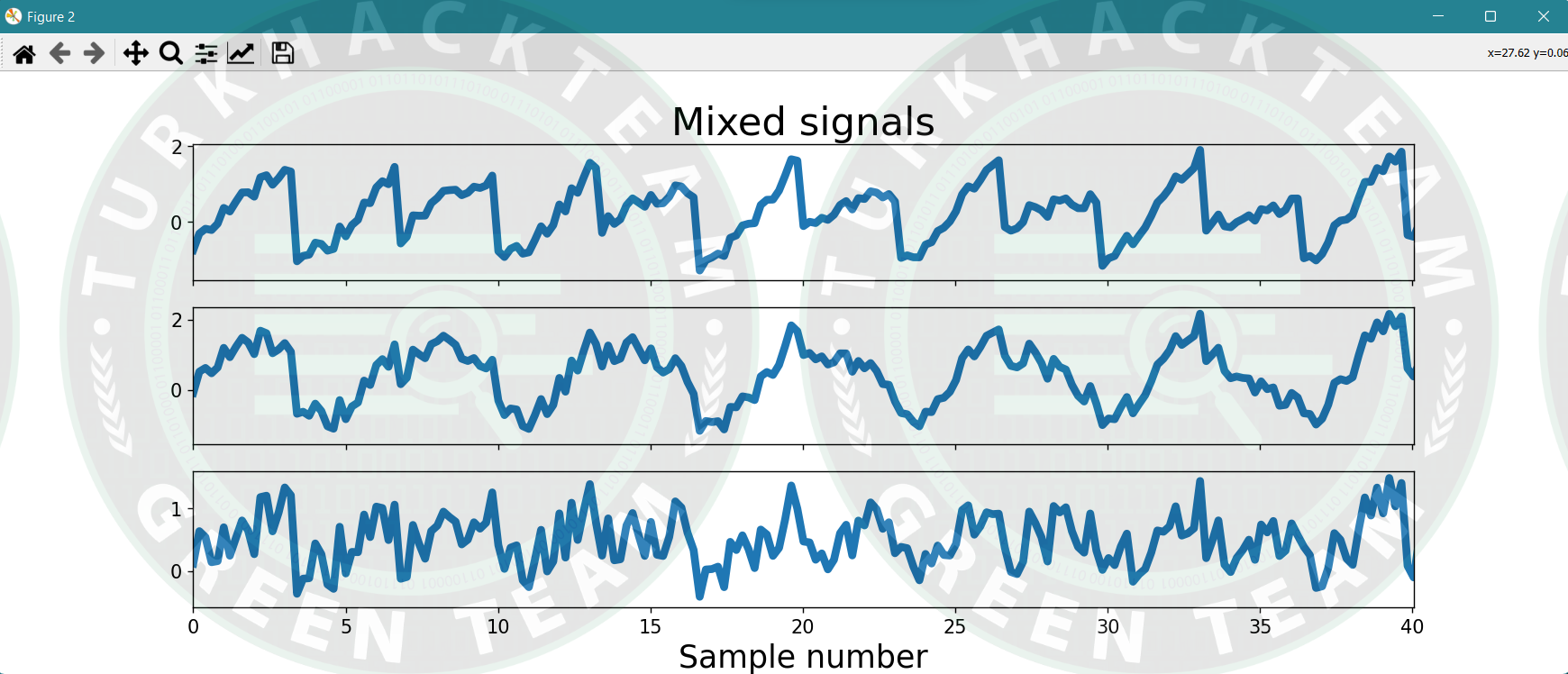
fig, ax = plt.subplots(3, 1, figsize=[18, 5], sharex=True)
ax[0].plot(ns, X[0], lw=5)
ax[0].set_title('Mixed signals', fontsize=25)
ax[0].tick_params(labelsize=12)
ax[1].plot(ns, X[1], lw=5)
ax[1].tick_params(labelsize=12)
ax[1].set_xlim(ns[0], ns[-1])
ax[2].plot(ns, X[2], lw=5)
ax[2].tick_params(labelsize=12)
ax[2].set_xlim(ns[0], ns[-1])
ax[2].set_xlabel('Sample number', fontsize=20)
ax[2].set_xlim(ns[0], ns[200])
plt.show()
"""
# gaussian kullanımı
s1 = np.random.rand(1000)
s2 = np.random.rand(1000)
s = np.array(([s1, s2]))
s1n = np.random.normal(size=1000)
s2n = np.random.normal(size=1000)
sn = np.array(([s1n, s2n]))
A = np.array(([0.96, -0.28],[0.28, 0.96]))
mixedSignals = s.T.dot(A)
mixedSignalsN = sn.T.dot(A)
fig, ax = plt.subplots(2, 2, figsize=[18, 10])
ax[0][0].scatter(s[0], s[1])
ax[0][0].tick_params(labelsize=12)
ax[0][0].set_title('Sources (non-Gaussian)', fontsize=25)
ax[0][0].set_xlim([-0.25, 1.5])
ax[0][0].set_xticks([])
ax[0][1].scatter(sn[0], sn[1])
ax[0][1].tick_params(labelsize=12)
ax[0][1].set_title('Sources (Gaussian)', fontsize=25)
ax[0][1].set_xlim([-4, 4])
ax[0][1].set_xticks([])
ax[0][1].set_yticks([])
ax[1][0].scatter(mixedSignals.T[0], mixedSignals.T[1])
ax[1][0].tick_params(labelsize=12)
ax[1][0].set_title('Mixed signals (non-Gaussian sources)', fontsize=25)
ax[1][0].set_xlim([-0.25, 1.5])
ax[1][1].scatter(mixedSignalsN.T[0], mixedSignalsN.T[1])
ax[1][1].tick_params(labelsize=12)
ax[1][1].set_title('Mixed signals (Gaussian sources)', fontsize=25)
ax[1][1].set_xlim([-4, 4])
ax[1][1].set_yticks([])
plt.show()"""Çıktı;
Kümeleme (Clustering) algoritmaları tanıdık ve örnekler ile mantığı anladık. Şimdi ise bir diğer Denetimsiz (Unsupervised) öğrenme tekniği olan İlişkilendirme (Association) algoritmalarına bakalım.

İlişkilendirme kurallarını (Association rules) üç farklı tipte inceleyebiliriz:
1. Apriori
2. Eclat
3. F-P Growth Algorithm
Dilerseniz başlayalım...

Apriori Algoritması; Bu algoritma, birliktelik kuralları oluşturmak için sık veri kümeleri kullanır. İşlemleri içeren veritabanları üzerinde çalışmak için tasarlanmıştır. Bu algoritma, öğe kümesini verimli bir şekilde hesaplamak için bir “Width-first Search” and “Hash Tree” kullanır.
Ağırlıklı olarak “Market Basket Analysis” için kullanılır ve birlikte alınabilecek ürünlerin tahminine yardımcı olur. Sağlık alanında da hastalar için ilaç reaksiyonlarını bulmak için kullanılabilir.
Formül;

Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import pandas as pd
from mlxtend.frequent_patterns import apriori,association_rules
# Veri setinin ayarlanması
data = pd.read_excel('Online_Retail.xlsx')
#data.head()
# Kolonlara bakış
#print(data.columns)
# Farklı işlem bölgelerini keşfetme
#data.Country.unique()
# Açıklamada ki fazladan boşlukların çıkarılması
data['Description'] = data['Description'].str.strip()
# Herhangi bir fatura numarası olmadan satırları bırakma
data.dropna(axis = 0, subset =['InvoiceNo'], inplace = True)
data['InvoiceNo'] = data['InvoiceNo'].astype('str')
# Kredi ile yapılan tüm işlemlerin iptal edilmesi
data = data[~data['InvoiceNo'].str.contains('C')]
# Fransa'da yapılan işlemler
basket_France = (data[data['Country'] =="France"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Birleşik Krallık'ta yapılan işlemler
basket_UK = (data[data['Country'] =="United Kingdom"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Portekiz'de yapılan işlemler
basket_Por = (data[data['Country'] =="Portugal"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# İsveç'te'de yapılan işlemler
basket_Sweden = (data[data['Country'] =="Sweden"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Verileri uygun hale getirmek için hot_encode işlevini tanımlama
# ilgili kütüphaneler için
def hot_encode(x):
if(x<= 0):
return 0
if(x>= 1):
return 1
# Veri kümelerini kodlama
basket_encoded = basket_France.applymap(hot_encode)
basket_France = basket_encoded
basket_encoded = basket_UK.applymap(hot_encode)
basket_UK = basket_encoded
basket_encoded = basket_Por.applymap(hot_encode)
basket_Por = basket_encoded
basket_encoded = basket_Sweden.applymap(hot_encode)
basket_Sweden = basket_encoded
# Modeli oluşturmak
frq_items = apriori(basket_France, min_support = 0.05, use_colnames = True)
# Association_rule kurallarını bir veri çerçevesinde toplama
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())Çıktı;
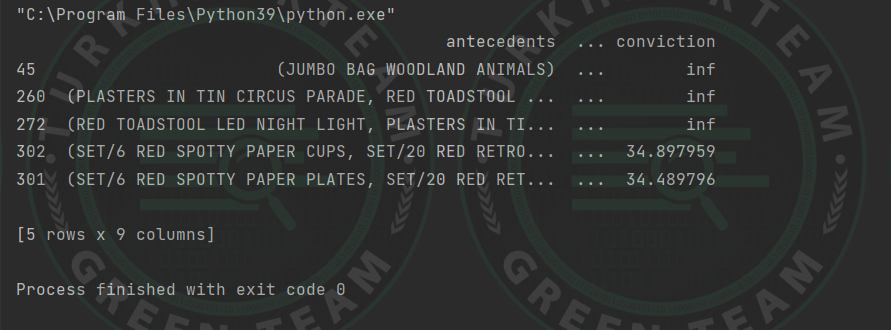

Eclat Algoritması; Eclat algoritması, “Equivalence Class Conversion (Denklik Sınıfı Dönüşümü)” anlamına gelir.
Bu algoritma, bir işlem veritabanında sık görülen öğe kümelerini bulmak için derinlik öncelikli arama tekniğini kullanır.
“Apriori Algoritmasına” göre daha hızlı yürütme gerçekleştirir.
Formül;
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import pandas as pd
from apyori import apriori
# Data setini ayarlama
data = pd.read_csv('Market_Basket_Optimisation.csv', header = None)
# işlemleri depolamak için boş bir liste oluşturun
transact_list = []
for i in range(0, 7501):
transact_list.append([str(data.values[i,j]) for j in range(0, 20)])
# Kural oluşturma
rules = apriori(transactions = transact_list, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2, max_length = 2)
# apriori modelinden gelen sonuçların listesi
rslt = list(rules)
# çıktıyı düzenleme işlevi
def inspect(rslt):
left_handSide = [tuple(result[2][0][0])[0] for result in rslt]
right_handSide = [tuple(result[2][0][1])[0] for result in rslt]
supports = [result[1] for result in rslt]
# yukarıdaki üç listeyi birlikte sıkıştırın
return list(zip(left_handSide, right_handSide, supports))
# Pandas data çerçevesini ayarlama
rslt_DataFrame = pd.DataFrame(inspect(rslt), columns=['Product 1', 'Product 2', 'Support'])
a=rslt_DataFrame.nlargest(n = 7, columns = 'Support')
print(a)Çıktı;
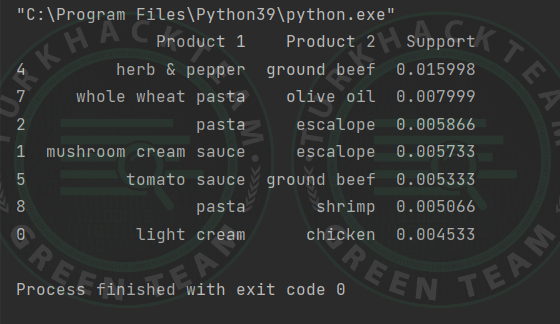
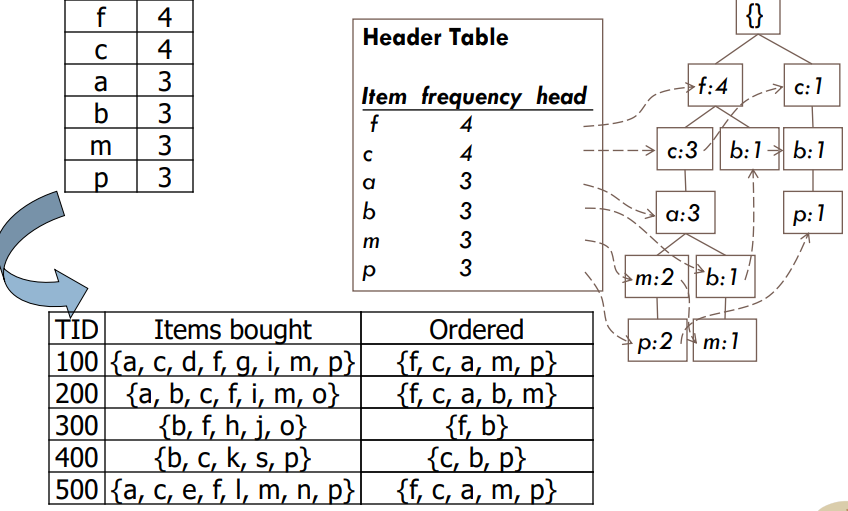
F-P Büyüme Algoritması; F-P büyüme algoritması “Frequent Pattern (Sık model)” anlamına gelir ve “Apriori Algoritmasının” geliştirilmiş versiyonudur.
Veritabanını, sık görülen bir desen veya ağaç olarak bilinen bir ağaç yapısı biçiminde temsil eder.
Bu sık kullanılan ağacın amacı, en sık görülen kalıpları çıkarmaktır.
Formül;
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import pandas as pd
import plotly.express as px
import numpy as np
from mlxtend.frequent_patterns import fpgrowth
from mlxtend.frequent_patterns import association_rules
# Data setini ayarlama
dataset = pd.read_csv("Market_Basket_Optimisation.csv")
print(dataset.shape)
# İşlemlerin tüm öğelerini Numpy dizisinde toplama
transaction = []
for i in range(0, dataset.shape[0]):
for j in range(0, dataset.shape[1]):
transaction.append(dataset.values[i,j])
# numpy dizisine dönüştürme
transaction = np.array(transaction)
print(transaction)
# Pandas data çerçevesine dönüştürme
df = pd.DataFrame(transaction, columns=["items"])
df["incident_count"] = 1
# NaN itemleri data setinden çıkarma
indexNames = df[df['items'] == "nan" ].index
df.drop(indexNames , inplace=True)
# Görselleştirmeler için yeni bir uygun Pandas DataFrame Yapımı
df_table = df.groupby("items").sum().sort_values("incident_count", ascending=False).reset_index()
# İlk görselleştirmeler
df_table.head(5).style.background_gradient(cmap='Blues')
df_table["all"] = "Top 50 items"
# Plotly kullanarak ağaç haritası oluşturma
fig = px.treemap(df_table.head(50), path=['all', "items"], values='incident_count',
color=df_table["incident_count"].head(50), hover_data=['items'],
color_continuous_scale='Blues',
)
# ploting the treemap
#fig.show()
# Fp-growth algoritmasını çalıştırma
res=fpgrowth(dataset,min_support=0.05, use_colnames=True)
# printing top 10
res.head(10)
# Asssociation_rules oluşturma
res=association_rules(res, metric="lift", min_threshold=1)
# printing association rules
print(res)Çıktı;
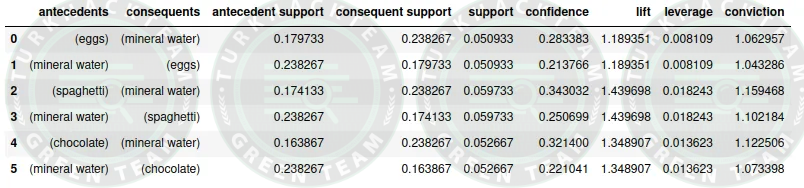
Avantaj & Dezavantaj
Denetimsiz öğrenmenin bazı avantajları şunlardır;
Kümeleme, veri kümesini benzerliklerine göre otomatik olarak gruplara ayırır
Denetimsiz öğrenme, denetimli öğrenmeye kıyasla daha karmaşık görevler için kullanılır. Çünkü denetimsiz öğrenmede etiketlenmiş girdi verileri elde bulunmaz.
Etiketli verilere kıyasla etiketlenmemiş verileri almak daha kolay olduğu için denetimsiz öğrenme tercih edilir.
Anormallik algılama, veri kümenizdeki olağandışı veri noktalarını keşfedebilir. Hileli işlemleri bulmak için kullanışlıdır.

Denetimsiz öğrenmenin bazı dezavantajları şunlardır;
Denetimsiz öğrenme, karşılık gelen çıktıya sahip olmadığı için denetimli öğrenmeye göre normalde daha zordur.
Veri sıralama konusunda kesin bilgi alınamaz ve denetimsiz öğrenmede kullanılan veriler etiketlendiği ve bilinmediği için çıktısı bilinmemektedir.
Denetimsiz öğrenme algoritmasının sonucu, girdi verileri etiketlenmediğinden ve algoritmalar kesin çıktıyı önceden bilmediğinden daha az doğru olabilir.
Spektral sınıflar her zaman bilgi sınıflarına karşılık gelmeyebilir.
Kullanıcının bu sınıflandırmayı takip eden sınıfları yorumlamak ve etiketlemek için zaman harcaması gerekebilir.
Sınıfların spektral özellikleri de zamanla değişebilir. Bu nedenle bir görüntüden diğerine geçerken aynı sınıf bilgisine sahip olunamayabilir.
Supervised VS Unsupervised
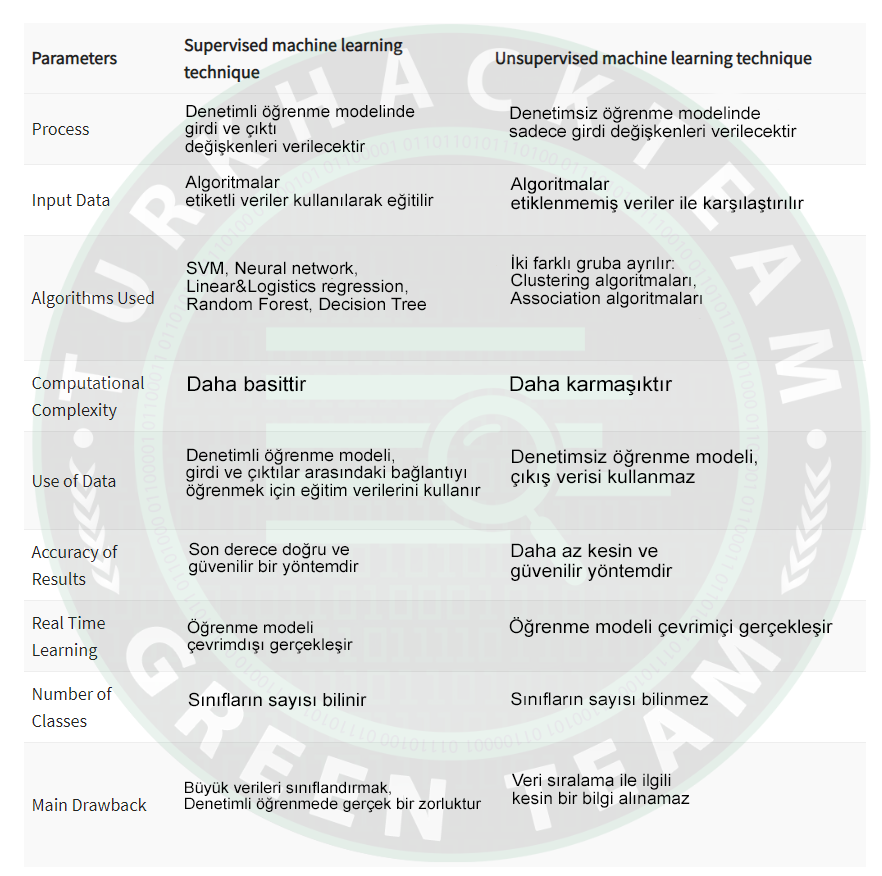
Son olarak kodlarda kullandığım ".cvs" uzantılı dataset'leri buraya bırakıyorum. Sizlerde farklı veriler ile farklı grafikler yakalayabilirsiniz. Kodları mutlaka denemenizi öneririm
")
Dosyalar --> Files | VT --> 1, 2, 3, 4
^
|
|
|
|
v
|
|
|
|
v
Değerli dostlarım, güzel kardeşlerim;
Bu makalemde kısaca "Makine öğrenmesi modelleri" konusuna değindim.
Ardından "En popüler algoritmalar" konusunda örnekler yaptık.
Kaynak niteliğinde bu forumda kalması temennisi ile diyerek sözlerimi bitiriyorum.
Sağlıcakla kalın.


