



NLP için veri toplama ilk adımdır. Bu nedenle, verilerin scraping yoluyla nasıl elde edileceğini açıklamak daha heyecan verici ve öğretici. Tanımlayacağımız scraper, müşteri için, tavsiye algoritması'nı Proof of concepts olarak geliştirdik. Bu web scraper'in temel prensiplerini burada tanımlayacağız. Web crawler genellikle, arama yaparken uygun web sitelerini olabildiğince hızlı bir şekilde tanımlanması için ve web sitelerini dizine eklemek için Google veya Bing gibi arama motorları ile bağlantılı olarak bilinir. Bunu yapmak için, bir web sitesinin bağlantılar aracılığıyla içeriklerini analiz edin ve bir dizine (Inverted-Index) kaydedin. Aynı prensip, web scraping, yani bilginin çıkarılması için de kullanılabilir. Web sitesi özel bir API (Twitter gibi) sunuyorsa, elbette ilk olarak bunu kullanırız. Web siteleri, belirli içeriğe erişimi engellemek için robots.txt veya me-ta verileri kullanma seçeneğine de sahiptir. Web scraper kodlarken bu bilgilere daima uyulmalıdır. Kullandığımız Scrapy kütüphanesi bu bilgilere standart olarak uymaktadır ve ayrıca ziyaret edilen web sitesindeki yükü azaltmak için bizlere AutoThrottle adlı bir fonksiyon sunmaktadır.
Web Scraper'ımız için Scrapy kullanacağız. Scrapy, Web Scraper yazılımımız için Python'daki en popüler ve güçlü frameworkler'den biri olan open-source bir projedir. CSS veya XPath'in referans elemanlarına aşina iseniz Scrapy, sizin için verileri çıkarmayı ciddi derecede kolaylaştıracaktır. Temel olarak, Web Scraping ile iki görev gerçekleştirilmelidir: İlk olarak, alakalı sayfaların nasıl bulunacağını ve nasıl yürütüleceğini belirlemek. Öte yandan, tek tek sayfaların içeriğinin nasıl işlenmesi ve çıkarılması gerektiğini tanımlamanız gerekir.
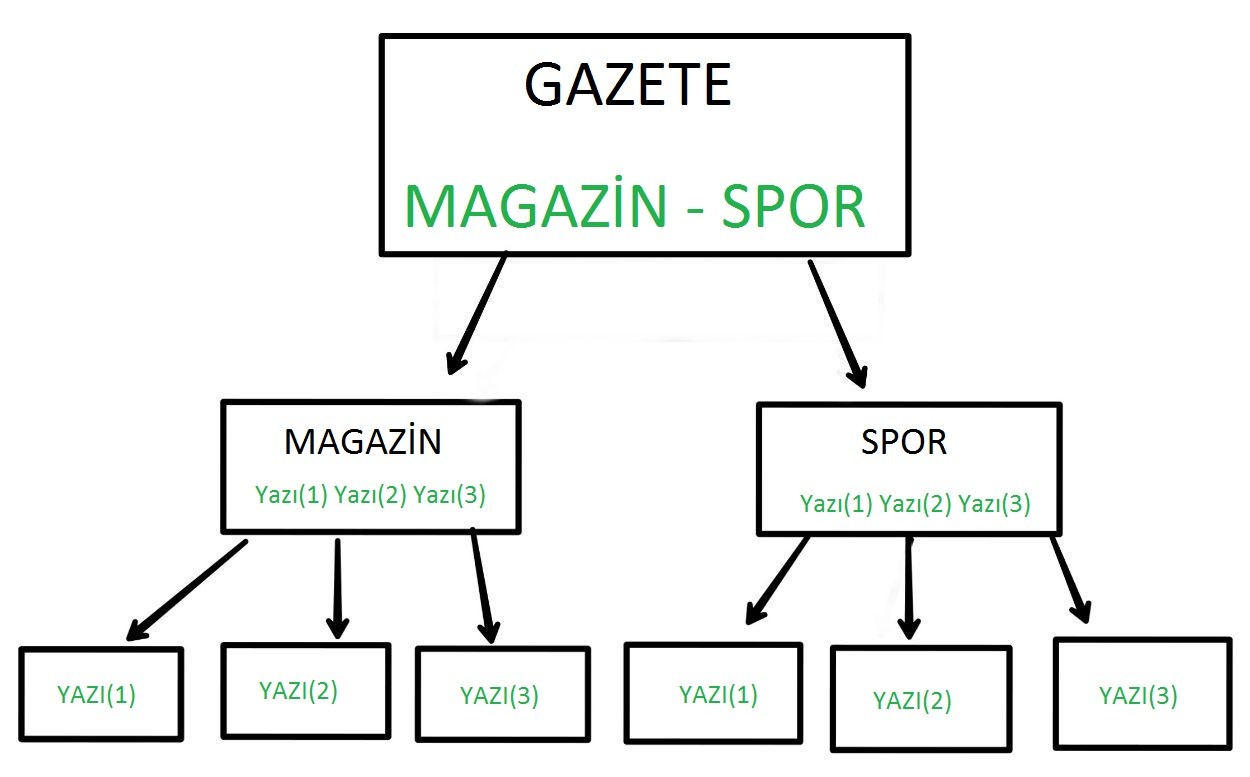
Gördüğünüz gibi, scraping yapmak istediğimiz makaleler farklı bölümlere (magazin, spor) ayrılıyor ve bunlar ana sayfaya bağlanıyor. Tüm makalelere ulaşmak için önce başlangıç bölümlerini ziyaret ederek bölümlerin bağlantılarını açabiliriz ve bağlantıları izlersek, bölüm sayfalarından makalelere giden bağlantıları çıkarabilir ve daha sonra ilgili makalelerden ilgili bilgileri işleyebiliriz.
Scrapy yukarıdaki saydığımız işlemler için spider'lar kullanır. Spider'lar, bir web sitesinin nasıl çalıştırılması ve içeriğin nasıl çıkarılması gerektiğini tanımladığınız Python class'ından başka bir şey değildir. Bu amaçla, Scrapy sunucuya normal bir web tarayıcısı gibi bir HTTP-Request gönderir ve HTTP-Response döner böylece web sitesinin HTML kodunu Python objesi olarak alır. Daha sonra Scrapy, web sitesinin HTML kodundan belirli HTML öğelerini seçmek ve böylece ilgili bilgileri çıkarmak için hem XPath hem de CSS seçicilerinin kullanımını sunar.
Bir geliştirici olarak, ilgili HTML öğelerini (örneğin, izlenmesi gereken bir alt sayfaya bağlantı veya bir gazete makalesinin tam metnini içeren öğeyi) tanımlamak için önce tek tek sayfaların kaynak metnine bakmanız gerekir. Örneğin, bir alt sayfaya ilgili bağlantıyı işlemek istiyorsanız, en düşük seviyeye ulaşıncaya kadar bir HTTP isteği vb. yollar ile sorgulamamız lazım. Infinite loop oluşturmamaya dikkat etmeniz gerekir (örneğin, tek tek sayfalar birbirine bağlanıyorsa), ancak Scrapy daha önce ziyaret edilmiş olan web sitelerine olan talepleri otomatik olarak filtreliyor.
İlk adımda, scrapy ile spider'imizi tanımlayalım. ArticleScraper;
Spider ile ilgili prensip şu şekildedir: Spider başlatıldığında, önce start_urls içinde belirtilen URL'lere bir HTTP-Request gönderir. Parseleme methodu HTTP-Response'u parametre olarak çağrır. Parseleme methodunda HTTP-Response'un nasıl işleneceğini tanımlanır. Çağrıyı, artık bir CSS-Selector'ü(ul.RessortNavigation> li> a :: attr (href)) kullanarak bölüm URL'lerini yanıttan parseleyen parse_start_page yöntemimize delege ediyoruz, ardından bu URL'lerin her biri için yeni bir HTTP-Request gönderip ve parse_ressort_page işlevi Callback olarak çağırıyoruz.
Kullanılan Selector ile, CSS-Selector'e bağlı olan String :: attr (href) 'nin standart bir CSS3-Selector'ü değil, Scrapy için spesifiktir . Bu, href özelliğinin değerini <a href="http://www.examplenewspaper.com/val"> entina</a> 'deki gibi okumayı mümkün kılar. Bu, varsayılan olarak mümkün olan XPath-Selector'leri için önemli bir farktır. CSS, birçok geliştirici için daha yaygın bir varyant olacaktır, ancak XPath, aşağıdaki örneklerde görülebileceği gibi daha güçlüdür.
parse_ressort_page methodu, bölüm URL'leri yerine makale URL'lerinin okunması ve parse_article_page'in callback olarak atanması dışında parse_start_page ile aynı prensipte çalışır. parse_article_page'de gazete makalelerinin içeriği okunur (get_article_data Methodu) ve kaydedilir (save_local Methodu).
get_article_data methodu önce tek tek makalelerin tüm paragraflarını ve başlıklarını seçer ve çıkarır, ardından bunları tüm rahatsız edici HTML etiketlerinden temizler (bkz. W3lib.html.remove_tags işlevi). <p>Valentina O.</p> iken "Valentina O." 'ya çevirir. Makaleler daha sonra bir Python Dictionary'e kaydedilir. Makalelerimizi Dictionary olarak kaydettiğimizden, bunları JSON olarak dışa aktarmak en mantıklısıdır. Bu işlemimizi, save_local yöntemimiz ile yapıyoruz;
Örnek bi' data aşşağıdaki gibi olur;
Python ile Natural Language Processing hakkındaki serinin ilk bölümü buydu. Python veya Scrapy ile güncel makaleleri günlük bir gazeteden otomatik olarak çıkarmanın ve daha sonraki işlemler için kaydetmenin ne kadar kolay olduğunu gördük.
Web Scraper'ımız için Scrapy kullanacağız. Scrapy, Web Scraper yazılımımız için Python'daki en popüler ve güçlü frameworkler'den biri olan open-source bir projedir. CSS veya XPath'in referans elemanlarına aşina iseniz Scrapy, sizin için verileri çıkarmayı ciddi derecede kolaylaştıracaktır. Temel olarak, Web Scraping ile iki görev gerçekleştirilmelidir: İlk olarak, alakalı sayfaların nasıl bulunacağını ve nasıl yürütüleceğini belirlemek. Öte yandan, tek tek sayfaların içeriğinin nasıl işlenmesi ve çıkarılması gerektiğini tanımlamanız gerekir.
Gördüğünüz gibi, scraping yapmak istediğimiz makaleler farklı bölümlere (magazin, spor) ayrılıyor ve bunlar ana sayfaya bağlanıyor. Tüm makalelere ulaşmak için önce başlangıç bölümlerini ziyaret ederek bölümlerin bağlantılarını açabiliriz ve bağlantıları izlersek, bölüm sayfalarından makalelere giden bağlantıları çıkarabilir ve daha sonra ilgili makalelerden ilgili bilgileri işleyebiliriz.
Scrapy yukarıdaki saydığımız işlemler için spider'lar kullanır. Spider'lar, bir web sitesinin nasıl çalıştırılması ve içeriğin nasıl çıkarılması gerektiğini tanımladığınız Python class'ından başka bir şey değildir. Bu amaçla, Scrapy sunucuya normal bir web tarayıcısı gibi bir HTTP-Request gönderir ve HTTP-Response döner böylece web sitesinin HTML kodunu Python objesi olarak alır. Daha sonra Scrapy, web sitesinin HTML kodundan belirli HTML öğelerini seçmek ve böylece ilgili bilgileri çıkarmak için hem XPath hem de CSS seçicilerinin kullanımını sunar.
Bir geliştirici olarak, ilgili HTML öğelerini (örneğin, izlenmesi gereken bir alt sayfaya bağlantı veya bir gazete makalesinin tam metnini içeren öğeyi) tanımlamak için önce tek tek sayfaların kaynak metnine bakmanız gerekir. Örneğin, bir alt sayfaya ilgili bağlantıyı işlemek istiyorsanız, en düşük seviyeye ulaşıncaya kadar bir HTTP isteği vb. yollar ile sorgulamamız lazım. Infinite loop oluşturmamaya dikkat etmeniz gerekir (örneğin, tek tek sayfalar birbirine bağlanıyorsa), ancak Scrapy daha önce ziyaret edilmiş olan web sitelerine olan talepleri otomatik olarak filtreliyor.
İlk adımda, scrapy ile spider'imizi tanımlayalım. ArticleScraper;
Kod:
def parse_start_page(self, response):
ressort_urls = response.css('ul.RessortNavi>li>a::attr(href)').extract()
for url in ressort_urls:
yield scrapy.Request(url, callback=self.parse_ressort_page)
def parse_ressort_page(self, response):
all_urls = response.css('a.TeaserHeadLink::attr(href)').extract()
article_urls = [urljoin(self.start_urls[0], relative_url)
for relative_url in all_urls
if relative_url.endswith('.html')]
for url in article_urls:
yield scrapy.Request(url, callback=self.parse_article_page)
def parse_article_page(self, response):
article = self.get_article_data(response)
self.save_local(article)Spider ile ilgili prensip şu şekildedir: Spider başlatıldığında, önce start_urls içinde belirtilen URL'lere bir HTTP-Request gönderir. Parseleme methodu HTTP-Response'u parametre olarak çağrır. Parseleme methodunda HTTP-Response'un nasıl işleneceğini tanımlanır. Çağrıyı, artık bir CSS-Selector'ü(ul.RessortNavigation> li> a :: attr (href)) kullanarak bölüm URL'lerini yanıttan parseleyen parse_start_page yöntemimize delege ediyoruz, ardından bu URL'lerin her biri için yeni bir HTTP-Request gönderip ve parse_ressort_page işlevi Callback olarak çağırıyoruz.
Kullanılan Selector ile, CSS-Selector'e bağlı olan String :: attr (href) 'nin standart bir CSS3-Selector'ü değil, Scrapy için spesifiktir . Bu, href özelliğinin değerini <a href="http://www.examplenewspaper.com/val"> entina</a> 'deki gibi okumayı mümkün kılar. Bu, varsayılan olarak mümkün olan XPath-Selector'leri için önemli bir farktır. CSS, birçok geliştirici için daha yaygın bir varyant olacaktır, ancak XPath, aşağıdaki örneklerde görülebileceği gibi daha güçlüdür.
parse_ressort_page methodu, bölüm URL'leri yerine makale URL'lerinin okunması ve parse_article_page'in callback olarak atanması dışında parse_start_page ile aynı prensipte çalışır. parse_article_page'de gazete makalelerinin içeriği okunur (get_article_data Methodu) ve kaydedilir (save_local Methodu).
Kod:
def get_article_data(self, response):
base_selector = response.css('div#MyContent')
main_text_selector = base_selector.css('.MyArtikelText:first-child>div[class=""]')
section_headings = main_text_selector.css('h2:not([class])')
paragraphs = main_text_selector.xpath('./p[(not(@class) or @id="pageIndex_1") and not(span[@class="MediaLink"])]')
image_captions = main_text_selector.css("span[class=Bildunterschrift]")
article_data = collections.OrderedDict([
('section_headings', section_headings),
('paragraphs', paragraphs),
('image_captions', image_captions)
])
for key, selector in article_data.items():
texts = [w3lib.html.remove_tags(text).strip() for text in selector.extract()]
texts = [item for item in texts if item is not None]
article_data[key] = texts
return article_dataget_article_data methodu önce tek tek makalelerin tüm paragraflarını ve başlıklarını seçer ve çıkarır, ardından bunları tüm rahatsız edici HTML etiketlerinden temizler (bkz. W3lib.html.remove_tags işlevi). <p>Valentina O.</p> iken "Valentina O." 'ya çevirir. Makaleler daha sonra bir Python Dictionary'e kaydedilir. Makalelerimizi Dictionary olarak kaydettiğimizden, bunları JSON olarak dışa aktarmak en mantıklısıdır. Bu işlemimizi, save_local yöntemimiz ile yapıyoruz;
Kod:
def save_local(self, article):
filename = article['ressort'][0] + ' ' + article['id'].replace('.', '') + '.json'
file_path = os.path.join('scraped_articles', filename)
with codecs.open(file_path, 'w', encoding='utf-8') as f:
json.dump(article, f, ensure_ascii=False, indent=2)Örnek bi' data aşşağıdaki gibi olur;
Kod:
{
"article_data": {
"section_headings": ["Valentina", "O.", "retard"],
"paragraphs": ["lorem ipsum dolor", "sit amet ", "consectetur adipiscing elit"]
},
"me-tadata": {
"url": "http://www.examplenewspaper.com/ressort/sport/valentina-gencler-birligi-12345",
"id": 12345,
"ressort": "Sport",
"date": "2020-02-19"
}
}Python ile Natural Language Processing hakkındaki serinin ilk bölümü buydu. Python veya Scrapy ile güncel makaleleri günlük bir gazeteden otomatik olarak çıkarmanın ve daha sonraki işlemler için kaydetmenin ne kadar kolay olduğunu gördük.


