



Selamün Aleyküm
öncelikle şunu söyleyim kesin calisiyor diyemem iddialı değilim ama sanal makinemdeki bWAPP'de işe yaradı diğer siteleri bilmiyorum ufak çaplı bir kütüphane, internetteki her site login olmadan alt sayfaları ile etkileşim kurmamıza izin veriyor açıkcası deneyecek site bulamadım siz denersiniz aklınızda varsa
kod login şifre ve click değerleri icin yazıldı reqister veya dördüncü bir inputta hata verir
yazdıgım kod verilen siteye gidip gidilen sitedeki input ve button değerlerini çekip bu degerler icindeki id ve name degerlerini alıcak bu değerlerede sizin verdiginiz kullanıcı adını ve şifreyi girip click butonuna basacakbu ne işe yarar :
ben şahsen bWAPP zafiyetli makinesini çözerken selenium ile siteyi acip requests ile sitedeki oturumu tutup ardından requests ile devam ediyordum direk requests ile hedef siteye işlem yaptığım zaman login sayfasına yönlendiriliyordum ve hedef site ile etkileşimim başarısız oluyordu kendime yazdıgım modulüde sizinle paylaşıyorum
kullanım :
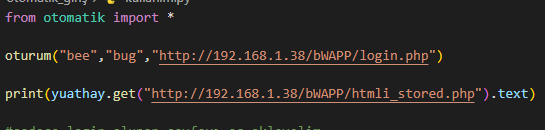
oturum seçeneği :
ilk seçenekde kullanıcı adı şifre ve login olunacak site girilir ardından kod yukarıda dedigim işlemleri gerçekleştirir ve login olunduktan sonra requests ile oturum tutulur ardından ---yuathay--- ı
requests kütüphanesini kullanıyormuş gibi kullanabilirsiniz requests.get(site) yaptıgınızda sizi login sayfasına yönlendiren siteleri yuathay.get(site) ile atlatabilirsiniz login sayfasına gitmeden direk istediginiz siteye gideceksiniz
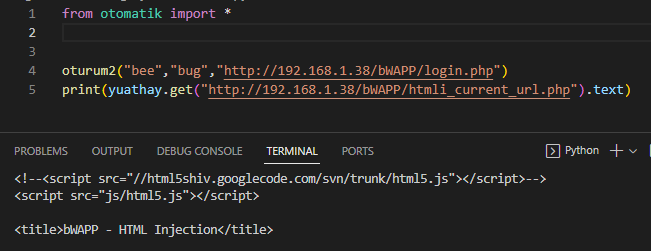
oturum2 seçeneği :
bu seçenektede aynı şeyler geçerli ama bazı sitelerin requests ile kaynak kodlarını almaya çalıştıgımızda input degerleri ve button degerleri gelmiyor az bir içerik geliyor bu durumda kod otomatik olarak tarayıcının console kısmında javascript kodları çalıştırıp input ve button degerlerinin id ve name'lerini alır ve işlemlere devam eder NOT : oturum çalışmazsa oturum2'yi deneyin oturum daha hızlı gibi geldi bana

ilk olarak requests kütüphanesi ile siteye get istegi yapıyorum
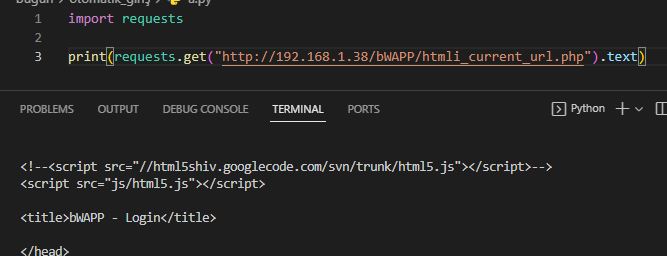
gelen sonuc login sayfasından geliyor yani beni istedigim sayfaya degilde login sayfasına attı şimdi modulle yapalım
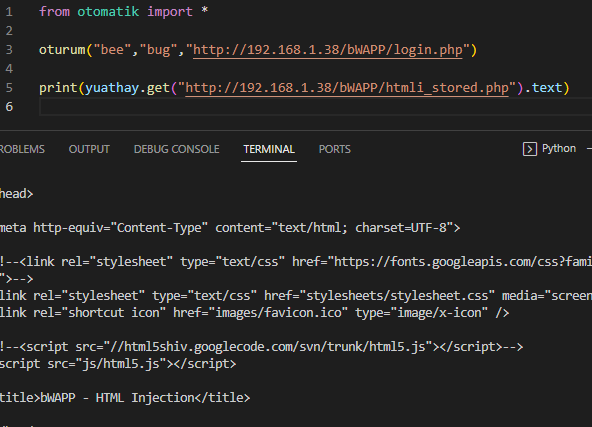
ve istedigim sayfaynın içeriğini alabildim title kısmından anlaşılabiliyor
oturum2'de aynı şekilde ama çıktısı yavaş geliyor :
zamanında console kısmında kod calistirma yolunu bana gösteren closx e teşekkür ederim
kodlar :
Python:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.firefox.options import Options
import requests
#kodu genel mantıgı siteye gidip sitedeki kullanıcı adı şifre ve giriş düğmelerinin id ve name değerlerini alıp siteye giriş yapıp oturumu tutup requests kütüphanesi ile işlemler yapmak
yuathay = requests.Session() #yuathay yerine kendi istediginiz adı verebilirsiniz ama adı değiştirdiginizde aşagıdada yuathay yazan yerlere tercih ettiğiniz yeni adı yazmanız gerekir
def oturum(kullanici_adı,şifre,site):
option = Options()
option.add_argument("--headless")#görünmez modda başlatıyoruz tarayıcıyı
browser = webdriver.Firefox(options=option)
browser.get(site)
login_input = []
input_elements = browser.find_elements(By.TAG_NAME, "input") #find_elements(By.TAG_NAME,"input") sitedeki bütün input taglarını alır
for element in input_elements:
login_input.append(element.get_attribute("id")) #inputtaki id değerlerini alrır
login_input.append(element.get_attribute("name")) #inputtaki name değerlerini alır
button_click = []
buttons = browser.find_elements(By.TAG_NAME,"button")
for button in buttons:
button_click.append(button.get_attribute("id"))
button_click.append(button.get_attribute("name"))
input_degerleri = []
input_döngü = [input_degerleri.append(a) for a in login_input if a and a not in input_degerleri]
click_degerleri = []
#---if w : w boş degilse demek---w not in click_degerleri : w click degerlerinde değilse demek yani tekrar eden eleman eklenmiyor---
click_döngü = [click_degerleri.append(w) for w in button_click if w and w not in click_degerleri]
sayı = 0
index = 0
durum = True
while durum:
try:
browser.find_element(By.ID,input_degerleri[sayı]).send_keys(kullanici_adı)
browser.find_element(By.ID,input_degerleri[index]).send_keys(şifre)
for y in range(len(click_degerleri)):
try:
browser.find_element(By.ID,click_degerleri[y]).click()
except:
browser.find_element(By.NAME,click_degerleri[y]).click()
browser.find_element(By.NAME,input_degerleri[sayı]).send_keys(kullanici_adı)
browser.find_element(By.NAME,input_degerleri[index]).send_keys(şifre)
for o in range(len(click_degerleri)):
try:
browser.find_element(By.ID,click_degerleri[o]).click()
except:
browser.find_element(By.NAME,click_degerleri[o]).click()
except:
pass
sayı += 1
if sayı == len(input_degerleri):
sayı = 0
index += 1
if index == len(input_degerleri):
ana_sayfa = browser.get_cookies()
for cookie in ana_sayfa:
yuathay.cookies.set(cookie['name'],cookie['value'])
durum = False
#bazen büyük sitelerde requests kütüphanesi ile id ve name değerlerini cekemedigimiz durumlar olabiliyor bunun icin oturum2'yi kullanıcaz bu fonksiyonda sitenin console kısmına gidilir ve oraya asağıdaki javascript
#kodları yazılır buradan gelen degerler bize id ve name degerlerini verir ve işlemlerimize bu değerler ile devam ederiz
def oturum2(kullanici_adı,şifre,site):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument("--ignore-certificate-errors")
chrome_options.add_argument(f"--user-agent=Lynx: Lynx/2.8.8pre.4 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/2.12.23")
chrome_options.add_argument("headless")
chrome_options.page_load_strategy = "normal"
chrome_options.set_capability("goog:loggingPrefs", {"performance": "ALL"})
driver = webdriver.Chrome(options=chrome_options)
#siteden input taglarını almak icin javasript kodu
script_for_input = '''
var elements = document.querySelectorAll('input');
var Values = [];
for (var i = 0; i < elements.length; i++) {
var idValue = elements[i].getAttribute('id');
var nameValue = elements[i].getAttribute('name');
if (idValue) {
Values.push(idValue);
}
if (nameValue) {
Values.push(nameValue);
}
}
return Values;
'''
#button taglarını almak icin javascript kodu
script_for_button ='''
var elements = document.querySelectorAll('button');
var Values = [];
for (var i = 0; i < elements.length; i++) {
var idValue = elements[i].getAttribute('id');
var nameValue = elements[i].getAttribute('name');
if (idValue) {
Values.push(idValue);
}
if (nameValue) {
Values.push(nameValue);
}
}
return Values;
'''
driver.get(site)
results = driver.execute_script(script_for_input) #execute_script ile sitede javascript çalıştırıyoruz
inputlar = []
a = [inputlar.append(q) for q in results if q and q not in inputlar]
çıktı = driver.execute_script(script_for_button)
buttonlar = []
b = [buttonlar.append(i) for i in çıktı if i and i not in buttonlar]
#buttonlar = list(set(çıktı)) #bunu yaparakta tekrarlanan öğeleri kaldırabiliriz ben pratik icin boyle yazıyorum
driver.quit()
firefox_options = webdriver.FirefoxOptions()
firefox_options.add_argument("--headless")
driver = webdriver.Firefox(options=firefox_options)
driver.get(site)
durum = True
sayı = 0
index = 0
while durum:
try:
driver.find_element(By.ID,inputlar[sayı]).send_keys(kullanici_adı)
driver.find_element(By.ID,inputlar[index]).send_keys(şifre)
for y in range(len(buttonlar)):
try:
driver.find_element(By.ID,buttonlar[y]).click()
except:
driver.find_element(By.NAME,buttonlar[y]).click()
driver.find_element(By.NAME,inputlar[sayı]).send_keys(kullanici_adı)
driver.find_element(By.NAME,inputlar[index]).send_keys(şifre)
for o in range(len(buttonlar)):
try:
driver.find_element(By.ID,buttonlar[o]).click()
except:
driver.find_element(By.NAME,buttonlar[o]).click()
except:
pass
sayı += 1
if sayı == len(inputlar):
sayı = 0
index += 1
if index == len(inputlar):
ana_sayfa = driver.get_cookies()
for cookie in ana_sayfa:
yuathay.cookies.set(cookie['name'],cookie['value'])
durum = False
