

- 23 Eyl 2016
- 2,001
- 11
Web scraping, projelerinizde kullanmak için veri bulmak için en önemli yöntemlerden biridir. Web scraping için normalde onlarca kütüphane olmasına rağmen bu 5'i en çok kullanılanlardır ve büyük ihtimalle bunlardan başka bir kütüphaneye ihtiyacınız olmayacaktır. Hatta bu 5'inin hepsini öğrenmenize bile gerek yok. Peki hangilerini ne için öğrenmelisiniz?
requests
requests'i tanımlamak için sloglanlarını kullanacağım, "İnsanlar için HTTP" (HTTP for Humans). requests ile kolayca HTTP istekleri gönderebiliriz ve dönen veriyi alabiliriz. Bu dönen veriyi ise sonradan parse edip istediğimiz veriye ulaşabiliriz.
requests ile bir istek göndermek bu kadar kolay. Daha fazla bilgi için:
Quickstart Requests 2.18.4 documéntation
https://www.turkhackteam.org/python/1448998-python-requests-modulu-kullanimi.html
BeautifulSoup
Verimiz elimizde, şimdi ne yapacağız? Onu parse edeceğiz. Bunu da BeautifulSoup ile yapacağız.
BeautifulSoup, diğer parserlara yavaş olsa bile oldukça kolaydır ve bu yavaşlığı parserı değiştirerek (yine BeautifulSoup'u kullanacağız ama farklı bir parser) giderebiliriz.
Ayrıca BeautifulSoup'un bir diğer avantajı da şifrelemeleri otomatik olarak algılamasıdır. Bu sayede özel karakterler içeren sayfalarda sorun yaşamazsınız.
Bir sayfadaki bütün resimleri bulan bir programı yapmak bu kadar kolay. Daha fazla bilgi için:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
lxml
lxml, iyi performanslı bir parsing kütüphanesidir. Diğer parsing kütüphanelerine göre daha özellikli ve hızlıdır.
XPath veya CSS biliyorsanız işiniz daha da kolaylaşacaktır ama bilmiyorsanız da öğrenmek sizi zorlamayacaktır. Daha fazla bilgi için:
lxml - Processing XML and HTML with Python
BeautifulSoup mu lxml mi?
Bu tamamen sizin tercihinize bağlıdır. Zaten iki kütüphane de birbirini destekliyor. Yani birine alışıp sonra değiştirmek isterseniz aynı kütüphaneyi diğerinin parserı ile de kullanabilirsiniz.
Sizin için en iyi olanı bulmak için ikisini de deneyip birini seçebilirsiniz.
Selenium
requests, çoğu zaman işimizi görse de her siteden veri çekemez. Bazı siteler verileri sunmak için JavaScript kullanır. Mesela, verinin yüklenmesi için aşağıya kaydırmanızı veya bir butona tıklamanızı isteyebilir.
Böyle siteler için Selenium kullanabiliriz. Selenium ile normal bir browser gibi davranabiliriz.
Daha fazla bilgi için:
https://selenium-python.readthedocs.io/
Scrapy
Artık web sitelerinden veri çekip bunları kullanabiliyoruz. Peki ya bundan daha fazlasına ihtiyaç duyarsak ne yapacağız? Eğer bir websitenin tamamını sistematik bir şekilde tarayan bir spider yapacaksak ne yapacağız? İşte burada Scrapy devreye giriyor. Aslında scrapy teknik olarak bir kütüphane bile değil, bir scraping frameworkü. Bu demektir ki istekleri yönetetbiliriz, kullanıcı oturumlarını koruyabiliriz, yönlendirmeleri takip edebiliriz.
Bu ayrıca demektir ki ayrı scraping kütüphanelerini de kullanabiliriz. Mesela Selenium kullanmamız gerekiyorsa bunu yapabiliriz.
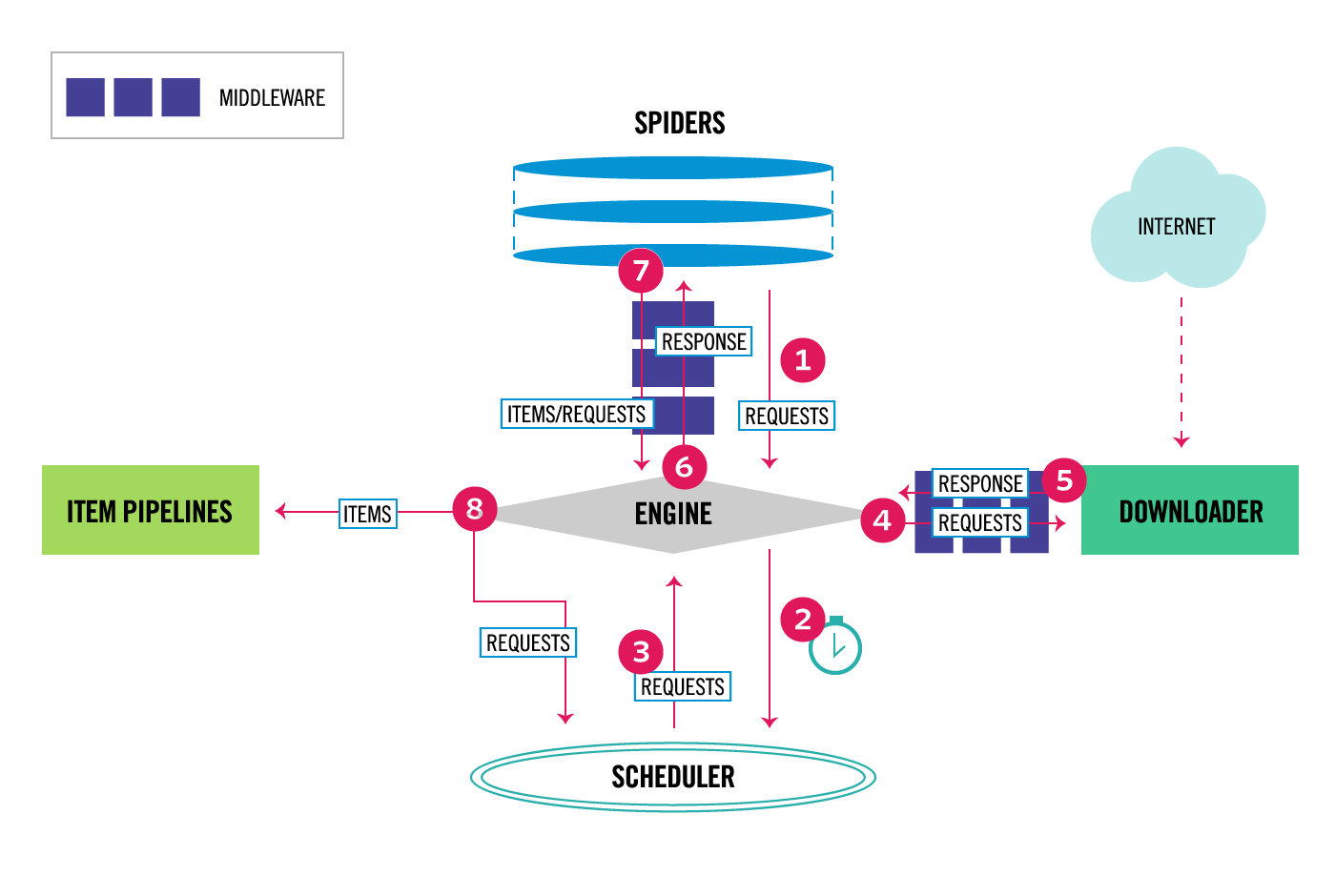
Scrapy mimarisi
Yani crawlerınızı yeniden kullanmanız, yeniden ayarlamanız gerekiyorsa bunu scrapy ile kolayca yapabilirsiniz. Daha fazla bilgi için:
https://scrapy.org/
- requests, birçok yerde işinize yarayacaktır. Bu yüzden web scraping ile uğraşmıyor olsanız bile bunu öğrenmeniz sizin için faydalı olacaktır.
- lxml veya BeautifulSoup'tan birini öğrenmeniz sizin işinizi oldukça kolaylaştıracaktır. Sizin yerinize HTML'i parse edecektir (çözümleyecektir, işleyecektir, ayrıştıracaktır; tam karşılığını bulamadım) bu kütüphaneler.
- Selenium, JavaScript gerektiren sitelerden veri çekmeniz gerekiyorsa işinize yarayacaktır fakat çoğu durumda JavaScript çalıştırmaya ihtiyacınız olmayacaktır.
- scrapy, birkaç sayfa ile uğraşmak yerine büyük bir web scraper yapacaksanız işinizi kolaylaştıracak ve sizi fazla kod yazmaktan kurtaracaktır.
requests
requests'i tanımlamak için sloglanlarını kullanacağım, "İnsanlar için HTTP" (HTTP for Humans). requests ile kolayca HTTP istekleri gönderebiliriz ve dönen veriyi alabiliriz. Bu dönen veriyi ise sonradan parse edip istediğimiz veriye ulaşabiliriz.
Kod:
[COLOR=#F1EEF1][COLOR=#3376CC]import[/COLOR] requests
sayfa = requests.get([COLOR=#A751F9]'https://www.turkhackteam.net/'[/COLOR]) [COLOR=#45EAF8]#https://www.turkhackteam.net adresine bir GET isteği gönderelim[/COLOR]
[COLOR=#52FDFF]print[/COLOR](sayfa.text) [COLOR=#45EAF8]#Dönen veriyi print edelim[/COLOR]
[/COLOR]requests ile bir istek göndermek bu kadar kolay. Daha fazla bilgi için:
Quickstart Requests 2.18.4 documéntation
https://www.turkhackteam.org/python/1448998-python-requests-modulu-kullanimi.html
BeautifulSoup
Verimiz elimizde, şimdi ne yapacağız? Onu parse edeceğiz. Bunu da BeautifulSoup ile yapacağız.
BeautifulSoup, diğer parserlara yavaş olsa bile oldukça kolaydır ve bu yavaşlığı parserı değiştirerek (yine BeautifulSoup'u kullanacağız ama farklı bir parser) giderebiliriz.
Ayrıca BeautifulSoup'un bir diğer avantajı da şifrelemeleri otomatik olarak algılamasıdır. Bu sayede özel karakterler içeren sayfalarda sorun yaşamazsınız.
Kod:
[COLOR=#F1EEF1][COLOR=#3376CC]from[/COLOR] bs4 [COLOR=#3376CC]import[/COLOR] BeautifulSoup
soup = BeautifulSoup(sayfa.text, [COLOR=#A751F9]'html.parser'[/COLOR]) [COLOR=#45EAF8]#Bir BeautifulSoup nesnesi oluşturalım [/COLOR]
soup.find_all([COLOR=#A751F9]'img'[/COLOR]) [COLOR=#45EAF8]#Bu sayfadaki bütün resimleri bulalım.[/COLOR]
[/COLOR]Bir sayfadaki bütün resimleri bulan bir programı yapmak bu kadar kolay. Daha fazla bilgi için:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
lxml
lxml, iyi performanslı bir parsing kütüphanesidir. Diğer parsing kütüphanelerine göre daha özellikli ve hızlıdır.
Kod:
[COLOR=#F1EEF1][COLOR=#3376CC]from[/COLOR] lxml [COLOR=#3376CC]import[/COLOR] html
tree = html.fromstring(sayfa.text) [COLOR=#45EAF8]#String veri ile bir lxml.html nesnesi oluşturalım[/COLOR]
tree.xpath([COLOR=#A751F9]'//img'[/COLOR]) [COLOR=#45EAF8]#XPath kullanarak bu sayfadaki bütün resimleri bulalım.[/COLOR]
[/COLOR]XPath veya CSS biliyorsanız işiniz daha da kolaylaşacaktır ama bilmiyorsanız da öğrenmek sizi zorlamayacaktır. Daha fazla bilgi için:
lxml - Processing XML and HTML with Python
BeautifulSoup mu lxml mi?
Bu tamamen sizin tercihinize bağlıdır. Zaten iki kütüphane de birbirini destekliyor. Yani birine alışıp sonra değiştirmek isterseniz aynı kütüphaneyi diğerinin parserı ile de kullanabilirsiniz.
Sizin için en iyi olanı bulmak için ikisini de deneyip birini seçebilirsiniz.
Selenium
requests, çoğu zaman işimizi görse de her siteden veri çekemez. Bazı siteler verileri sunmak için JavaScript kullanır. Mesela, verinin yüklenmesi için aşağıya kaydırmanızı veya bir butona tıklamanızı isteyebilir.
Böyle siteler için Selenium kullanabiliriz. Selenium ile normal bir browser gibi davranabiliriz.
Kod:
[COLOR=#F1EEF1][COLOR=#3376CC]from[/COLOR] selenium [COLOR=#3376CC]import[/COLOR] webdriver
driver = webdriver.Firefox() [COLOR=#45EAF8]#Firefox web driverı oluşturalım[/COLOR]
driver.get([COLOR=#A751F9]'https://www.turkhackteam.net/'[/COLOR]) [COLOR=#45EAF8]#https://www.turkhackteam.net adresine gidelim[/COLOR][/COLOR]Daha fazla bilgi için:
https://selenium-python.readthedocs.io/
Scrapy
Artık web sitelerinden veri çekip bunları kullanabiliyoruz. Peki ya bundan daha fazlasına ihtiyaç duyarsak ne yapacağız? Eğer bir websitenin tamamını sistematik bir şekilde tarayan bir spider yapacaksak ne yapacağız? İşte burada Scrapy devreye giriyor. Aslında scrapy teknik olarak bir kütüphane bile değil, bir scraping frameworkü. Bu demektir ki istekleri yönetetbiliriz, kullanıcı oturumlarını koruyabiliriz, yönlendirmeleri takip edebiliriz.
Bu ayrıca demektir ki ayrı scraping kütüphanelerini de kullanabiliriz. Mesela Selenium kullanmamız gerekiyorsa bunu yapabiliriz.
Scrapy mimarisi
Yani crawlerınızı yeniden kullanmanız, yeniden ayarlamanız gerekiyorsa bunu scrapy ile kolayca yapabilirsiniz. Daha fazla bilgi için:
https://scrapy.org/
Kaynak: elitedatascience.com
Son düzenleme:

