

Merhaba arkadaşlar
- Bu paylaşımımda, Python kullanarak CNN Türk'ün RSS beslemesinden haberleri nasıl çekeceğinizi ve bu haberleri dosyalara nasıl kaydedeceğinizi anlatan bir kodu sizlerle paylaşıyorum.
- Bu kod sayesinde, CNN Türk'teki son haberleri otomatik olarak çekebilir ve her bir haberi ayrı bir dosyada saklayabilirsiniz.
- Özellikle veri toplama ve analiz projelerinde kullanabileceğiniz bu kod,
- BeautifulSoup ve feedparser kütüphanelerini kullanarak basit ama etkili bir çözüm sunuyor.
- Kodlar Aşşağıda Yer Alıyor.
Örnek Resim:
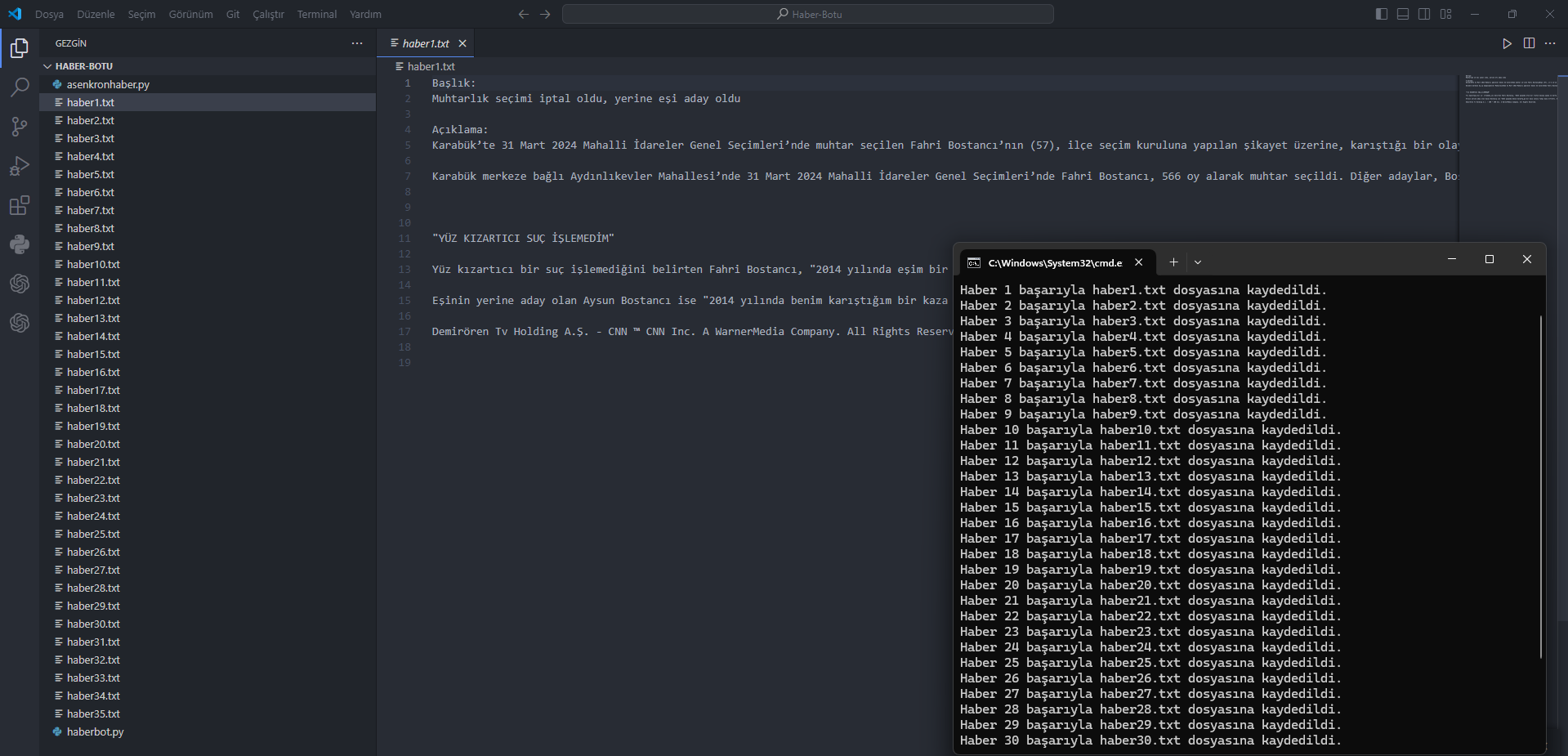
Python:
import requests
from bs4 import BeautifulSoup
import feedparser
# RSS besleme URL'si
feed_url = "https://www.cnnturk.com/feed/rss/news"
# RSS beslemesini çek
feed = feedparser.parse(feed_url)
# Daha önce alınan haberleri takip etmek için bir set kullanın
previously_seen_links = set()
# Her bir haber öğesini döngü ile gezin
for i, item in enumerate(feed.entries, start=1):
link = item.link # Haber öğesinin bağlantısı (link)
title = item.title # Haber öğesinin başlığı (title)
description = item.description # Haber öğesinin açıklaması (description)
# Aynı link daha önce alınmadıysa işlem yap
if link not in previously_seen_links:
previously_seen_links.add(link)
# Haber sayfasına git
response = requests.get(link)
# Sayfanın içeriğini parçala
soup = BeautifulSoup(response.text, 'html.parser')
# Tüm <p> etiketlerini bulun
paragraphs = soup.find_all("p")
# Her bir haberin metnini ayrı bir dosyaya yazdırın
with open(f"haber{i}.txt", "w", encoding="utf-8") as file:
file.write(f"Başlık:\n{title}\n\n") # Başlığı ekleyin
file.write(f"Açıklama:\n{description}\n\n") # Açıklamayı ekleyin
for paragraph in paragraphs:
paragraph_text = paragraph.get_text()
file.write(paragraph_text)
file.write("\n\n") # Paragraf sonlarına bir boş satır ekleyin
print(f"Haber {i} başarıyla haber{i}.txt dosyasına kaydedildi.")
else:
print(f"Haber {i} zaten alındı, atlandı.")