



Öncelikle bir önceki konum oldukça kısa ve yalnızca teorik anlatım olduğundan konum kaldırılmıştı bu konuda daha fazla kitleye hitap eden daha detaylı yine yalnızca teorik ama forumdaki kişilerin işine yarayabilecek bir temel yapay zeka anlatımı olacak diye düşünüyorum.
Öncelikle günümüzdeki LLM yani Large Language Modellerinin nasıl çalıştığını en kısa ve temel haliyle anlatmak gerekirse telefonlarda yıllardır olan autocomplete özelliğinin çok daha gelişmiş bağlamı anlayabilen ve devasa veri ile eğitilmiş halidir.
Nasıl telefonunuzda "Bugün..." yazınca size kelime önerileri sunuyorsa LLM modelleri de bir sonraki kelimeyi tahmin eder. Ama burada önemli fark şu; sadece son kelimeye bakmaz cümlenin tamamını hatta bazen yüzlerce kelimeyi birlikte değerlendirir.
Şimdi biraz daha teknik kısma geçelim;
Öncelikle bir LLM modelinin eğitilebilmesi için elimizde devasa veri setleri olması gerekir. Bu veri setleri tek tek bakıldığında basit metinlerden oluşur ama sayıları milyarlar seviyesindedir. Kitaplar, makaleler, forum yazıları, kodlar gibi birçok farklı kaynaktan toplanır
Örneğin:
"Ali yemek yedi çünkü çok açtı"
Bu tek başına küçük bir veri gibi gözükür ama model bu tarz milyarlarca cümle görür.
Peki bu veriler ne işe yarar?
Model eğitim sırasında genelde şu tarz bir görev yapar:
"Ali yemek yedi çünkü çok ___"
Buradaki boşluğu tahmin etmeye çalışır.
İlk başta tahminleri tamamen saçma olur:
"Ali yemek yedi çünkü çok demokrasi"
Daha sonra doğru cevabın "açtı" olduğunu öğrenir ve kendi içindeki ağırlıkları günceller. Bu işlem milyarlarca kez tekrar edilir. Yani model ezber yapmaz hangi kelimenin hangi bağlamda daha doğru olduğunu istatistiksel olarak öğrenir.
Burada embeddings kavramı devreye girer.
Embeddings aslında kelimelerin sayısal karşılıklarıdır. Bilgisayarlar kelimelerle değil sayılarla çalıştığı için her kelime bir vektör dediğimiz sayı dizilerine çevrilir.
Basit bir örnekle:
Ali = (0.21, 0.88, 0.54)
yemek = (0.65, 0.12, 0.33)
açtı = (0.77, 0.44, 0.91)
Gerçekte bu değerler yüzlerce boyuttan oluşur ama mantık bu.
Daha basitleştirerek düşünürsek:
Ali = Canlılık (0.9), Boyut (0.5)
Yemek = Canlılık (0.4), Boyut (0.2)
Yedi = Canlılık (0.3), Boyut (0.2)
Açtı = Canlılık (0.8), Boyut (0.4)

Bu sayılar tamamen örnek ama model zamanla şunu öğrenir:
hangi kelime hangi tür şeylerle birlikte kullanılır, hangisi canlı, hangisi nesne, hangisi durum vs.
Embeddings'in önemli özelliklerinden biri de benzer kelimelerin birbirine yakın konumlanmasıdır.
Mesela:
"kedi" ile "köpek" birbirine yakın olur
"kedi" ile "araba" daha uzak olur

Hatta eğer konuyu farklı bir çok kaynaktan incelerseniz aşağıdaki örneği bir çok yerde göreceksiniz:
"kral - erkek + kadın ≈ kraliçe" (Kral kavramından erkeği çıkartıp kadın eklediğimizde kraliçe sonucuna varıyoruz)
Bu tamamen vektör matematiği ile olur.
Ama burada önemli bir nokta var:
Yapay zekalar kelimelerin anlamını insanlar gibi gerçekten anlamaz.
Sadece hangi kelimenin hangi kelimeyle birlikte kullanıldığını çok iyi öğrenir.
Yani "açlık" hissinin ne olduğunu bilmez ama "açlık" kelimesinin hangi cümlelerde geçtiğini bilir.
Şimdiye kadar anlattığımız kısım işin temel mantığı. Ama modern LLM'ler sadece kelime tahmini yapan sistemler değil.
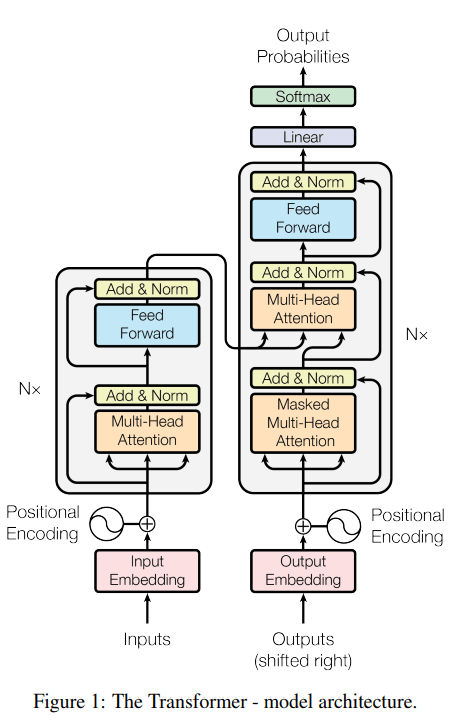
Burada devreye Transformer mimarisi girer.
Transformer'ın en önemli olayı attention mekanizmasıdır.
Bu mekanizma sayesinde model cümledeki tüm kelimeler arasındaki ilişkiyi aynı anda değerlendirebilir.
Örnek:
"Ali, Ayşe'ye kitabı verdi çünkü o çok nazikti"
Buradaki "o" kim?
Model bunu çözmeye çalışır:
Ali mi nazik
Ayşe mi nazik
Attention sayesinde kelimeler arasındaki ilişkileri kurarak doğruya yakın tahmin yapar.
Bu özellik eski yapay zeka sistemlerinde yoktu ve LLM'leri güçlü yapan şeylerden biri bu.
Kısaca toparlamak gerekirse:
LLM = gelişmiş kelime tahmin sistemi
Embeddings = kelimelerin sayısal hali
Eğitim = sürekli tahmin yapıp hatayı düzeltme süreci
Transformer = bağlamı anlamayı sağlayan yapı
Attention = kelimeler arası ilişki kurma sistemi
Bu sistemler bilinçli değil düşündüklerini sanmazlar hissetmezler. Ama çok büyük veri sayesinde insana oldukça doğal gelen metinler üretebilirler. Bu yüzden genelde kullanıcılar ki buna bende dahilim mimariyi tam olarak bilmediği zaman bilinçsiz olarak karşısındakine bir insanmış gibi veya inanılmaz zeki bir sistemmiş gibi güvenebilip, inanabilip, şaşırabiliyor Evet sistem oldukça zekice ama bu veriler yokluktan gelen yada baştan icat edilmiş veriler kesinlikle değil yapay zekaların ürettiği her sonuç aslında birer mükemmelleştirilmiş kelime tahmini sisteminin birer sonucudur.
Ben konuyu burada bitiriyorum fakat yanlış anlaşılmasın bu konu, yapay zeka konusunun yalnızca temel'i hatta belkide temel anlatım bile sayılamaz yalnızca insanların kafasında bir fikir oluşmasını sağlayacak bir yazı olmuştur.. Detaya inmek isteyen arkadaşlar için birkaç kaynak bırakıyorum;
LLM Serisi
Farklı Bir LLM Serisi
İngilizce;
Stanford
OpenAI'ın kurucu ekibinde yer alan "Andrej Karpathy"ın Bir videosu
Öncelikle günümüzdeki LLM yani Large Language Modellerinin nasıl çalıştığını en kısa ve temel haliyle anlatmak gerekirse telefonlarda yıllardır olan autocomplete özelliğinin çok daha gelişmiş bağlamı anlayabilen ve devasa veri ile eğitilmiş halidir.
Nasıl telefonunuzda "Bugün..." yazınca size kelime önerileri sunuyorsa LLM modelleri de bir sonraki kelimeyi tahmin eder. Ama burada önemli fark şu; sadece son kelimeye bakmaz cümlenin tamamını hatta bazen yüzlerce kelimeyi birlikte değerlendirir.
Şimdi biraz daha teknik kısma geçelim;
Öncelikle bir LLM modelinin eğitilebilmesi için elimizde devasa veri setleri olması gerekir. Bu veri setleri tek tek bakıldığında basit metinlerden oluşur ama sayıları milyarlar seviyesindedir. Kitaplar, makaleler, forum yazıları, kodlar gibi birçok farklı kaynaktan toplanır
Örneğin:
"Ali yemek yedi çünkü çok açtı"
Bu tek başına küçük bir veri gibi gözükür ama model bu tarz milyarlarca cümle görür.
Peki bu veriler ne işe yarar?
Model eğitim sırasında genelde şu tarz bir görev yapar:
"Ali yemek yedi çünkü çok ___"
Buradaki boşluğu tahmin etmeye çalışır.
İlk başta tahminleri tamamen saçma olur:
"Ali yemek yedi çünkü çok demokrasi"
Daha sonra doğru cevabın "açtı" olduğunu öğrenir ve kendi içindeki ağırlıkları günceller. Bu işlem milyarlarca kez tekrar edilir. Yani model ezber yapmaz hangi kelimenin hangi bağlamda daha doğru olduğunu istatistiksel olarak öğrenir.
Burada embeddings kavramı devreye girer.
Embeddings aslında kelimelerin sayısal karşılıklarıdır. Bilgisayarlar kelimelerle değil sayılarla çalıştığı için her kelime bir vektör dediğimiz sayı dizilerine çevrilir.
Basit bir örnekle:
Ali = (0.21, 0.88, 0.54)
yemek = (0.65, 0.12, 0.33)
açtı = (0.77, 0.44, 0.91)
Gerçekte bu değerler yüzlerce boyuttan oluşur ama mantık bu.
Daha basitleştirerek düşünürsek:
Ali = Canlılık (0.9), Boyut (0.5)
Yemek = Canlılık (0.4), Boyut (0.2)
Yedi = Canlılık (0.3), Boyut (0.2)
Açtı = Canlılık (0.8), Boyut (0.4)
Bu sayılar tamamen örnek ama model zamanla şunu öğrenir:
hangi kelime hangi tür şeylerle birlikte kullanılır, hangisi canlı, hangisi nesne, hangisi durum vs.
Embeddings'in önemli özelliklerinden biri de benzer kelimelerin birbirine yakın konumlanmasıdır.
Mesela:
"kedi" ile "köpek" birbirine yakın olur
"kedi" ile "araba" daha uzak olur
Hatta eğer konuyu farklı bir çok kaynaktan incelerseniz aşağıdaki örneği bir çok yerde göreceksiniz:
"kral - erkek + kadın ≈ kraliçe" (Kral kavramından erkeği çıkartıp kadın eklediğimizde kraliçe sonucuna varıyoruz)
Bu tamamen vektör matematiği ile olur.
Ama burada önemli bir nokta var:
Yapay zekalar kelimelerin anlamını insanlar gibi gerçekten anlamaz.
Sadece hangi kelimenin hangi kelimeyle birlikte kullanıldığını çok iyi öğrenir.
Yani "açlık" hissinin ne olduğunu bilmez ama "açlık" kelimesinin hangi cümlelerde geçtiğini bilir.
Şimdiye kadar anlattığımız kısım işin temel mantığı. Ama modern LLM'ler sadece kelime tahmini yapan sistemler değil.
Burada devreye Transformer mimarisi girer.
Transformer'ın en önemli olayı attention mekanizmasıdır.
Bu mekanizma sayesinde model cümledeki tüm kelimeler arasındaki ilişkiyi aynı anda değerlendirebilir.
Örnek:
"Ali, Ayşe'ye kitabı verdi çünkü o çok nazikti"
Buradaki "o" kim?
Model bunu çözmeye çalışır:
Ali mi nazik
Ayşe mi nazik
Attention sayesinde kelimeler arasındaki ilişkileri kurarak doğruya yakın tahmin yapar.
Bu özellik eski yapay zeka sistemlerinde yoktu ve LLM'leri güçlü yapan şeylerden biri bu.
Kısaca toparlamak gerekirse:
LLM = gelişmiş kelime tahmin sistemi
Embeddings = kelimelerin sayısal hali
Eğitim = sürekli tahmin yapıp hatayı düzeltme süreci
Transformer = bağlamı anlamayı sağlayan yapı
Attention = kelimeler arası ilişki kurma sistemi
Bu sistemler bilinçli değil düşündüklerini sanmazlar hissetmezler. Ama çok büyük veri sayesinde insana oldukça doğal gelen metinler üretebilirler. Bu yüzden genelde kullanıcılar ki buna bende dahilim mimariyi tam olarak bilmediği zaman bilinçsiz olarak karşısındakine bir insanmış gibi veya inanılmaz zeki bir sistemmiş gibi güvenebilip, inanabilip, şaşırabiliyor Evet sistem oldukça zekice ama bu veriler yokluktan gelen yada baştan icat edilmiş veriler kesinlikle değil yapay zekaların ürettiği her sonuç aslında birer mükemmelleştirilmiş kelime tahmini sisteminin birer sonucudur.
Ben konuyu burada bitiriyorum fakat yanlış anlaşılmasın bu konu, yapay zeka konusunun yalnızca temel'i hatta belkide temel anlatım bile sayılamaz yalnızca insanların kafasında bir fikir oluşmasını sağlayacak bir yazı olmuştur.. Detaya inmek isteyen arkadaşlar için birkaç kaynak bırakıyorum;
LLM Serisi
Farklı Bir LLM Serisi
İngilizce;
Stanford
OpenAI'ın kurucu ekibinde yer alan "Andrej Karpathy"ın Bir videosu

