


Merhaba dostlarım,bu makalemde sizlere "Makine öğrenmesi (ML)" alanında karşımıza çıkan ve oldukça popüler olan modelleri,algoritmaları anlatacağım. Bu makale bir devam makalesi olduğundan, konuyu daha iyi anlayabilmek için önceki makalelerimi, "Supervised ML" ve "Unsupervised ML", incelemenizi tavsiye ediyorum. Bu bakalede ise serinin sonuncusu olan ve sizlerin daha dikkatini çekeceğini düşündüğüm "Reinforcement ML" kavramına değineceğiz. Ayrıca yine makaledeki algoritmalara "Python3" kullanarak örnekler vereceğim ve bu kodları inceleyeceğiz. Foruma katkısı ve bu alanda çalışacak arkadaşlara faydalı olması dileğiyle diyerek başlamak istiyorum.
İyi okumalar.
|
|
v
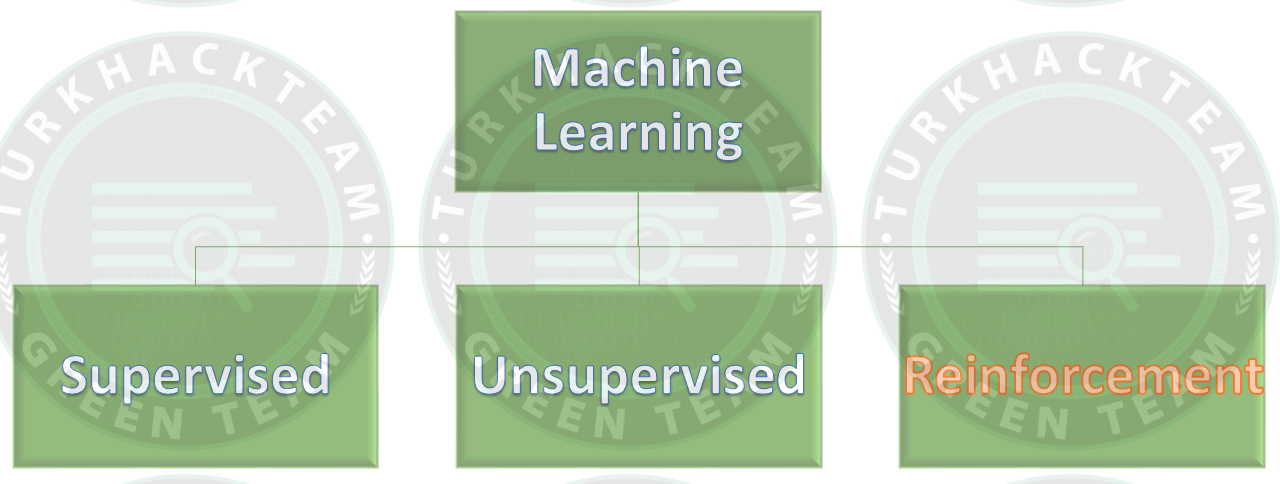
Makine öğrenmesi (ML) nedir? | Önemi | Çalışma mantığı | Denetimli öğrenme | Denetimsiz öğrenme | Avantaj&Dezavantaj
||
V
Machine Learning Models #1 | Machine Learning Models #2


Pekiştirmeli (Reinforcement) öğrenme nedir?

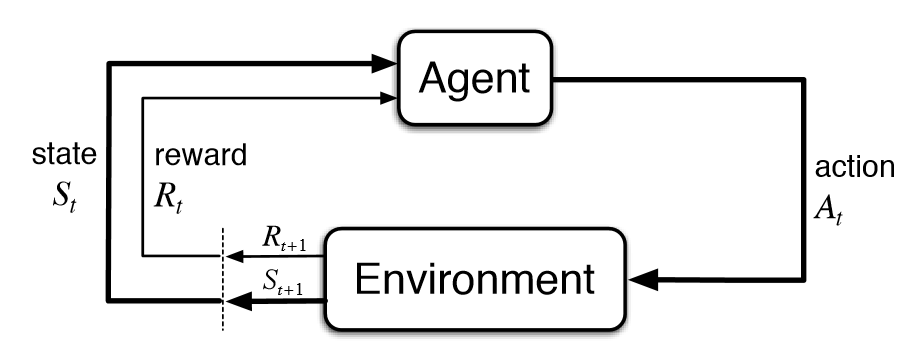
Pekiştirmeli (Reinforcement) öğrenme (RL); bir modelin kendi eylemlerinden ve deneyimlerinden edindiği verileri kullanarak, deneme yanılma yöntemi ile öğrenmesini sağlayan bir Makine öğrenimi (ML) tekniğidir.
Model, karmaşık veya belirsiz bir ortamda belirlenen hedefe ulaşmayı öğrenir. Model çevresini algılayabilir ve yorumlayabilir, eyleme geçebilir ve hedefe ulaşabilir. Tabi burada modelin yaptığı her bir eylemin bir geri dönüşü olduğunu söylemeliyim. Bir nevi “Ödül / Ceza” ilişkisi var aslında. Model, yaptığı her başarılı eylem için olumlu geri bildirim alırken her başarısız eylemde ise olumsuz geri bildirim alır.
Denetimli öğrenmenin aksine bu teknikte model, hiçbir etiketlenmiş veri olmadan sadece kendi geri bildirimleri ile öğrenimini sürdürür.
Denetimsiz öğrenmeden farkı ise, modelin amacı veriler arasındaki farklardan yola çıkarak hedefe ulaşmak değil mümkün olan en yüksek ödül puanına ulaşmaktır. Model, hedefe ulaşmak için maksimum başarılı adımı atmalıdır.
Programcı; ödül politikasını, kuralları koymasına rağmen modele, çözüme gidecek bir ip ucu vermez. Model, tamamen rastgele denemeler, değişik taktiktler ve hızlı hesaplama becerileri ile hedefe ulaşmaya çalışır. Bu yöntem, modelin yaratıcılık özelliğini inşa etmede en etkili yoldur. Yeterince güçlü bilgisayar alt yapısına sahip bir model, insan üstü hesaplamalar yapabilir ve insanlara karşı oyunlar kazanabilir.
Burada hiçbir insan müdahalesi olmadan bir makinenin öğrenmesi ve oyunu kazanmasından bahsediyoruz.
Sizce yapay zekanın bu kadar ileri gitmesi iyi mi, yoksa kötü mü?
Temel terimler
Pekiştirmeli öğrenmenin (RL) temel terimlerine bakalım;
Agent (Temsilci/Etken); Çevreyi algılayabilen,anlamlandırabilen,keşfedebilen ve ona göre hareket edebilen varlık.
Environment (Çevre); Temsilcinin faaliyet gösterdiği etki ortamı.
State (Durum/Hal); Temsilcinin her eyleminden sonra döndürülen temsilci durumu.
Reward (Ödül); Çevreden temsilciye döndürülen geri bildirim.
Policy (İlke); Temsilcinin durumunu eylemler ile eşleştirme yöntemi.
Deterministik politika için: a = π(s)
Stokastik politika için: π(a | s) = P[At =a | St = s]
Value (Değer); Ödülden farklı olarak, temsilcinin belirli bir durumda gerçekleştireceği eylemde alacağı gelecekteki ödül.


PacMan örneği;
RL konusunu anlatırken bir örnek vererek anlatımı güçlendireyim.
Bir “PacMan” oyununu düşünün. PacMan burada “Agent”, üzerinde bulunduğu dünya “Environment”, PacMan’in mevcut durumu “State”, yoldaki yiyecekleri yemesi ve hayaletlerden kaçması “Policy” ve tüm yiyecekleri yakalanmadan yemesi ve oyunu kazanması ise “Value” değerleridir diyebilirim.
Pekiştirmeli öğrenmenin (RL) ana noktaları;
Input (Girdi); Modelin başlangıç durumunu belirler.
Output (Çıktı); Problemin çözümünü belirtir. Bir problem için çeşitli çözümler olduğundan, birden fazla çıktı da olabilir.
Learning (Eğitim); Girdiye dayalı bir modelin durumunu döndürür ve belirlenen çıktıya göre modeli ödüllendirir yada cezalandırır.
Türleri & Kullanım alanları
Pekiştirmeli öğrenmenin (RL) iki farklı türü vardır. Bunlar;
Pozitif:
Olumlu pekiştirme; Belirli bir eylem nedeni ile bir olayın meydana gelmesi, eylemin kuvvetini ve sıklığını artırması olarak tanımlanabilir.
Performansı En Üst Düzeye Çıkarır
Değişimi uzun süre sürdürür
Çok fazla Güçlendirme, sonuçları azaltabilecek durumların aşırı yüklenmesine neden olabilir.
Negatif:
Olumsuz pekiştirme; Olumsuz bir durum durdurulduğunda veya olumsuz durumdan kaçınıldığında, davranışı güçlendirmesi olarak tanımlanabilir.
Davranışı Artırır
Asgari performans standardına meydan okuma sağlamaktadır
Yalnızca minimum davranışı karşılamaya yetecek kadarını sağlar
Kullanım alanları;
Robotik: Robot navigasyonunda, Robo-futbolda, yürümede, dans etmede vb. alanlarda kullanılır
Kontrol: Fabrika süreçleri, telekomünikasyonda kabul kontrolü gibi uyarlanabilir kontrol için kullanılabilir. Helikopter pilotu, pekiştirmeli öğrenmeye bir örnektir.
Oyun: Tic-tac-toe, satranç, dama, bilardo vb. oyunlarda kullanılabilir.
Kimya: kimyasal reaksiyonları optimize etmek için kullanılabilir.
İşletme: iş stratejisi planlaması için kullanılabilir.
Üretim: Çeşitli otomobil imalat şirketlerinde robotlarların iş hareketlerini öğrenmesinde kullanılabilir.
Finans: Finans sektöründe ticaret stratejilerini değerlendirmek için kullanılabilir.
Sırada algoritma bölümümüz var dostlarım.
Pekiştirmeli öğrenim (RL) tekniğinde en çok kullanılan algoritmalar şunlardır;
Q-Learning Algorithm | SARSA (State Action Reward State action) | DQN (Deep Q Network)
Bu algoritmaların ne işe yaradığına gelin daha yakından bakalım...

Q-Learning Algoritması nedir?
Q-Learning algoritması, mevcut durumda yapılabilecek en iyi eylemi bulmaya çalışan ilke dışı bir RL algoritmasıdır. İlke dışı olarak tanımlanmasının sebebi; bu algoritmanın rastgele eylem ilkesine uymaması ve farklı tür öğrenimler uygulamasıdır. Kısacası bu algoritma bir ilkeye ihtiyaç duymaz.
Q-Learning algoritmasının ana amacı, toplam ödül puanını en üst düzeye çıkarmaktır
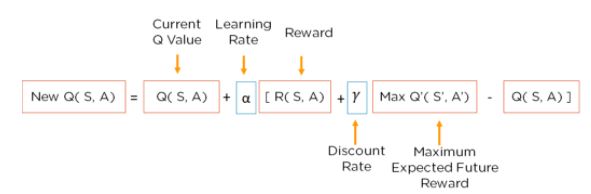
Bellman Denklemi nedir?
Bellman denklemi, belirli durumları analiz etmek ve o durumun eyleme geçirilmesinin ne kadar iyi olacağını hesaplamak için kullanılır. Denklemde, optimal durum en yüksek optimal değeri verir.
Örnek;
Geçek hayat ile ilişkilendirecek bir örnek olması açısından, bir köpeğimizin olduğunu ve ona eğitim verdiğimizi düşünelim. Köpek talimatlara uyar ve hareketi öğrenir ise ödül vereceğiz.
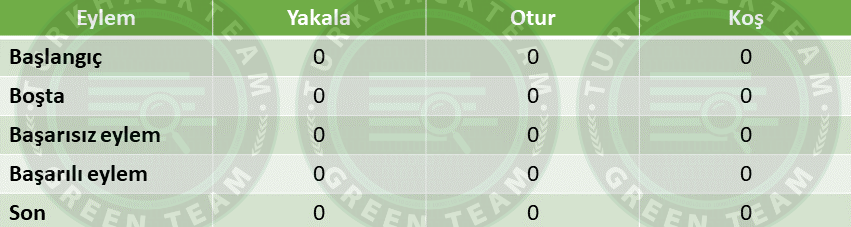
Şimdi, sistemin nasıl çalıştığını tablolar ile anlatayım.
Tüm değerlerin “0 “ olduğu bir tablomuz olsun.
Ardından bir hareket belirleyeceğiz ve bunu hayvanımıza yaptıracağız.
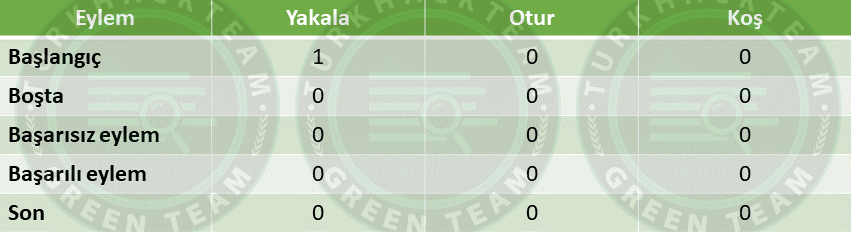
Hareketi seçtiğimizde değerini belirttik. Bu durum “Başlangıç” diğer bir terim ile “Input” adımımızdır.
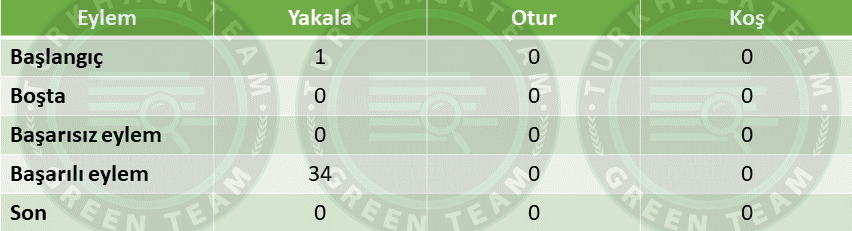
Gerçekleştirilen eylem için ödül değerini aldık ve Bellman denklemini kullanarak “Q-Value” değerini hesapladık.
Gerçekleştirilen değer için asıl ödül değerini, Q(S, A) değerini hesaplamalısınız.
Bu adımı tablo dolana kadar veya bir hareket tamamen dolana kadar tekrar edeceğiz.
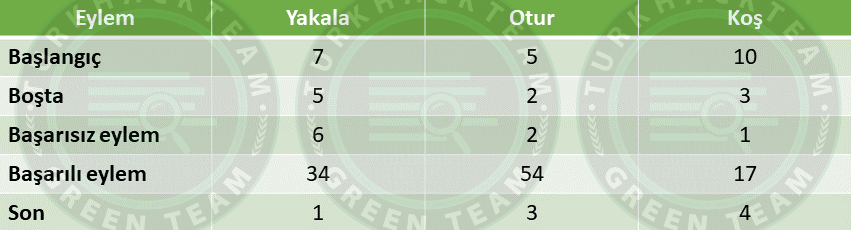
Burada köpeğimiz hareketleri yapmaya devam eder ve her eylem için “Ödül” ve “Q” değerini hesaplarız. Tabloyu güncelleriz.
Formül;
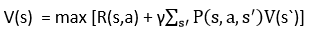
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import gym
import random
env = gym.make("FrozenLake-v1")
action_size = env.action_space.n
state_size = env.observation_space.n
qtable = np.zeros((state_size, action_size))
#print(qtable)
total_episodes = 15000 # Toplam bölüm
learning_rate = 0.8 # Öğrenim oranı
max_steps = 99 # Bölüm başına maksimum adım
gamma = 0.95 # indirim oranı
# Keşif parametreleri
epsilon = 1.0 # Keşif oranı
max_epsilon = 1.0 # Başlangıçta keşif olasılığı
min_epsilon = 0.01 # Minimum keşif olasılığı
decay_rate = 0.005 # Keşif için üstel bozulma oranı
# Ödüllerin listelenmesi
rewards = []
# Yaşam boyu veya öğrenme durdurulana kadar
for episode in range(total_episodes):
# Ortamı sıfırlamak
state = env.reset()
step = 0
done = False
total_rewards = 0
for step in range(max_steps):
# Mevcut dünya durumlarında bir eylem seçilmesi
# Rastgele bir sayının alınması
exp_exp_tradeoff = random.uniform(0, 1)
## If this number > epsilon --> İşleme (bu durum için en büyük Q değeri alınır)
if exp_exp_tradeoff > epsilon:
action = np.argmax(qtable[state, :])
# Else random choice --> Keşif
else:
action = env.action_space.sample()
# Eylemin (a) yapılması, sonuç durumlarının (s) gözlemlenmesi ve ödüllendirme (r)
new_state, reward, done, info = env.step(action)
# UQ(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
qtable[state, action] = qtable[state, action] + learning_rate * (
reward + gamma * np.max(qtable[new_state, :]) - qtable[state, action])
total_rewards += reward
# Yeni durum
state = new_state
if done == True:
break
# Epsilon'u azaltmak
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
rewards.append(total_rewards)
print("Score over time: " + str(sum(rewards) / total_episodes))
print(qtable)
env.reset()
for episode in range(5):
state = env.reset()
step = 0
done = False
print("****************************************************")
print("EPISODE ", episode)
for step in range(max_steps):
# Bu duruma göre maksimum beklenen gelecekteki ödüle sahip eylem (dizin) gerçekleştirilir
action = np.argmax(qtable[state, :])
new_state, reward, done, info = env.step(action)
if done:
# Son durumun yazdırılması.
env.render()
# Atılan adım sayısının yazdırılırması.
print("Number of steps", step)
break
state = new_state
env.close()Çıktı;
SARSA (State Action Reward State Action), ilkeye ve zamansal farka dayalı bir RL algoritmasıdır. İlke içi denetim yöntemi ile, öğrenme aşamasında her bir durum için eylemi seçer
Bu algoritmanın amacı, seçilen ilke (π) ve bütün (S-A) çiftleri için “Q π(S-A)” hesabı yapmaktır.
Q-Learning’den tek farkı, tabloyu güncellemede bir sonraki adım için maksimum ödül puanının gerekmemesidir.
Tanımlar ise şu şekilde;
S: Orijinal durum A: Orijinal eylem R: Durum takibinde gözlemlenen ödül S,A: Yeni durum-eylem çifti
Formül;
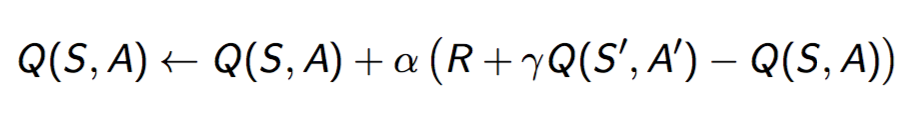
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import numpy as np
import gym
# Çevrenin oluşturulması
env = gym.make('FrozenLake-v1')
# Parametrelerin tanımlanması
epsilon = 0.9
total_episodes = 10000
max_steps = 100
alpha = 0.85
gamma = 0.95
# Q-matrix başlatılması
Q = np.zeros((env.observation_space.n, env.action_space.n))
# Sonraki eylemi seçme işlevi
def choose_action(state):
action=0
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(Q[state, :])
return action
# Q değerini öğrenme işlevi
def update(state, state2, reward, action, action2):
predict = Q[state, action]
target = reward + gamma * Q[state2, action2]
Q[state, action] = Q[state, action] + alpha * (target - predict)
# Ödülün başlatılması
reward = 0
# SARSA öğrenimini başlatma
for episode in range(total_episodes):
t = 0
state1 = env.reset()
action1 = choose_action(state1)
while t < max_steps:
# Eğitimi görselleştirmek
env.render()
# Bir sonraki durumu almak
state2, reward, done, info = env.step(action1)
# Bir sonraki eylemi seçmek
action2 = choose_action(state2)
# Q-değerini öğrenmek
update(state1, state2, reward, action1, action2)
state1 = state2
action1 = action2
# İlgili değerlerin güncellenmesi
t += 1
reward += 1
if done:
break
# Performansın değerlendirilmesi
print ("Performance : ", reward/total_episodes)
# Q matrisini görselleştirme
print(Q)Çıktı;
NOT: GIF'ler çalışmaz ise tekrardan yükleyebilirim.
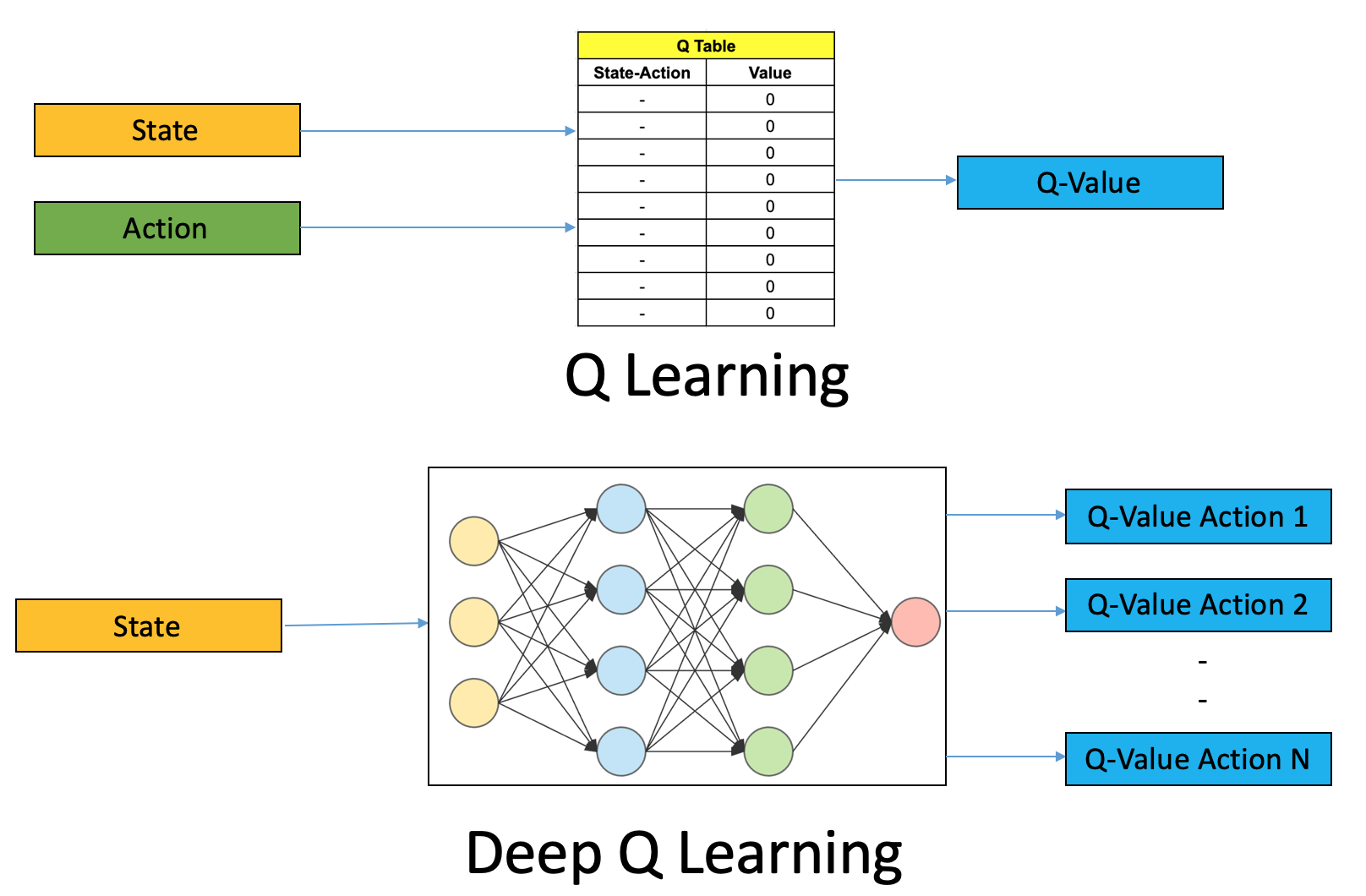
DQN algoritması, sinir ağlarını kullanan bir RL algoritmasıdır.
Algoritma, Q tabloları oluşturma zahmetinden kaçınır, her eylem ve durum için Q değerine yaklaşan sinir ağları kullanır.
Kısa kısa bu kavramları tanımlayacak olursak;
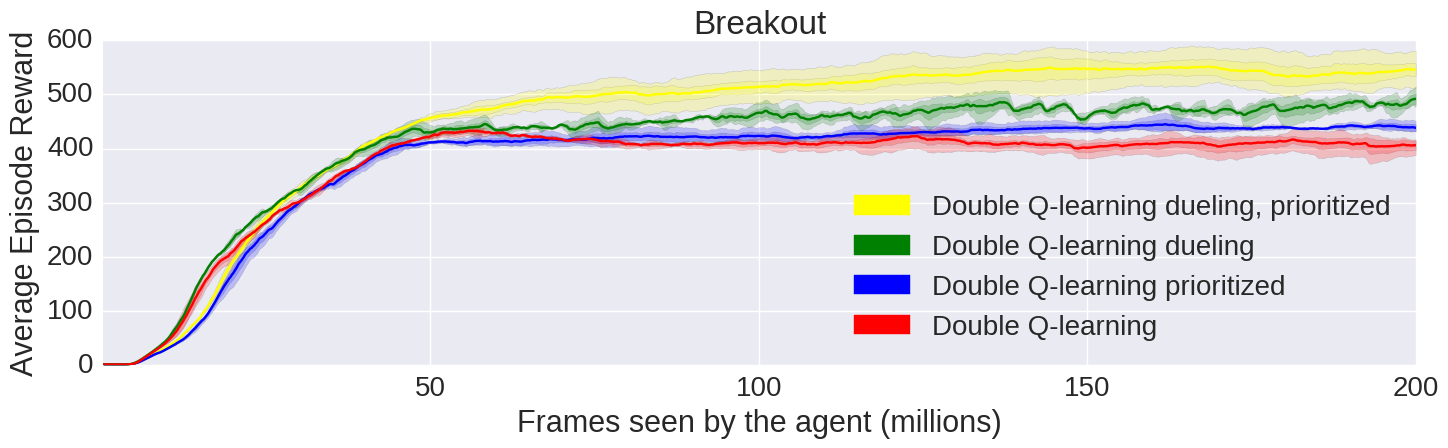
DQN: Pekiştirmeli öğrenmenin video oyunları veya robotik için karmaşık, çok boyutlu alanlarda çalışmasına izin veren, Q-Learning ile sinir ağlarını birleştiren bir RL algoritmasıdır.
Double Q-Learning: DQN algoritmasının belirli eylemlere bağlı değerleri fazla tahmin etme problemini düzeltir.
Priority Playback: Ödülün beklenen ödülden hemen hemen ayrıldığı zamanları yeniden oynatarak DQN algoritmasının yeniden oynatma kabiliyetini geliştirir ve yanlış varsayıma karşı modelin kendini ayarlamasını sağlar.
Duel DQN: Eylemi; biri her adımda değeri tahmin etmeye çalışan, diğeri ise her bir eylemin potansiyel avantajlarını hesaplayan iki parçaya böler.
Formül;
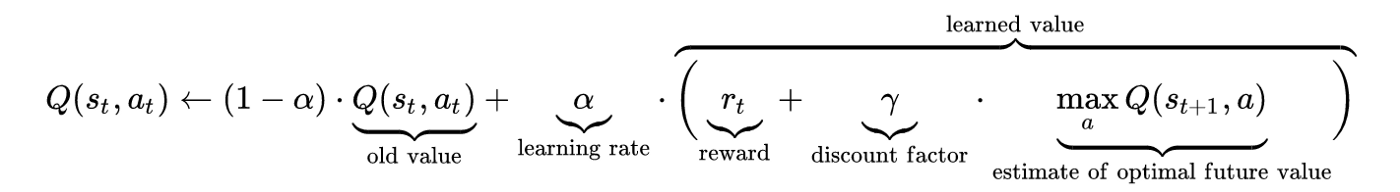
Python3 örneği;
Python:
# Gerekli kütüphanelerin içeri alınması
import gym
import math
import random
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import count
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
env = gym.make('CartPole-v1').unwrapped
# Matplotlib kurulumu
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
plt.ion()
# GPU aktifliği
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Transition = namedtuple('Transition',
('state', 'action', 'next_state', 'reward'))
class ReplayMemory(object):
def __init__(self, capacity):
self.memory = deque([],maxlen=capacity)
def push(self, *args):
self.memory.append(Transition(*args))
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
class DQN(nn.Module):
def __init__(self, h, w, outputs):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(32)
# Doğrusal giriş bağlantılarının sayısı, conv2d katmanlarının çıkışına ve dolayısıyla giriş görüntüsünün boyutuna bağlıdır.
# Bu durumun hesaplanması
def conv2d_size_out(size, kernel_size = 5, stride = 2):
return (size - (kernel_size - 1) - 1) // stride + 1
convw = conv2d_size_out(conv2d_size_out(conv2d_size_out(w)))
convh = conv2d_size_out(conv2d_size_out(conv2d_size_out(h)))
linear_input_size = convw * convh * 32
self.head = nn.Linear(linear_input_size, outputs)
# Sonraki eylemi belirlemek için bir öğeyle veya optimizasyon sırasında bir toplu iş ile çağrılır.
def forward(self, x):
x = x.to(device)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
return self.head(x.view(x.size(0), -1))
resize = T.Compose([T.ToPILImage(),
T.Resize(40, interpolation=Image.CUBIC),
T.ToTensor()])
def get_cart_location(screen_width):
world_width = env.x_threshold * 2
scale = screen_width / world_width
# Orta
return int(env.state[0] * scale + screen_width / 2.0)
def get_screen():
# Tavsiye edilen ekran 400x600x3'tür. Ancak bazen daha büyük olabilir.
screen = env.render(mode='rgb_array').transpose((2, 0, 1))
# Sepetin konumu
_, screen_height, screen_width = screen.shape
screen = screen[:, int(screen_height*0.4):int(screen_height * 0.8)]
view_width = int(screen_width * 0.6)
cart_location = get_cart_location(screen_width)
if cart_location < view_width // 2:
slice_range = slice(view_width)
elif cart_location > (screen_width - view_width // 2):
slice_range = slice(-view_width, None)
else:
slice_range = slice(cart_location - view_width // 2,
cart_location + view_width // 2)
screen = screen[:, :, slice_range]
screen = np.ascontiguousarray(screen, dtype=np.float32) / 255
screen = torch.from_numpy(screen)
return resize(screen).unsqueeze(0)
env.reset()
plt.figure()
plt.imshow(get_screen().cpu().squeeze(0).permute(1, 2, 0).numpy(),
interpolation='none')
plt.title('Example extracted screen')
#plt.show()
BATCH_SIZE = 128
GAMMA = 0.999
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 200
TARGET_UPDATE = 10
# AI spor salonundan döndürülen şekle göre katmanları doğru şekilde başlatılabilmesi için ekran boyutunun alınması. Bu noktada tipik boyutlar 3x40x90'a yakındır.
# Bu, get_screen() içindeki sıkıştırılmış ve küçültülmüş bir oluşturma arabelleğinin sonucudur
init_screen = get_screen()
_, _, screen_height, screen_width = init_screen.shape
# gym eylem alanından eylem sayısını alınması
n_actions = env.action_space.n
policy_net = DQN(screen_height, screen_width, n_actions).to(device)
target_net = DQN(screen_height, screen_width, n_actions).to(device)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval()
optimizer = optim.RMSprop(policy_net.parameters())
memory = ReplayMemory(10000)
steps_done = 0
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
# t.max(1) her satırın en büyük sütun değerini döndürür.
# Maksimum sonuçtaki ikinci sütun, maksimum öğenin bulunduğu dizindir.
# Bu yüzden daha büyük beklenen ödülle eylem seçilir.
return policy_net(state).max(1)[1].view(1, 1)
else:
return torch.tensor([[random.randrange(n_actions)]], device=device, dtype=torch.long)
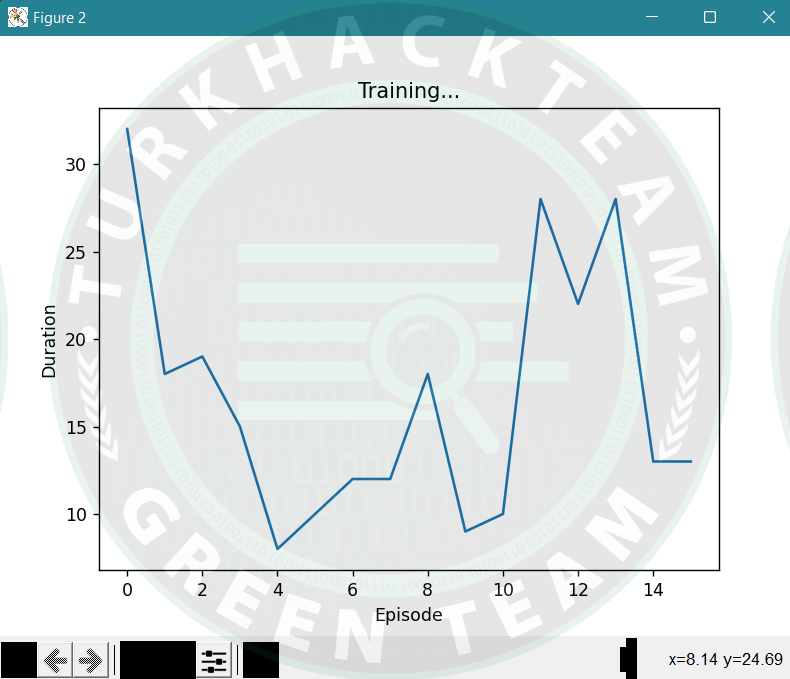
episode_durations = []
def plot_durations():
plt.figure(2)
plt.clf()
durations_t = torch.tensor(episode_durations, dtype=torch.float)
plt.title('Training...')
plt.xlabel('Episode')
plt.ylabel('Duration')
plt.plot(durations_t.numpy())
# 100 bölüm ortalamasını alınır
if len(durations_t) >= 100:
means = durations_t.unfold(0, 100, 1).mean(1).view(-1)
means = torch.cat((torch.zeros(99), means))
plt.plot(means.numpy())
# Çevrenin güncellenmesi için mola verilmesi
plt.pause(0.001)
if is_ipython:
display.clear_output(wait=True)
display.display(plt.gcf())
def optimize_model():
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
# Nihai olmayan durumların maskesinin hesaplanması ve toplu iş öğelerini birleştirilmesi
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,
batch.next_state)), device=device, dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state
if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
# Q(s_t, a)
state_action_values = policy_net(state_batch).gather(1, action_batch)
# V(s_{t+1})
next_state_values = torch.zeros(BATCH_SIZE, device=device)
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0].detach()
# Beklenen Q değerlerini hesaplanması
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
# Huber kaybının hesaplanması
criterion = nn.SmoothL1Loss()
loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))
# Model optimizasyonu
optimizer.zero_grad()
loss.backward()
for param in policy_net.parameters():
param.grad.data.clamp_(-1, 1)
optimizer.step()
num_episodes = 50
for i_episode in range(num_episodes):
# Çevre ve durumun başlatılması
env.reset()
last_screen = get_screen()
current_screen = get_screen()
state = current_screen - last_screen
for t in count():
# Eylemin seçilmesi ve gerçekleştirilmesi
action = select_action(state)
_, reward, done, _ = env.step(action.item())
reward = torch.tensor([reward], device=device)
# Yeni durumun gözlemlenmesi
last_screen = current_screen
current_screen = get_screen()
if not done:
next_state = current_screen - last_screen
else:
next_state = None
# Geçişi bellekte saklanması
memory.push(state, action, next_state, reward)
# Diğer duruma hareket edilmesi
state = next_state
# Optimizasyonun bir adımının gerçekleştirilmesi
optimize_model()
if done:
episode_durations.append(t + 1)
plot_durations()
break
# DQN'deki tüm ağırlıkları ve önyargıları kopyalayarak hedef ağın güncellenmesi
if i_episode % TARGET_UPDATE == 0:
target_net.load_state_dict(policy_net.state_dict())
print('Complete')
env.render()
env.close()
plt.ioff()
plt.show()Çıktı;
Avantaj & Dezavantaj
Pekiştirmeli (Reinforcement) öğrenmenin bazı avantajları şunlardır;
Pekiştirmeli öğrenme, geleneksel tekniklerle çözülemeyen karmaşık problemleri çözmek için kullanılır.
Bu teknik, elde edilmesi oldukça zor olan ve uzun vadeli sonuçlara ulaşmak için tercih edilir.
Bu öğrenme modeli, insanın öğrenmesine çok benzer. Bu nedenle, mükemmele ulaşmaya yakındır.
Pekiştirmeli (Reinforcement) öğrenmenin bazı dezavantajları şunlardır;
Çok fazla pekiştirmeli öğrenme işlemleri, sonuçları azaltabilecek durumların aşırı yüklenmesine yol açabilir.
Bu öğrenme tekniği, basit problemlerin çözümü için tercih edilmez.
Bu tekniğin algoritmaları çok fazla veriye ve çok fazla hesaplamaya ihtiyaç duyar.
Boyutluluk laneti, gerçek fiziksel sistemler için pekiştirmeli öğrenmeyi sınırlar.
Supervised VS Reinforcement

Son olarak, ilginizi çekebilecek harika "Reinforcement Learning" uygulamaları, oyunları, projeleri bulabileceğiniz bir site bırakıyorum.
Bir gezip dolaşmanızda fayda var
")
>> PROJECTs <<
^
|
|
|
|
v
Değerli dostlarım, güzel kardeşlerim;
Bu makalemde kısaca "Makine öğrenmesi modelleri" konusuna değindim.
Ardından "En popüler algoritmalar" konusunda örnekler yaptık.
Kaynak niteliğinde bu forumda kalması temennisi ile diyerek sözlerimi bitiriyorum.
Sağlıcakla kalın.

Son düzenleme:


