



Scikit-learn ile Destek Vektör Makineleri
Destek Vektör Makineleri(SVM) en çok kullanılan ve popüler makine öğrenmesi algoritmalarından biridir.
Destek Vektör Makineleri (SVM) lojistik regresyon (logistic regression) ve karar ağaçları (decision trees) gibi diğer sınıflandırıcılara göre daha yüksek doğruluk payına sahip bir sınıflandırma sunar. Bu algoritma daha çok doğrusal olmayan giriş boşluklarınını sınıflandırma tekniği ile bilinir. Yüz tanıma, alarm, e-posta sınıflandırma, haber siteleri için haber ,el yazısı ve gen sınıflandırma sistemleri gibi sistemlerde kullanılıyor.
Bu başlığımızda Python'da scikit-learn kullanacağız eğer bu paket hakkında daha çok şey öğrenmek istiyorsanız makine öğrenme kurslarıyla meşhur DataCamp'dan kurslara girebilirsiniz.
SVM heyecan verici bir algoritma olmasına rağmen konsept aslında oldukça basittir. Sınıflandırıcı, veri noktalarını en yüksek miktarda kenar boşluğuna sahip bir köprü kullanarak ayırır. Bu nedenle SVM sınıflandırıcıları ayrıca ayrımcı sınıflandırıcı (discriminative classifier) olarak da bilirnir.
Destek Vektör Makineleri
Genellikle SVM'ler sınıflandırma yaparmış gibi düşünülür ancak sınıflandırma ve regresyon problemlerinin her ikisini de kullanabilir. SVM kolaylıkla çoklu ve sürekli categorisel değişkenleri kontrol edebilir. SVM, yinelemeli şeklilde kullanılabilecek optimum bir hata payını en aza indirmeye yarıyan hiperdüzlem üretir. SVM'nin ana fikri aslında veri setlerini sınıflara bölen maksimum marjinal bir hiper düzlük bulmaktır.
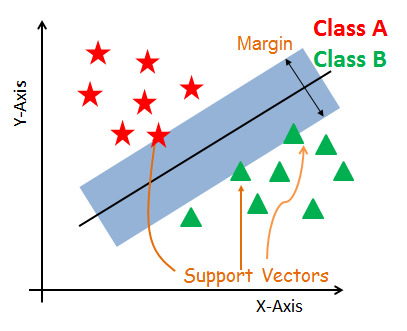
Destek Vektörleri
Destek vektörleri hiperdüzleme en yakın veri noktalarıdır. Bu noktalar ayırıcı çizgiyi marjinleri hesaplayarak daha iyi gösterir. Bu noktalar sınıflandırıcının yapımı ile daha alakalıdır.
Hyperdüzlem
Hiperdüzlem, farklı sınıflara sahip sıralı objelerin arasını ayıran bir karar düzlemidir.
Marjin
Marjin, en yakın iki sınıf satırının arasındaki boşluktur. Marjin, vektörleri veya en yakın noktaları desteklemek için satırdan dikey mesafe alınarak hesaplanır. Marjinin kalitesi iki sınıf arasındaki uzaklık büyüklüğü baz alınarak hesaplanır. Büyük marjin kaliteli, küçük marjin kalitesizdir.
SVM Nasıl Çalışır
SVM'nin ana amacı iki verisetini olabildiğince kesin şekilde ayırmaktır. Bu işlemi şöyle gerçekleştirir
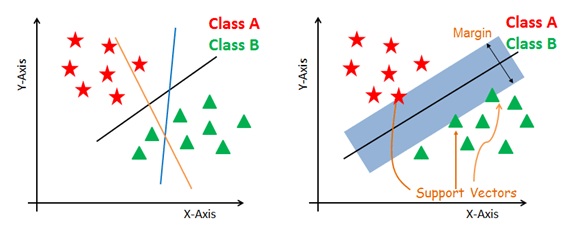
1. Sınıfları en iyi şekilde ayıran hiperplanlar oluşturur.
2. Sağ taraftaki şekilde gösterildiği gibi en yakın veri noktalarından maksimum ayrımı olan sağ hiperdüzlemi seçer.
Kodlama
Öncelikle gerekli veridizilerini yükleyelim.

Veridizisini yükledikden sonra isterseniz veridizisini biraz inceleyelim.


Verisetinin ilk 5 kaydını inceleyelim

Verileri Ayırma
train_test_split() fonksiyonunu kullanarak verisetlerini ayırabilirsiniz. Ayrıca rastgele seçim yapmak için random_state özelliğini de kullanabilirsiniz.

Model Oluşturma
Şimdi SVM modelini yapalım. Öncelikle SVM modülünü yükleyelim ve vektör sınıflandırıcı objeyi, SVC() şeklinde lineer çekirdek argümanı olarak geçirerek SVM modülünü inşa edelim.
Sonrasında modelinizi fit() komutuyla eğitim setine koyun. ve predict() komutuyla tahmin etme işlemlerini test verisetinde uygulayın.

Modeli Değerlendirme
Şimdi modelin ne kadar doğruluk payı ile göğüs kanserini tespit edebileceğine bakalım.
Doğruluk payı doğruluk, gerçek test seti değerleri ile öngörülen değerler karşılaştırılarak hesaplayabilirsiniz.

Gördüğünüz gibi 96.49% olasıkla doğru sınıflandırıyor ki bu gayet iyi bir yüzde
Avantajları
SVM sınıflandırıcıları Naïve Bayes algoritmasına göre daha hızlı ve doğruluk payı daha yüksek tahmin sunuyor. Kaşamasında eğitim noktalarının bir alt kümesini kullandıkları için daha az bellek kullanırlar. SVM, net bir ayrılma marjini ve yüksek boyutlu alanlar ile iyi çalışır.
Dezavantajları
SVM, uzun süren eğitim zamandından dolayı büyük verisetleri ile kullanıma rakiplerine göre uygun değildir ayrıca çakışan sınıflarla iyi çalışmamakla beraber kullanılan çekirdek türüne de duyarlıdır.
Sonuç Olarak
SVM doğruluk payı konusunda çok iyi ve kaliteli bir algoritma ancak büyük güç büyük sorumluluk getirir demişler") Büyük veri gruplarıyla çok uzun süren eğitim süresi dolayısıyla iyi çalışmamakta. Küçük ama kesin sonuç istediğiniz projelerde bu makine öğrenmesi algoritmasını kullanabilirsiniz.
Büyük veri gruplarıyla çok uzun süren eğitim süresi dolayısıyla iyi çalışmamakta. Küçük ama kesin sonuç istediğiniz projelerde bu makine öğrenmesi algoritmasını kullanabilirsiniz.
Daha fazla bilgi için DataCamp'ın kurslarına bakabilirsiniz.
Destek Vektör Makineleri(SVM) en çok kullanılan ve popüler makine öğrenmesi algoritmalarından biridir.
Destek Vektör Makineleri (SVM) lojistik regresyon (logistic regression) ve karar ağaçları (decision trees) gibi diğer sınıflandırıcılara göre daha yüksek doğruluk payına sahip bir sınıflandırma sunar. Bu algoritma daha çok doğrusal olmayan giriş boşluklarınını sınıflandırma tekniği ile bilinir. Yüz tanıma, alarm, e-posta sınıflandırma, haber siteleri için haber ,el yazısı ve gen sınıflandırma sistemleri gibi sistemlerde kullanılıyor.
Bu başlığımızda Python'da scikit-learn kullanacağız eğer bu paket hakkında daha çok şey öğrenmek istiyorsanız makine öğrenme kurslarıyla meşhur DataCamp'dan kurslara girebilirsiniz.
SVM heyecan verici bir algoritma olmasına rağmen konsept aslında oldukça basittir. Sınıflandırıcı, veri noktalarını en yüksek miktarda kenar boşluğuna sahip bir köprü kullanarak ayırır. Bu nedenle SVM sınıflandırıcıları ayrıca ayrımcı sınıflandırıcı (discriminative classifier) olarak da bilirnir.
Destek Vektör Makineleri
Genellikle SVM'ler sınıflandırma yaparmış gibi düşünülür ancak sınıflandırma ve regresyon problemlerinin her ikisini de kullanabilir. SVM kolaylıkla çoklu ve sürekli categorisel değişkenleri kontrol edebilir. SVM, yinelemeli şeklilde kullanılabilecek optimum bir hata payını en aza indirmeye yarıyan hiperdüzlem üretir. SVM'nin ana fikri aslında veri setlerini sınıflara bölen maksimum marjinal bir hiper düzlük bulmaktır.
Destek Vektörleri
Destek vektörleri hiperdüzleme en yakın veri noktalarıdır. Bu noktalar ayırıcı çizgiyi marjinleri hesaplayarak daha iyi gösterir. Bu noktalar sınıflandırıcının yapımı ile daha alakalıdır.
Hyperdüzlem
Hiperdüzlem, farklı sınıflara sahip sıralı objelerin arasını ayıran bir karar düzlemidir.
Marjin
Marjin, en yakın iki sınıf satırının arasındaki boşluktur. Marjin, vektörleri veya en yakın noktaları desteklemek için satırdan dikey mesafe alınarak hesaplanır. Marjinin kalitesi iki sınıf arasındaki uzaklık büyüklüğü baz alınarak hesaplanır. Büyük marjin kaliteli, küçük marjin kalitesizdir.
SVM Nasıl Çalışır
SVM'nin ana amacı iki verisetini olabildiğince kesin şekilde ayırmaktır. Bu işlemi şöyle gerçekleştirir
1. Sınıfları en iyi şekilde ayıran hiperplanlar oluşturur.
2. Sağ taraftaki şekilde gösterildiği gibi en yakın veri noktalarından maksimum ayrımı olan sağ hiperdüzlemi seçer.
Kodlama
Öncelikle gerekli veridizilerini yükleyelim.
Veridizisini yükledikden sonra isterseniz veridizisini biraz inceleyelim.
Verisetinin ilk 5 kaydını inceleyelim
Verileri Ayırma
train_test_split() fonksiyonunu kullanarak verisetlerini ayırabilirsiniz. Ayrıca rastgele seçim yapmak için random_state özelliğini de kullanabilirsiniz.
Model Oluşturma
Şimdi SVM modelini yapalım. Öncelikle SVM modülünü yükleyelim ve vektör sınıflandırıcı objeyi, SVC() şeklinde lineer çekirdek argümanı olarak geçirerek SVM modülünü inşa edelim.
Sonrasında modelinizi fit() komutuyla eğitim setine koyun. ve predict() komutuyla tahmin etme işlemlerini test verisetinde uygulayın.
Modeli Değerlendirme
Şimdi modelin ne kadar doğruluk payı ile göğüs kanserini tespit edebileceğine bakalım.
Doğruluk payı doğruluk, gerçek test seti değerleri ile öngörülen değerler karşılaştırılarak hesaplayabilirsiniz.
Gördüğünüz gibi 96.49% olasıkla doğru sınıflandırıyor ki bu gayet iyi bir yüzde
Avantajları
SVM sınıflandırıcıları Naïve Bayes algoritmasına göre daha hızlı ve doğruluk payı daha yüksek tahmin sunuyor. Kaşamasında eğitim noktalarının bir alt kümesini kullandıkları için daha az bellek kullanırlar. SVM, net bir ayrılma marjini ve yüksek boyutlu alanlar ile iyi çalışır.
Dezavantajları
SVM, uzun süren eğitim zamandından dolayı büyük verisetleri ile kullanıma rakiplerine göre uygun değildir ayrıca çakışan sınıflarla iyi çalışmamakla beraber kullanılan çekirdek türüne de duyarlıdır.
Sonuç Olarak
SVM doğruluk payı konusunda çok iyi ve kaliteli bir algoritma ancak büyük güç büyük sorumluluk getirir demişler
Büyük veri gruplarıyla çok uzun süren eğitim süresi dolayısıyla iyi çalışmamakta. Küçük ama kesin sonuç istediğiniz projelerde bu makine öğrenmesi algoritmasını kullanabilirsiniz. Daha fazla bilgi için DataCamp'ın kurslarına bakabilirsiniz.

