



Web Crawler nedir?
Gelişen teknolojinin insanlığa sunduğu en iyi şey hiç kuşkusuz ki internet ağıdır. İnternet sayesinde, yalnızca bir tıkla tüm dünya parmaklarınızın ucuna kadar gelebiliyor. Bu bilgi ve veri akışını sağlayan yegane sistemler, elbette web tarayıcılarıdır. Web tarayıcıları kullanıcılar ile bilgi arasında köprü görevinde bulunan bir mekanizmadır.İçerisinde barındırdığı farklı algoritmalarla birlikte kullanıcıların erişim sağlamak istedikleri bilgilere en doğru ve en kolay şekilde ulaşmalarına yardımcı olmaktadır.
√ Taramanın değiştirilebilmesi, yavaş ilerlemek anlamına gelmektedir. hedefe yönelik bir hedefe, amaca ulaşmak için yapılan bir takım işlemleridir.

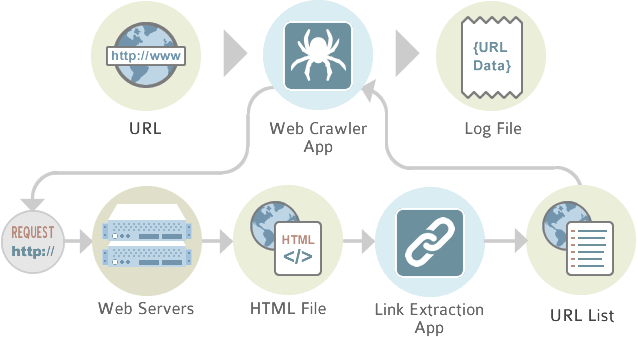
Nasıl Ortaya Çıktı?
Web tarayıcısı arama motorlarının doğuşu ile beraberliği ortaya çıktı. Arama motorlarının internet üzerinden linkleri toplayıp, indeksleyip, insanların özelliklerini doğru ve hızlı bir şekilde erişmesini amaçlamışlar. kısaca linkleri izlemek ve bilgi toplamak amacıyla ortaya çıkıyor.

Crawler Örnekleri
Bugüne kadar kullandığınız tüm arama motorlarının ardında bir crawler çalışmaktadır. Örneğin, kullanıcılar arasında en popüler arama motoru Google’ın crawlerı Googlebot’tur. Buna ek olarak Google Görseller, Videolar, Haberler ve Ads için de botlar bulunmaktadır.
Bunların dışında karşılaşabileceğiniz birkaç crawler:
✓ YandexBot
✓ BingBot (MSNBot-Media, BingPreview gibi daha spesifik botlara da sahiptir.)
✓ DuckDuckBot
✓ BaiduBot
✓ Sogou Spider
✓ Alexa Crawler
✓ ExaBot
✓ Slurp (Yahoo için)
Crawler Örnekleri
Bugüne kadar kullandığınız tüm arama motorlarının ardında bir crawler çalışmaktadır. Örneğin, kullanıcılar arasında en popüler arama motoru Google’ın crawlerı Googlebot’tur. Buna ek olarak Google Görseller, Videolar, Haberler ve Ads için de botlar bulunmaktadır.
Bunların dışında karşılaşabileceğiniz birkaç crawler:
✓ YandexBot
✓ BingBot (MSNBot-Media, BingPreview gibi daha spesifik botlara da sahiptir.)
✓ DuckDuckBot
✓ BaiduBot
✓ Sogou Spider
✓ Alexa Crawler
✓ ExaBot
✓ Slurp (Yahoo için)
Crawler Nedir? SEO için Neden Önemlidir?
SEO (Search Engine Optimization), herhangi bir web sitesinin SERP’lerde daha yüksek sıralamalar elde etmesi için göz önünde bulundurması gereken en önemli faktördür. Bunu sağlayabilmek için sitenizde yer alan içeriklerin kaliteli ve okunabilir olması gerekmekte, bunun yanı sıra sitenizde bu anlamda iyileştirmeler de yapmak durumundasınız.
Arama motorlarının gerçekleştirdiği tarama işlemleri, sitenizdeki içeriklere odaklanılmasının ilk aşamasıdır. Düzenli olarak gerçekleştirilen tarama, siteniz üzerinde yapılan değişikliklerin tespit edilebilmesine ve içeriklerinizin SERP’lerde görüntülenmesine yardımcı olmaktadır. Ancak Google ve diğer arama motorları sınırsız tarama hakkı sunmamaktadır.
Bu noktada arama motorlarının her site için zamansal tarama sınırı ve tarama bütçesi vardır. Webmasterlar, bu tarama bütçesini daha etkin bir şekilde kullanabilmek adına web sitesini arama motoruna uygun bir şekilde optimize etmelidir. SEO bu nedenle web siteleri için oldukça önemlidir.
Botlar, çok sayıda ziyaretçinin uğradığı güvenli gördüğü bağlantıları daha sık taramaktadır. Webmasterlar bunun tespitini ve kontrolünü sağlayabilmek için, Robots.txt dosyası ve XML site haritası gibi çeşitli metotlar kullanmaktadır.
Robot.Txt dosyaları; arama motoru crawlerlarının bir sayfada hangi alanı tarayıp tarayamayacağına dair talimat verebileceğiniz araçlardır.
XML site haritaları; bir web sitesinin önemli sayfalarını listeleyip, arama motorunun siteye dair yapıyı anlamasına yardımcı olan araçlardır.


Scrapy Nedir?
Web içeriklerini kolaylıkla ve hızlıca tarayabilmemizi sağlayan gelişmiş bir frameworktur diyebiliriz.
Scrapy Kurulumu 
- Sanal ortamımızı oluşturalım. Scrapy paketimizi python paket yöneticisi ile yükleyelim.

- Eğer yükleme başarılı olduysa scrapy yazdığınızda kullanabileceğiniz komutlar yukarıda ki gibi ekrana gelecektir.
- Scrapy kurduk ve artık bir proje oluşturup kodumuzu yazmamız gerekiyor. Scrapy çok geniş bir yapıya sahip olduğu için herşeyi burada anlatmamız çok güç olur. Bu yüzden bir tane web sitesi seçelim ve site üzerinde ki linkleri toplayalım.

Planlama
- Hedef siteyi belirle
- Sitenin robots.txt gözden geçir
- Scrapy komutları ile projemizi oluştur
- Modelin varsa items.py içine tanımla
- Spider oluştur
- Settings dosyasını düzenle
- Çalıştır ve dataları al.
1. Hedef siteyi belirle
(Example Domain)
2. Sitenin robots.txt gözden geçir
(https://example.com/robots.txt)3. Scrapy projesini oluşt
ur.


4. Modelimizi items.py içine tanımlayacağız.
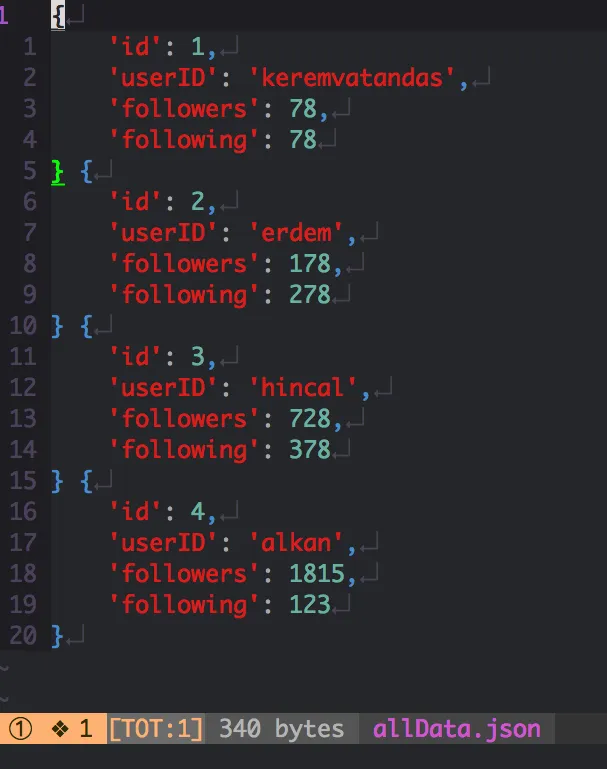
- Modelden kastımız siteyi gezerken, site içerisinden alacağımız verilerin yazılacağı kolonlar gibi düşünebilirsiniz. Biz user isimlerini alalım ve aynı zamanda kaç kişiyi takip ediyorlar, kaç kişi tarafından takip ediliyorlar bilgilerini alalım. Şimdi nasıl olmuş oldu userID, following, followers .. Çıktı olarak json data istiyorum. Tabi siz farklı şekilde çıktılar alabilirsiniz. Database yazabilirsiniz, json, csv olarak alabilirsiniz gibi… Bunun içinde ayrı geliştirme yapmanız gerekiyor.
5. Spider oluştur.
Kod:
# scrapy genspider SpiderIsmi hedefSite — template=crawl
Kod:
(scrapyTest) ☁ example ls example/spiders
__init__.py __pycache__ example_spider.py- Şimdi spiderımız oluşturuldu.
- spider dizini altında example_spider.py isminde python dosyamızı oluşturdu. Biz bunu kendimiz de oluşturabilirdik. Sadece scrapy komutlarını nasıl kullandığımızı da görmenizi istediğim için yaptım. Biz spider kodumuzu kendimize uygun şekilde yazacağız. Spider yazmadan önce miras alacağınız yapıların dökümanlarına bakmak mantıklı olacaktır. Ekstra bir iş yapmamanız açısından sizin içinde zaman kaybı olmamız olur.
Spider kodumuz
Kod:
# -*- coding: utf-8 -*-
from scrapy import Request
from scrapy.spiders import SitemapSpider
from example.items import ExampleItem
class ExampleSpiderSpider(SitemapSpider):
# Spider ismi -> calistirirken bu ismi kullanacagiz (settings)
name = 'example-spider'
allowed_domains = ['example.com']
# start_urls - Robots.txt kontrol ettikten sonra Sitemap
start_urls = ['http://example.com/']
# sitemap icinde belirli url ayiklamak icin rules yazalim
# /birseyler buldugu linkeri parse fonksiyonuna yollayacak
sitemap_rules = [("/birseyler", "parse")]
def parse(self, response):
# Sitenin yapisina gore parse edelim
# Clean url seklinde alip parse_detail isimli fonksiyona gonderelim
if 'bulunamadi' not in response.body:
# ... filtreler
# ... xpath / css / selector vs kullanimlari
for page in pages:
# ...
# callback function onemli
# parse_detail de istenilen datalari parse edecegiz
yield Request(url=response.url,
callback=self.parse_detail)
# Sayfa paginate mantiginda olabilir
next_page = response.xpath('//filtreleme')
if next_page:
# Bir sonraki sayfayi tekrardan parse kendine gonderecek
yield Request(response.url, callback=self.parse)
else:
return
def parse_detail(self, response):
# Modelimizi kullanalim
item = ExampleItem()
item['id'] = get_id()
item['userID'] = get_userID()
item['followers'] = get_followers()
item['following'] = get_following()
yield item- Burada bir prototip oluşturduk. SitemapSpider kullandık. Dokümantasyonu okuyarak amaca uygun bir yapıyı kullanmak çok önemli.
- Biz sitemap.xml dosyasından yola çıkarak sitemap_rules içinde kuralımızı belirttik ve tüm sitemap.xml işleyerek bizim kurallarımıza göre dataları alıp, oluşturduğumuz model yapısını kullanarak dışarıya json, csv data aktarabilir yada direk olarak bir database insert edebiliriz.
- parse_detail fonksiyonu içerisinde ki get_id() get_userID() gibi fonksiyonlar ExampleSpiderSpider class içerisinde olacaktır. Burada prototip bir uygulama yazdık. Ama pratikte yapacağınızla birebir aynı olacak.
6. Settings dosyasını düzenleyelim.

- Settings dosyasından çok fazla ayar var.
- Bizim için önemli olanlardan bazıları Concurrent_Requests sayımızı abartmamak. User-Agent kullanmak, Download_Delay 1–3sn arası vermek, Proxy kullanmak gibi…
Settings Doc -> Settings — Scrapy 2.10.0 documentation
7. Çalıştır ve dataları al
Genel olarak yapı böyle. Tabiki de bu sadece SitemapSpider kullanımı için. Dökümantasyonu okuyarak daha fazla bilgi edinebilir, crawler yazabilirsiniz. Eğer takıldığınız, sormak istediğiniz bölümler var ise sorabilirsiniz. Redis, Rethinkdb gibi entegrasyonlar yapacaksanız öncelikle pipeline kısmında bir geliştirme yapmanız gerekecektir. Daha sonra settings kısmını düzenlemeniz yetecektir. Kendiniz proxy yazacaksanız middleware dosyasının içine yazabilirsiniz.
Aşağıda bıraktığım videolardan konuyu daha iyi anlayabilirsiniz.


Evet konumuz bu kadardı okuduğunuz için teşekkür ederim.
Allta bıraktığım linklerden daha önce açtığım konulara bakabilirsiniz.
 www.turkhackteam.org
www.turkhackteam.org
www.turkhackteam.org
www.turkhackteam.org
İyi forumlar.

7. Çalıştır ve dataları al
Kod:
scrapy crawl SpiderIsmi -o OutputIsmi.jsonGenel olarak yapı böyle. Tabiki de bu sadece SitemapSpider kullanımı için. Dökümantasyonu okuyarak daha fazla bilgi edinebilir, crawler yazabilirsiniz. Eğer takıldığınız, sormak istediğiniz bölümler var ise sorabilirsiniz. Redis, Rethinkdb gibi entegrasyonlar yapacaksanız öncelikle pipeline kısmında bir geliştirme yapmanız gerekecektir. Daha sonra settings kısmını düzenlemeniz yetecektir. Kendiniz proxy yazacaksanız middleware dosyasının içine yazabilirsiniz.
Aşağıda bıraktığım videolardan konuyu daha iyi anlayabilirsiniz.
Evet konumuz bu kadardı okuduğunuz için teşekkür ederim.
Allta bıraktığım linklerden daha önce açtığım konulara bakabilirsiniz.
Access Control Lists Nedir? Nasıl yapılır?
Access Control List (ACL) Nedir? Erişim Kontrol Listesi (Access Control List) uygulamadaki kullanıcıların yetkilendirme kayıtlarını içeren listedir. Bu liste içerisinde kullanıcının erişim yetkilerini tanımlarız ve sonrasında ilgili yerlerde bu kontrolleri sağlayarak kullanıcının yalnızca...
www.turkhackteam.org
Wordlist Nedir? Wordlist Generator ve Wordlist Oluşturma
Wordlist Nedir ? İçerisinde birçok farklı sözcük ve şifre kombinasyonunu barındıran kelime listesidir. Bu kelime listeleri şifre kırmaya yönelik saldırılarda kullanılarak kullanıcıların şifrelerini ele geçirmeye yardımcı olur. Wordlist dosyaları genellikle şifre için yapılan saldırılarda ve...
www.turkhackteam.org
Trafik ışıkları nasıl hacklenir?
Trafik ışıkları nasıl hacklenir Şimdi gelelim bu ışıklar nasıl hacklenir. Bu trafik ışıklarındaki sistem her bir kavşaktaki koşullara göre değişen 5.8 GHZ ve 900 MHz radyo sinyallerini kullanıyor. Elimize bir laptop ve trafik ışıklarının kullandığı aynı frekansta çalışan (5.8 Ghz) wireless...
www.turkhackteam.org
İyi forumlar.



")

