



Herkese merhaba bu konumda Python kullanarak profesyonel bir web scraping aracı nasıl oluşturulur adım adım anlatacağım.Projemiz için gerekli dosya yapısı ve her bir bileşenin nasıl çalıştığını açıklayarak ilerleyeceğiz.
İlk olarak dosya yapısının nasıl olacağının iskeletini oluşturalım ki karışıklık olmasın.Burda oluşturduğumuz araçların dosya yapısını anlatmamın sebebi çoğu projeleri Github'a repo etmemizdendir o sebeple dosya yapılarına dikkat etmek gerkiyor.
Projemizde kullanmamız gereken Python kütüphanelerini yükleyelim. requests, BeautifulSoup, pandas ve selenium kütüphanelerine ihtiyacımız olacak. Aşağıdaki komutla bu kütüphaneleri yükleyebilirsiniz:
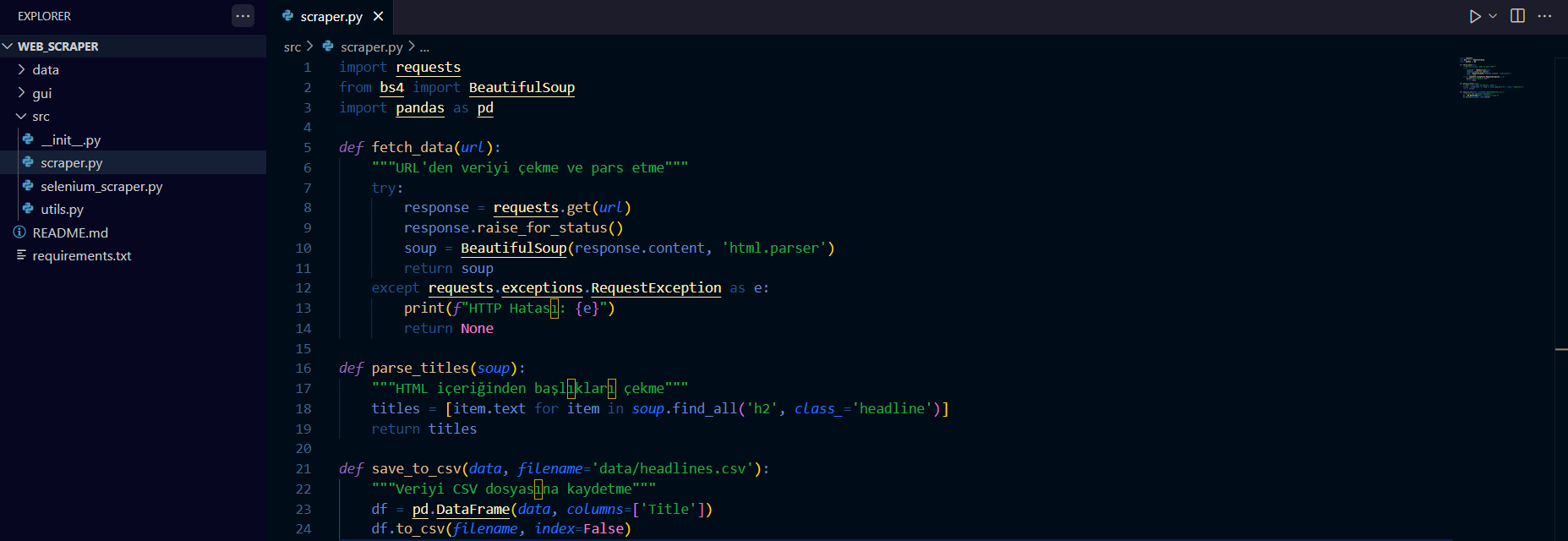
Şimdi kodlamaya başlayalım ilk olarak web scraping işlevlerini src/scraper.py dosyasında tanımlayacağız. Bu dosya web sayfalarından veri çekme ve bu verileri işleme işlevlerini içerir.
src/scraper.py:
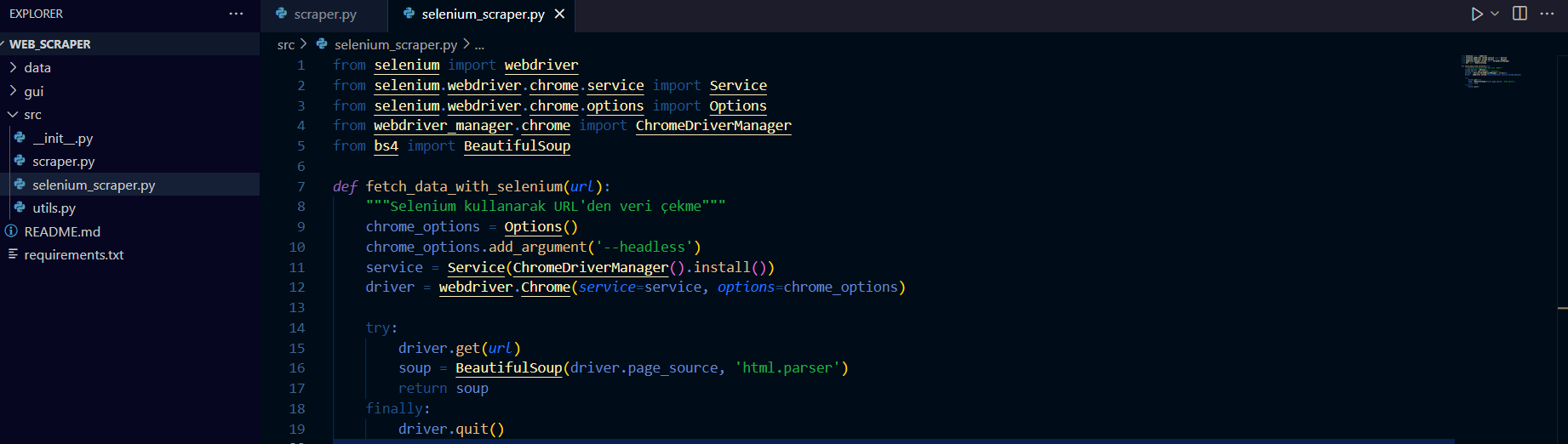
Daha sonra dinamik olarak yüklenen içerikleri işlemek için src/selenium_scraper.py dosyasını kodlayacağız. Dinamik içerik JavaScript ile yüklenen verileri içerecek.
src/selenium_scraper.py:
Hemen ardından hata yönetimi ve diğer yardımcı işlevler için src/utils.py dosyasını kodlayalım.
src/utils.py:

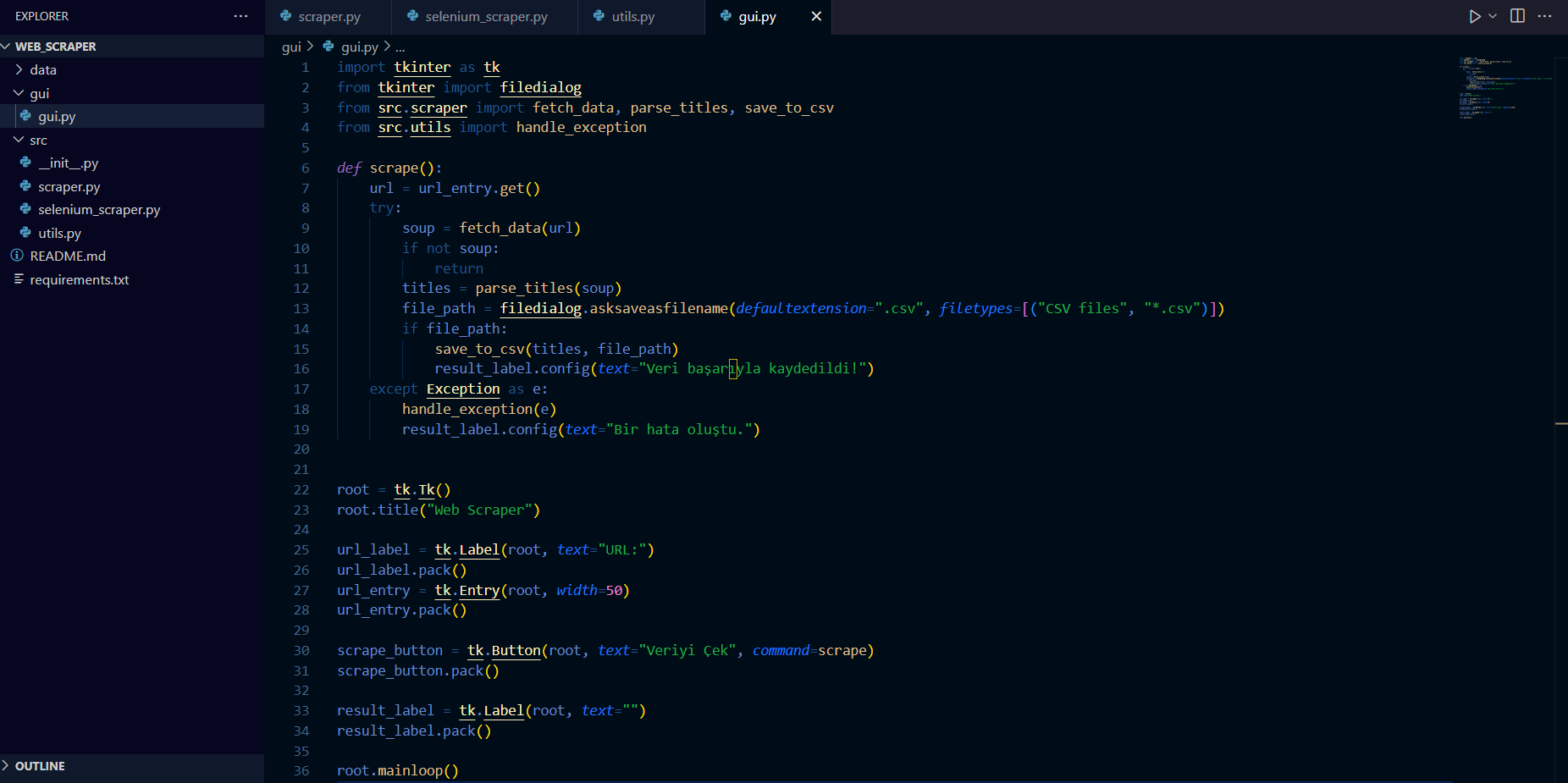
Şimdi Tkinter kullanarak basit kullanıcı arayüzü oluşturacağız. Bu arayüz kullanıcıların URLyi girmesine ve veriyi çekmesine olanak tanıyacak.
gui/gui.py:
Umarım bu tür araçların kodlanması süreçlerinde bu konum bir nebze yol gösterici olur okuduğunuz için teşekkürler.
İlk olarak dosya yapısının nasıl olacağının iskeletini oluşturalım ki karışıklık olmasın.Burda oluşturduğumuz araçların dosya yapısını anlatmamın sebebi çoğu projeleri Github'a repo etmemizdendir o sebeple dosya yapılarına dikkat etmek gerkiyor.
Kod:
web_scraper/
│
├── data/
│ └── headlines.csv # Çıktı dosyası
│
├── src/
│ ├── __init__.py # Paket başlangıç dosyası
│ ├── scraper.py # Web scraping işlevlerini içeren ana dosya
│ ├── selenium_scraper.py # Selenium kullanarak veri çekme işlevleri
│ └── utils.py # Yardımcı işlevler (hata yönetimi, vb.)
│
├── gui/
│ └── gui.py # Tkinter GUI dosyası
│
├── requirements.txt # Gerekli Python kütüphanelerini listeleyen dosya
└── README.md # Proje açıklaması ve kullanım talimatlarıProjemizde kullanmamız gereken Python kütüphanelerini yükleyelim. requests, BeautifulSoup, pandas ve selenium kütüphanelerine ihtiyacımız olacak. Aşağıdaki komutla bu kütüphaneleri yükleyebilirsiniz:
Python:
pip install requests beautifulsoup4 pandas selenium webdriver-managerŞimdi kodlamaya başlayalım ilk olarak web scraping işlevlerini src/scraper.py dosyasında tanımlayacağız. Bu dosya web sayfalarından veri çekme ve bu verileri işleme işlevlerini içerir.
src/scraper.py:
Python:
import requests
from bs4 import BeautifulSoup
import pandas as pd
def fetch_data(url):
"""URL'den veriyi çekme ve parse etme"""
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
return soup
except requests.exceptions.RequestException as e:
print(f"HTTP Hatası: {e}")
return None
def parse_titles(soup):
"""HTML içeriğinden başlıkları çekme"""
titles = [item.text for item in soup.find_all('h2', class_='headline')]
return titles
def save_to_csv(data, filename='data/headlines.csv'):
"""Veriyi CSV dosyasına kaydetme"""
df = pd.DataFrame(data, columns=['Title'])
df.to_csv(filename, index=False)Daha sonra dinamik olarak yüklenen içerikleri işlemek için src/selenium_scraper.py dosyasını kodlayacağız. Dinamik içerik JavaScript ile yüklenen verileri içerecek.
src/selenium_scraper.py:
Python:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
def fetch_data_with_selenium(url):
"""Selenium kullanarak URL'den veri çekme"""
chrome_options = Options()
chrome_options.add_argument('--headless')
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
try:
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
return soup
finally:
driver.quit()Hemen ardından hata yönetimi ve diğer yardımcı işlevler için src/utils.py dosyasını kodlayalım.
src/utils.py:
Python:
def handle_exception(e):
"""Hata mesajlarını işleme"""
print(f"Bir hata oluştu: {e}")Şimdi Tkinter kullanarak basit kullanıcı arayüzü oluşturacağız. Bu arayüz kullanıcıların URLyi girmesine ve veriyi çekmesine olanak tanıyacak.
gui/gui.py:
Python:
import tkinter as tk
from tkinter import filedialog
from src.scraper import fetch_data, parse_titles, save_to_csv
from src.utils import handle_exception
def scrape():
url = url_entry.get()
try:
soup = fetch_data(url)
if not soup:
return
titles = parse_titles(soup)
file_path = filedialog.asksaveasfilename(defaultextension=".csv", filetypes=[("CSV files", "*.csv")])
if file_path:
save_to_csv(titles, file_path)
result_label.config(text="Veri başarıyla kaydedildi!")
except Exception as e:
handle_exception(e)
result_label.config(text="Bir hata oluştu.")
root = tk.Tk()
root.title("Web Scraper")
url_label = tk.Label(root, text="URL:")
url_label.pack()
url_entry = tk.Entry(root, width=50)
url_entry.pack()
scrape_button = tk.Button(root, text="Veriyi Çek", command=scrape)
scrape_button.pack()
result_label = tk.Label(root, text="")
result_label.pack()
root.mainloop()Umarım bu tür araçların kodlanması süreçlerinde bu konum bir nebze yol gösterici olur okuduğunuz için teşekkürler.

