Uzun bir aradan sonra herkese merhabalar bugün sizlerle birlikte sevgili @Neoax 'ın açmış olduğu konuyu okuduysanız eğer ki aşağıda linkini bırakacağım. C# programlama dilinde web shell scanner kodladım, kodlarken bazı taklit yetenekleri keşfederek CloudFlare üzerinde yeni bir bypass tekniği geliştirmiş oldum. Lakin üzülerek belirtmekte fayda var tekniğe tam olarak C# kodu üzerinde hakim olamadığımdan dolayı koda dökemedim bu yüzden yapay zeka yardımı aldım akabinde kodları da biraz değiştirdi...
Kodlarımız yükü azaltmak adına iki basamaktan oluşmakta ilk basamakta Selenium arka planda açılarak defacer.id sitesine gidiyor & tek tek sayfaları gezerek sayfaların HTML içeriklerini kaydediyor. Hatırlayın @Neoax 'ın açmış olduğu konuda bir istek atıyordu bu giden istekte CloudFlare 'ye takılınca problem çıkıyor & siteleri çekemiyorduk. Bugün bu konuda bu sorunu çözmüş olduk.
İkinci basamakta ise oluşan sayfa içeriklerini tek bir metin belgesinde birleştirip Regex modülü ile parçalara ayırıp web sitelerini ortaya çıkarıyor & taramaya hazır hale geliyor. Bu kodlar en temel düzeyde yazıldığı için sizlerin farklı sitelere & URL adreslerine uyarlayacağından eminim.
@Neoax Konusu ; Bana Tıkla Bu Adresten
Python:
import asyncio
import aiohttp
import aiofiles
from bs4 import BeautifulSoup
from time import strftime
from colorama import init, Fore
import argparse
with open("pathlist.txt", "r") as file:
paths = file.read().splitlines()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36"
}
today = strftime("%d/%m/%Y")
today1 = str(int(today.split("/")[0]) + 1).zfill(2) + today[2:]
async def fetch_today_domains(session, base_url):
sites = []
page = 1
while True:
async with session.get(base_url + str(page), headers={
"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
}) as response:
text = await response.text()
soup = BeautifulSoup(text, "html.parser")
rows = soup.select("tbody tr")
found_today = False
for row in rows:
try:
cells = row.find_all("td")
if len(cells) < 9:
continue
date = cells[0].get_text(strip=True)
domain = cells[8].get_text(strip=True)
if date != today and date != today1:
continue
else:
found_today = True
domain = domain.split("/")[0].strip()
if domain.endswith(".tr"):
continue
sites.append("http://" + domain + "/")
except Exception as e:
print(e)
found_today = False
if not found_today:
break
page += 1
return sites
async def CheckSite(session, url):
for path in paths:
full_url = url + path
try:
async with session.get(full_url, headers=headers, timeout=10) as response:
text = await response.text()
if 'type="file"' in text or 'name="command"' in text or "<pre align=center><form method=post>Password<br><input type=password name=pass style='background-color:whitesmoke;border:1px solid #FFF;outline:none;' required>" in text:
print(f"{Fore.LIGHTGREEN_EX}[+] Web shell bulundu: {Fore.LIGHTWHITE_EX}{full_url}")
async with aiofiles.open(args.output, "a") as f:
await f.write(full_url + "\n")
break
else:
print(f"{Fore.LIGHTRED_EX}[-] Web shell bulunamadı: {Fore.LIGHTWHITE_EX}{full_url}")
except:
continue
async def CheckUrl(session, url, path):
full_url = url + path
try:
async with session.get(full_url, headers=headers, timeout=10) as response:
text = await response.text()
if 'type="file"' in text or 'name="command"' in text or "<pre align=center><form method=post>Password<br><input type=password name=pass style='background-color:whitesmoke;border:1px solid #FFF;outline:none;' required>" in text:
print(f"{Fore.LIGHTGREEN_EX}[+] Web shell bulundu: {Fore.LIGHTWHITE_EX}{full_url}")
async with aiofiles.open(args.output, "a") as f:
await f.write(full_url + "\n")
else:
print(f"{Fore.LIGHTRED_EX}[-] Web shell bulunamadı: {Fore.LIGHTWHITE_EX}{full_url}")
except:
pass
async def print_logo():
print(f"""{Fore.GREEN}
.dMMMb dMP dMP dMMMMMP dMP dMP dMMMMMP dMP dMP
dMP" VP dMP dMP dMP dMP dMP dMP dMP.dMP
VMMMb dMMMMMP dMMMP dMP dMP dMMMP VMMMMP
dP .dMP dMP dMP dMP dMP dMP dMP dA .dMP
VMMMP" dMP dMP dMMMMMP dMMMMMP dMMMMMP dMMMMMP VMMMP"
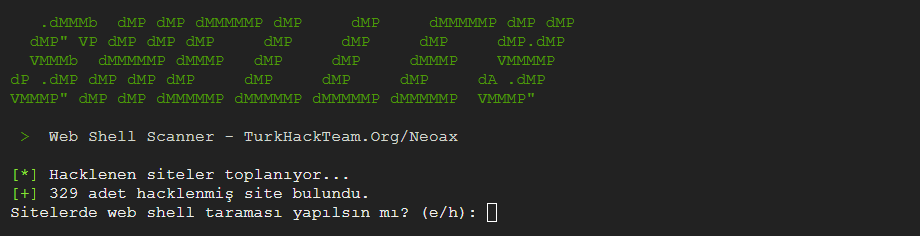
> {Fore.WHITE} Web Shell Scanner - TurkHackTeam.Org/Neoax
""")
def GetArgs():
parser = argparse.ArgumentParser()
parser.add_argument("-u", "--url", help="Taranacak web siteyi belirtmenizi sağlar.", metavar="")
parser.add_argument("-f", "--file", help="Taranacak sitelerin bulunduğu dosyayı belirtmenizi sağlar.", metavar="")
parser.add_argument("-t", "--today", help="Günlük hacklenmiş siteleri toplar.", action='store_true')
parser.add_argument("-o", "--output", help="Sonuçları kayıt edeceği dosyayı belirtmenizi sağlar.", default="shells.txt", metavar="")
return parser, parser.parse_args()
async def main():
await print_logo()
if args.url:
async with aiohttp.ClientSession() as session:
tasks = [CheckUrl(session, args.url, path) for path in paths]
await asyncio.gather(*tasks)
elif args.file:
async with aiohttp.ClientSession() as session:
async with aiofiles.open(args.file, mode='r', encoding='utf-8') as f:
urls = list(set((await f.read()).splitlines()))
tasks = [CheckSite(session, url) for url in urls]
await asyncio.gather(*tasks)
elif args.today:
sites = []
async with aiohttp.ClientSession() as session:
print(f"{Fore.LIGHTGREEN_EX}[*]{Fore.LIGHTWHITE_EX} Hacklenen siteler toplanıyor...")
sites.extend(await fetch_today_domains(session, "https://defacer.id/archive/"))
sites.extend(await fetch_today_domains(session, "https://defacer.id/archive/special/"))
sites.extend(await fetch_today_domains(session, "https://defacer.id/archive/onhold/"))
print(f"{Fore.LIGHTGREEN_EX}[+] {Fore.LIGHTWHITE_EX}{len(sites)} adet hacklenmiş site bulundu.")
if input(f"{Fore.LIGHTWHITE_EX}Sitelerde web shell taraması yapılsın mı? (e/h): ").lower() == "h":
async with aiofiles.open(args.output, "a") as f:
for site in sites:
await f.write(site + "\n")
print(f"{Fore.LIGHTGREEN_EX}[+]{Fore.LIGHTWHITE_EX} Sonuçlar '{args.output}' dosyasına kayıt edildi.")
exit()
tasks = [CheckSite(session, site) for site in sites]
await asyncio.gather(*tasks)
else:
parser.print_help()
if __name__ == "__main__":
try:
init()
parser, args = GetArgs()
asyncio.run(main())
except KeyboardInterrupt:
exit()
Kod:
1.php
2.php
3.php
4.php
5.php
6.php
7.php
8.php
9.php
10.php
q.php
w.php
e.php
r.php
t.php
y.php
u.php
o.php
p.php
a.php
d.php
f.php
g.php
s.php
h.php
j.php
k.php
l.php
i.php
z.php
x.php
c.php
v.php
b.php
n.php
m.php
alfa.php
sym.php
shell.php
pwn.php
mx.php
c99.php
wp-22.php
sh3ll.php
up.php
file.php
upload.php
database.php
index.php
man.php
wso.php
mailer.php
cpanel.php
sql.php
mysql.php
r00t.php
abc.php
settings.php
tmp.php
cyber.php
c99.php
r57.php
404.php
gaza.php
d4rk.php
priv8.php
911.php
c100.php
cp.php
sa.php
readme.php
info.php
ls.php
admin.php
t00.php
dz.php
whmcs.php
123.php
wp.phpusing System;using System.Collections.Generic;using OpenQA.Selenium;using OpenQA.Selenium.Chrome;using System.Threading;using System.IO;
C#:
var driver = CreateStealthChromeDriver();
try
{
string baseUrl = "https://defacer.id/archive";
driver.Navigate().GoToUrl(baseUrl);
Thread.Sleep(3000); // sayfa yüklenmesi için bekleme
Console.WriteLine("Sayfa yüklendi. Otomatik kontrol başlatıldı.");
Console.WriteLine("Programı sonlandırmak için 'm' yazıp Enter'a basabilirsiniz.");
while (true)
{
// Kullanıcının çıkmak isteyip istemediğini kontrol et
if (Console.KeyAvailable)
{
var key = Console.ReadKey(intercept: true);
if (key.KeyChar == 'm' || key.KeyChar == 'M')
{
Console.WriteLine("Program sonlandırılıyor.");
break;
}
}
// Doğrulama metnini tara
bool found = ScanForVerification(driver);
if (found)
{
try
{
// İlk sayfanın (archive) içeriğini kaydet (sayfa 1)
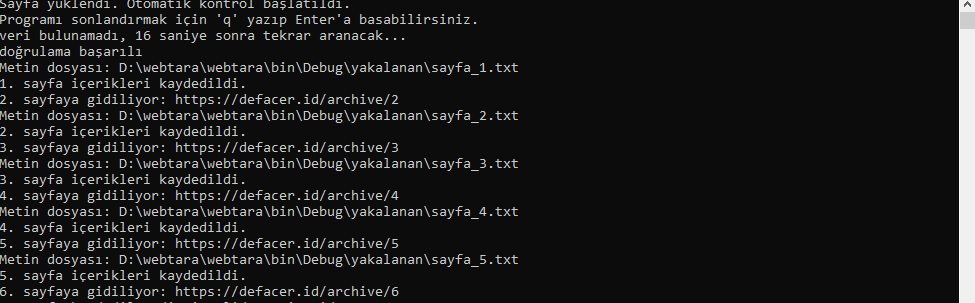
SavePageContents(driver, 1);
Console.WriteLine("1. sayfa içerikleri kaydedildi.");
}
catch (Exception ex)
{
Console.WriteLine("Kaydetme sırasında hata (sayfa 1): " + ex.Message);
}
// 2..30 arası sayfaları sırayla kaydet
for (int p = 2; p <= 30; p++)
{
try
{
string pageUrl = $"{baseUrl}/{p}";
Console.WriteLine($"{p}. sayfaya gidiliyor: {pageUrl}");
driver.Navigate().GoToUrl(pageUrl);
Thread.Sleep(3000); // sayfa yüklenmesi için bekle
SavePageContents(driver, p);
Console.WriteLine($"{p}. sayfa içerikleri kaydedildi.");
}
catch (Exception ex)
{
Console.WriteLine($"{p}. sayfa kaydedilemedi: " + ex.Message);
}
}
Console.WriteLine("Tüm sayfalar kaydedildi. Döngü sona eriyor.");
break; // tüm sayfalar kaydedildikten sonra döngüden çık
}
Thread.Sleep(16000);
}
}
finally
{
try
{
driver.Quit();
}
catch { }
}
C#:
static bool ScanForVerification(IWebDriver driver)
{
string target = "Cyber Attack Archive";
try
{
var elements = driver.FindElements(By.XPath("//*"));
foreach (var el in elements)
{
string txt = string.Empty;
try
{
txt = el.Text ?? string.Empty;
}
catch
{
continue; // StaleElement hatalarını atla
}
if (!string.IsNullOrEmpty(txt) &&
txt.IndexOf(target, StringComparison.OrdinalIgnoreCase) >= 0)
{
Console.WriteLine("doğrulama başarılı");
return true;
}
}
Console.WriteLine("veri bulunamadı, 16 saniye sonra tekrar aranacak...");
return false;
}
catch (Exception ex)
{
Console.WriteLine("Hata: " + ex.Message);
return false;
}
}
C#:
static ChromeDriver CreateStealthChromeDriver()
{
var options = new ChromeOptions();
options.AddArgument("--no-sandbox");
options.AddArgument("--disable-blink-features=AutomationControlled");
options.AddExcludedArgument("enable-automation");
options.AddArgument("--disable-infobars");
options.AddArgument("--start-maximized");
options.AddArgument("--disable-dev-shm-usage");
string userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36";
options.AddArgument($"--user-agent={userAgent}");
options.AddAdditionalOption("useAutomationExtension", false);
var service = ChromeDriverService.CreateDefaultService();
service.HideCommandPromptWindow = true;
var driver = new ChromeDriver(service, options);
var script = @"
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
Object.defineProperty(navigator, 'plugins', { get: () => [1,2,3] });
Object.defineProperty(navigator, 'mimeTypes', { get: () => [1,2,3] });
Object.defineProperty(navigator, 'languages', { get: () => ['en-US','en'] });
try {
const getParameter = WebGLRenderingContext.prototype.getParameter;
WebGLRenderingContext.prototype.getParameter = function(parameter) {
if (parameter === 37445) return 'Intel Inc.';
if (parameter === 37446) return 'Intel(R) Iris(TM) Graphics';
return getParameter.call(this, parameter);
};
} catch(e) {}
const originalQuery = window.navigator.permissions && window.navigator.permissions.query;
if (originalQuery) {
window.navigator.permissions.__query = originalQuery;
window.navigator.permissions.query = function(parameters) {
if (parameters && parameters.name === 'notifications') {
return Promise.resolve({ state: Notification.permission });
}
return window.navigator.permissions.__query(parameters);
};
}";
var addScriptParams = new Dictionary<string, object> { { "source", script } };
driver.ExecuteCdpCommand("Page.addScriptToEvaluateOnNewDocument", addScriptParams);
var uaParams = new Dictionary<string, object> { { "userAgent", userAgent } };
driver.ExecuteCdpCommand("Network.setUserAgentOverride", uaParams);
Thread.Sleep(1000);
return driver;
}
C#:
static void SavePageContents(IWebDriver driver, int pageNumber)
{
// Kayıt dizinini hazırla
string folder = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "yakalanan");
if (!Directory.Exists(folder))
Directory.CreateDirectory(folder);
// string timestamp = DateTime.Now.ToString("yyyyMMdd_HHmmss");
//string textFile = Path.Combine(folder, $"sayfa{pageNumber}_metin_{timestamp}.txt");
// string htmlFile = Path.Combine(folder, $"sayfa{pageNumber}_html_{timestamp}.html");
string textFile = Path.Combine(folder, $"sayfa_{pageNumber}.txt");
// Görünür metni al (body text)
string bodyText = string.Empty;
try
{
var body = driver.FindElement(By.TagName("body"));
bodyText = body.Text ?? string.Empty;
}
catch
{
// Eğer body bulunamazsa fallback olarak tüm sayfanın text'ini al
bodyText = driver.PageSource ?? string.Empty;
}
// HTML'i al (outerHTML veya PageSource)
string html = string.Empty;
try
{
var htmlEl = driver.FindElement(By.TagName("html"));
html = htmlEl.GetAttribute("outerHTML") ?? driver.PageSource ?? string.Empty;
}
catch
{
html = driver.PageSource ?? string.Empty;
}
// Dosyalara yaz
File.WriteAllText(textFile, bodyText);
// File.WriteAllText(htmlFile, html);
Console.WriteLine($"Metin dosyası: {textFile}");
// Console.WriteLine($"HTML dosyası: {htmlFile}");
}[ GÖRSEL GÖSTERİM ]



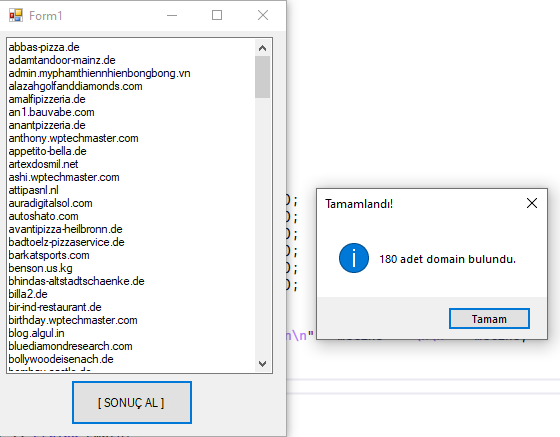
Şimdi sayfa içeriklerimiz kaydedildiğine göre artık URL ayrışımına geçebiliriz. Bunun için yeni bir proje oluşturup form içerisine bir adet TextBox ile Buton eklemeniz yeterli. Buton operasyonumuzu başlatacak ve TextBox ögemiz içerisine ayrıştırılan URL 'leri verecek.
using System;using System.Collections.Generic;using System.IO;using System.Linq;using System.Text.RegularExpressions;using System.Windows.Forms;
C#:
string metin1 = File.ReadAllText(@"DOSYA_YOLU\yakalanan\sayfa_1.txt");
string metin2 = File.ReadAllText(@"DOSYA_YOLU\yakalanan\sayfa_2.txt");
string metin3 = File.ReadAllText(@"DOSYA_YOLU\yakalanan\sayfa_3.txt");
// Metinleri aralarına boş satır ekleyerek birleştir
string birlesikMetin = metin1 + "\n\n" + metin2 + "\n\n" + metin3;
// Birleşik metni bir dosyaya yaz
string dosyaYolu = "birlesik_metin.txt";
File.WriteAllText(dosyaYolu, birlesikMetin);
string input = File.ReadAllText(dosyaYolu) ?? string.Empty;
if (string.IsNullOrWhiteSpace(input))
{
MessageBox.Show("Lütfen sayfa içeriğini yapıştır.", "Uyarı", MessageBoxButtons.OK, MessageBoxIcon.Warning);
return;
}
var domains = ExtractDomainsSmart(input);
textBox1.Text = string.Join(Environment.NewLine, domains);
MessageBox.Show($"{domains.Count} adet domain bulundu.", "Tamamlandı!",
MessageBoxButtons.OK, MessageBoxIcon.Information);
C#:
private static List<string> ExtractDomainsSmart(string text)
{
string pattern = @"(?<!@)\b((?:[a-zA-Z0-9-]+\.)+[a-zA-Z]{2,})(?:/[^\s]*)?";
var matches = Regex.Matches(text, pattern, RegexOptions.IgnoreCase);
var unique = new HashSet<string>(StringComparer.OrdinalIgnoreCase);
foreach (Match match in matches)
{
if (!match.Success) continue;
string candidate = match.Groups[1].Value.Trim().ToLowerInvariant();
// Çok kısa veya bozuk girdileri at
if (candidate.Length < 4 || !candidate.Contains('.'))
continue;
// Noktayla bitenleri temizle
candidate = candidate.TrimEnd('.', '/');
// www. önekini kaldır
if (candidate.StartsWith("www."))
candidate = candidate.Substring(4);
// Gereksiz karakterleri at
candidate = candidate.Split(new[] { '/', ':', '?' }, StringSplitOptions.RemoveEmptyEntries)[0];
// Basit domain doğrulama
if (Regex.IsMatch(candidate, @"^[a-z0-9-]+(\.[a-z0-9-]+)+$"))
unique.Add(candidate);
}
return unique.OrderBy(x => x).ToList();
}[ SONUÇ GÖRSELİ ]
~ Şimdi gidip @Neoax 'ın göstermiş olduğu Shell Scanner ile URL dizin taraması yaparak web sitelerinde shell hangi dizinde var kontrol edebilirim. Teşekkürler... ~
Son düzenleme: